
NVIDIA y sus socios siguen proporcionando el mejor rendimiento general de entrenamiento de IA y la mayor cantidad de presentaciones en todas las evaluaciones, con el 90% de todas las entradas procedentes del ecosistema, según las evaluaciones MLPerf publicadas hoy.
La plataforma de IA de NVIDIA cubrió las ocho evaluaciones en la ronda de MLPerf Training 2.0, lo que demuestra su versatilidad líder en la industria.
Ningún otro acelerador ejecutó todas las evaluaciones, que representan casos de uso populares de IA, incluido el reconocimiento de voz, el procesamiento de idiomas naturales, los sistemas de recomendación, la detección de objetos, la clasificación de imágenes y más. Algo que NVIDIA ha hecho consistentemente desde que participó en diciembre de 2018 de la primera ronda de MLPerf, una evaluación de IA estándar de la industria.
Disponibilidad y Resultados Líderes de las Evaluaciones
En su cuarta participación consecutiva en MLPerf Training, la GPU NVIDIA A100 Tensor Core basada en la arquitectura NVIDIA Ampere logró otro resultado sobresaliente.

Selene (nuestra supercomputadora de IA interna basada en el NVIDIA DGX SuperPOD modular y con la tecnología de las GPU NVIDIA A100, nuestro conjunto de software y redes NVIDIA InfiniBand) logro el tiempo más rápido de entrenamiento en cuatro de ocho pruebas.
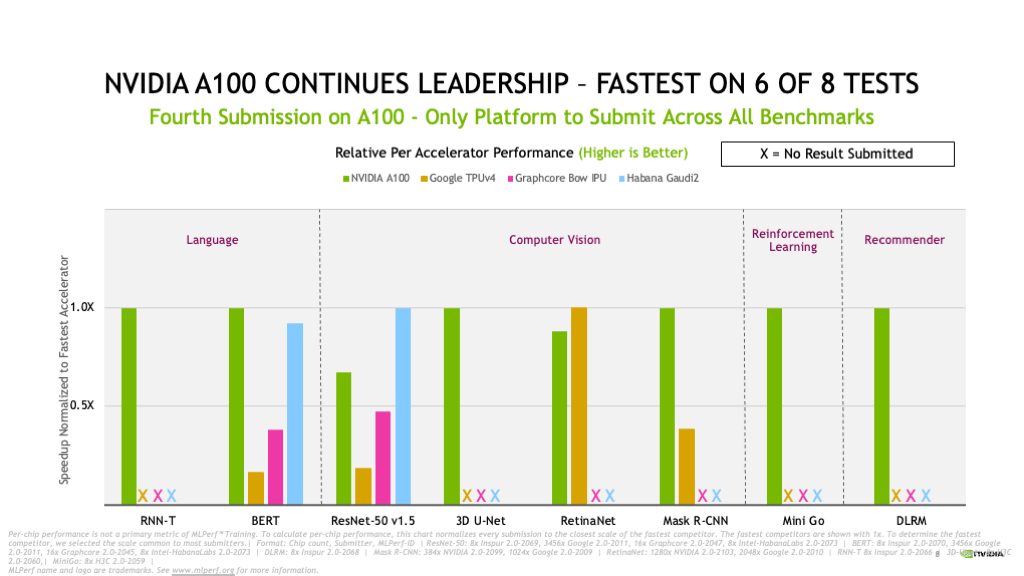
NVIDIA A100 también continuó su liderazgo por chip y demostró ser la más rápida en seis de las ocho pruebas.
Un total de 16 socios presentaron resultados en esta ronda utilizando la plataforma de IA de NVIDIA. Entre ellos se encuentran ASUS, Baidu, CASIA (Instituto de Automatización, Academia de Ciencias de China), Dell Technologies, Fujitsu, GIGABYTE, H3C, Hewlett Packard Enterprise, Inspur, KRAI, Lenovo, Microsoft Azure, MosaicML, Nettrix y Supermicro.
La mayoría de nuestros socios OEM presentaron resultados utilizando Sistemas Certificados por NVIDIA, que son servidores validados por NVIDIA para proporcionar un gran rendimiento, capacidad de administración, seguridad y escalabilidad para implementaciones empresariales.
Muchos Modelos Potencian las Aplicaciones Reales de IA
Es posible que una aplicación de IA necesite comprender la solicitud hablada de un usuario, clasificar una imagen, hacer una recomendación y ofrecer una respuesta como un mensaje hablado.
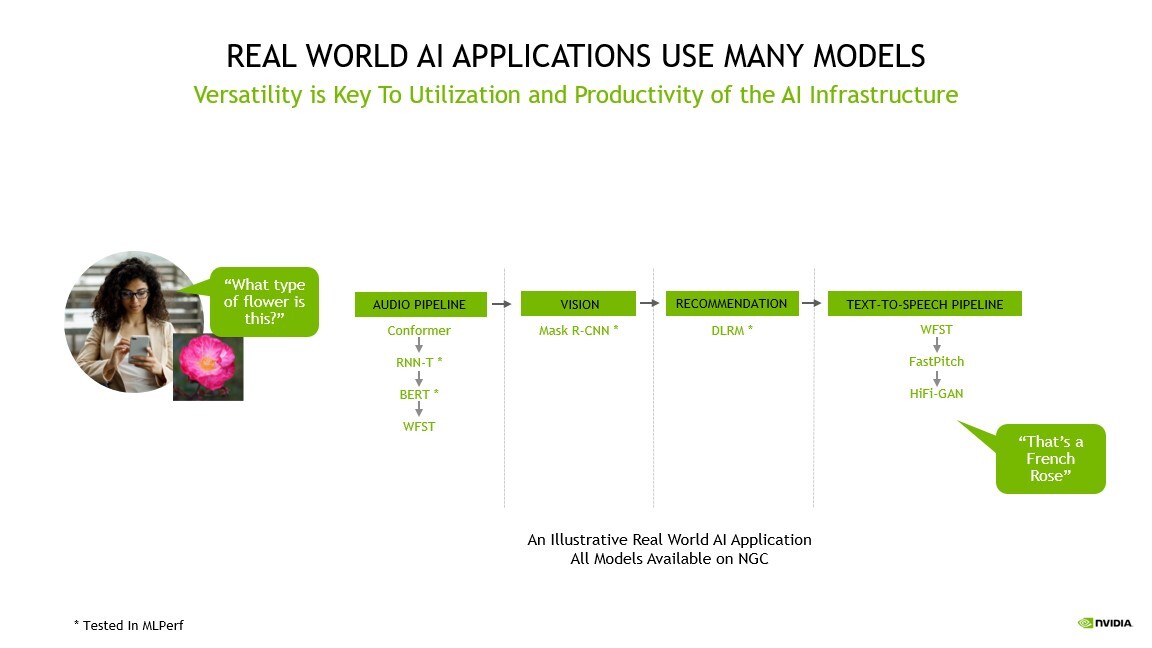
Incluso el simple caso de uso anterior requiere casi 10 modelos, lo que destaca la importancia de ejecutar cada evaluación.
Estas tareas