Se ha dicho que la buena escritura proviene de la edición. Afortunadamente para los lectores exigentes de todo el mundo, Microsoft está poniendo un editor de gramática con tecnología de inteligencia artificial al alcance de millones de personas.
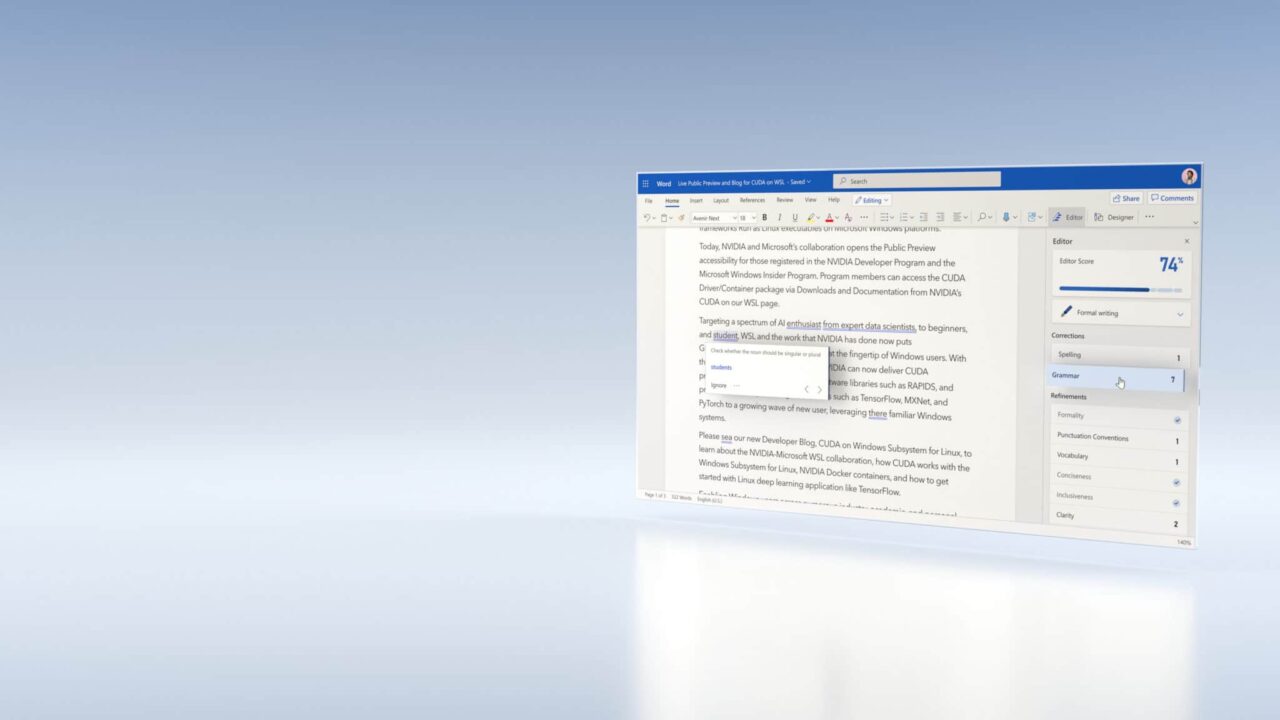
Como cualquier buen editor, es rápido y conocedor. Esto se debe a que el Editor de Microsoft en Word en línea ahora puede aprovechar el Servidor de Inferencia NVIDIA Triton, ONNX Runtime y Microsoft Azure Machine Learning, que forma parte de Azure AI, para ofrecer esta experiencia inteligente.
En su discurso del evento digital GTC – GPU Technology Conference, el CEO de NVIDIA Jensen Huang anunció las novedades durante su presentación, el 5 de octubre.
Productividad de Office en IA
Microsoft tiene la misión de sorprender a los usuarios de las aplicaciones de productividad de Microsoft Office con la magia de la IA. Las nuevas experiencias que ahorran tiempo incluirán sugerencias gramaticales en tiempo real, respuesta a preguntas dentro de los documentos (piensa en la búsqueda de Bing para documientos) y texto predictivo para ayudar a completar oraciones.
Estas experiencias que aumentan la productividad solo son posibles con deep learning y redes neuronales. Por ejemplo, a diferencia de los servicios que se basan en la lógica tradicional basada en reglas, cuando se trata de corregir gramática, el Editor de Word para la web es capaz de comprender el contexto de una oración y sugerir las opciones de palabras adecuadas.
 Además, estos modelos de deep learning, que pueden involucrar cientos de millones de parámetros, deben ser escalables y proporcionar inferencias en tiempo real para lograr una experiencia de usuario óptima. Se espera que el modelo de IA del Editor de Microsoft solo para la revisión gramatical en Word maneje más de 500,000 millones de consultas al año.
Además, estos modelos de deep learning, que pueden involucrar cientos de millones de parámetros, deben ser escalables y proporcionar inferencias en tiempo real para lograr una experiencia de usuario óptima. Se espera que el modelo de IA del Editor de Microsoft solo para la revisión gramatical en Word maneje más de 500,000 millones de consultas al año.
La implementación a esta escala podría hacer explotar los presupuestos de deep learning. Afortunadamente, las funciones de ejecución de modelos simultáneos y procesamiento por lotes dinámico de NVIDIA Triton, accesibles a través de Azure Machine Learning, redujeron el costo en aproximadamente un 70% y lograron un rendimiento de 450 consultas por segundo en una sola GPU NVIDIA V100 Tensor Core, con una respuesta de menos de 200 milisegundos hora. Azure Machine Learning proporcionó la escala y las capacidades necesarias para administrar el ciclo de vida del modelo, como el control de versiones y la supervisión.
Inferencia de Alto Rendimiento con Triton en Azure Machine Learning
Con el aumento de tamaño de los modelos de machine learning, las GPU se han vuelto más necesarias que nunca durante el entrenamiento y la implementación de modelos. Para la implementación de IA en producción, las organizaciones buscan capacidades de inferencia escalables, compatibilidad con múltiples backends de frameworks, utilización óptima de las GPU y las CPU, y administración del ciclo de vida de machine learning.
El conjunto NVIDIA Triton y ONNX Runtime en Azure Machine Learning ofrece inferencias escalables de alto rendimiento. Los usuarios de Azure Machine Learning pueden aprovechar la compatibilidad con Triton para múltiples frameworks, inferencia en tiempo real, por lotes y de transmisión, procesamiento por lotes dinámico y ejecución concurrente.
Escribir con la IA en Word
El autor y poeta Robert Graves alguna vez dijo: “No hay buena escritura, solo buena reescritura”. En otras palabras, escribe y, luego, edita y mejora el texto.
El editor en Word para la web te permite hacer ambas cosas al mismo tiempo. Y aunque el Editor es la primera función de Word que obtiene la velocidad y la amplitud de los avances habilitados por Triton y ONNX Runtime, es probable que sea solo el comienzo de lo que está por venir.