Salga de la cama, encienda la computadora portátil, encienda la cámara web y se vea perfecta en cada videollamada, con la ayuda de la IA desarrollada por los investigadores de NVIDIA.
Vid2Vid Cameo, uno de los modelos de deep learning detrás del kit de desarrollo de software NVIDIA Maxine para videoconferencias, utiliza redes adversariales generativas (conocidas como GANs) para sintetizar videos realistas de cabeza parlante utilizando una sola imagen 2D de una persona.
Para usarlo, los participantes envían una imagen de referencia, que podría ser una foto real de sí mismos o un avatar de dibujos animados, antes de unirse a una videollamada. Durante la reunión, el modelo de IA capturará el movimiento en tiempo real de cada individuo y lo aplicará a la imagen fija cargada anteriormente.
Eso significa que al subir una foto de sí mismos con atuendo formal, los asistentes a la reunión con cabello musculado y pijama pueden aparecer en una llamada con atuendos apropiados para el trabajo, con IA que mapea los movimientos faciales del usuario a la foto de referencia. Si el sujeto se gira hacia la izquierda, la tecnología puede ajustar el punto de vista para que el asistente parezca estar directamente frente a la cámara web.
Además de ayudar a los asistentes a las reuniones a lucir lo mejor posible, esta técnica de IA también reduce el ancho de banda necesario para las videoconferencias hasta en 10 veces, evitando la fluctuación y el retraso. Pronto estará disponible en el SDK de Códec de Video NVIDIA como el AI Face Codec.
«Muchas personas tienen un ancho de banda de Internet limitado, pero aún así quieren tener una videollamada sin problemas con amigos y familiares», dijo el investigador de NVIDIA Ming-Yu Liu, coautor del proyecto. «Además de ayudarlos, la tecnología subyacente también podría usarse para ayudar al trabajo de animadores, editores de fotos y desarrolladores de juegos».
Vid2Vid Cameo se presentó en la prestigiosa Conference on Computer Vision and Pattern Recognition, uno de los 28 documentos de NVIDIA en el evento virtual. También está disponible en el AI Playground, donde cualquiera puede experimentar nuestras demostraciones de investigación de primera mano.
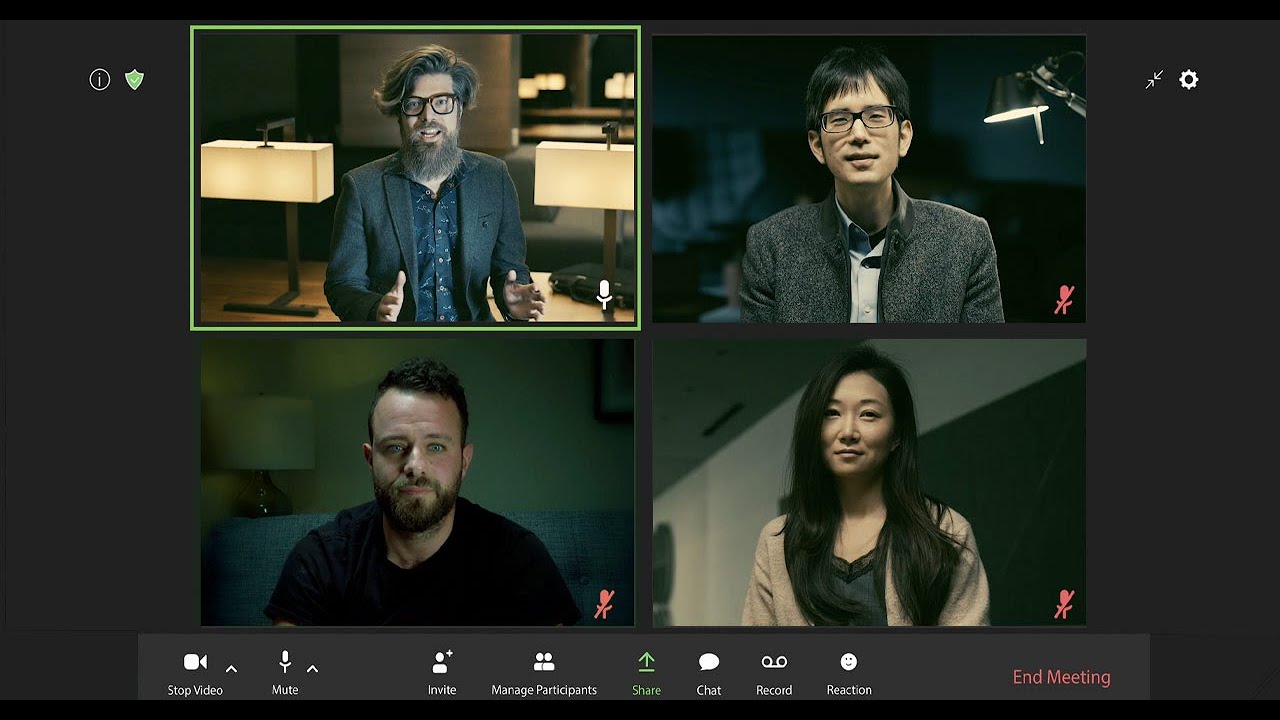
La IA Roba el Show
En un guiño a las películas clásicas de atracos (y un exitoso programa de Netflix), los investigadores de NVIDIA pusieron su modelo GAN de cabeza parlante a través de sus pasos para una reunión virtual. La demostración destaca las características clave de Vid2Vid Cameo, incluida la redirección facial, los avatares animados y la compresión de datos.
Estas capacidades llegarán pronto al SDK de NVIDIA Maxine, que ofrece a los desarrolladores modelos preentrenados optimizados para efectos de vídeo, audio y realidad aumentada en videoconferencias y transmisión en directo.
Los desarrolladores ya pueden adoptar los efectos de Maxine AI, incluida la eliminación inteligente de ruido, la ampliación de video y la estimación de la postura corporal. El SDK de descarga gratuita también se puede combinar con la plataforma NVIDIA Jarvis para aplicaciones de IA conversacionales, incluida la transcripción y la traducción.
Hola Desde el Lado de la IA
Vid2Vid Cameo requiere solo dos elementos para crear una cabeza parlante de IA realista para videoconferencias: una sola toma de la apariencia de la persona y una transmisión de video que dicta cómo se debe animar esa imagen.
Desarrollado en sistemas NVIDIA DGX, el modelo fue entrenado utilizando un conjunto de datos de 180.000 videos de cabezas parlantes de alta calidad. La red aprendió a identificar 20 puntos clave que se pueden utilizar para modelar el movimiento facial sin anotaciones humanas. Los puntos codifican la ubicación de las características que incluyen los ojos, la boca y la nariz.
A continuación, extrae estos puntos clave de una imagen de referencia de la persona que llama, que podría enviarse a otros participantes de la videoconferencia antes de tiempo o volver a utilizarse de reuniones anteriores. De esta manera, en lugar de enviar voluminosas transmisiones de video en vivo de un participante a otro, las plataformas de videoconferencia pueden simplemente enviar datos sobre cómo se mueven los puntos faciales clave del orador.
En el lado del receptor, el modelo GAN utiliza esta información para sintetizar un vídeo que imita la apariencia de la imagen de referencia.
Al comprimir y enviar solo la posición de la cabeza y los puntos clave hacia adelante y hacia atrás, en lugar de secuencias de vídeo completas, esta técnica puede reducir las necesidades de ancho de banda para las videoconferencias en 10 veces, lo que proporciona una experiencia de usuario más fluida. El modelo se puede ajustar para transmitir un número diferente de puntos clave para adaptarse a diferentes entornos de ancho de banda sin comprometer la calidad visual.
El punto de vista del video de la cabeza parlante resultante también se puede ajustar libremente para mostrar al usuario desde un perfil lateral o recto, así como desde ángulos de cámara más bajos o más altos. Esta característica también podría ser aplicada por los editores de fotos que trabajan con imágenes fijas.
Los investigadores de NVIDIA descubrieron que Vid2Vid Cameo supera a los modelos de vanguardia al producir resultados más realistas y nítidos, ya sea que la imagen de referencia y el video sean de la misma persona, o cuando la IA tiene la tarea de transferir el movimiento de una persona a una imagen de referencia de otra.
Esta última característica se puede utilizar para aplicar los movimientos faciales de un orador para animar un avatar digital en una videoconferencia, o incluso dar expresión realista y movimiento a un personaje de videojuego o de dibujos animados.
El artículo detrás de Vid2Vid Cameo fue escrito por los investigadores de NVIDIA Ting-Chun Wang, Arun Mallya y Ming-Yu Liu. El equipo de Investigación de NVIDIA está formado por más de 200 científicos de todo el mundo, centrándose en áreas como la IA, la visión artificial, los coches autónomos, la robótica y los gráficos.
Nuestro agradecimiento al actor Edan Moses, quien interpretó la voz en off en inglés de The Professor en «La Casa De Papel» en Netflix, por su contribución al video de arriba con nuestra última investigación de IA.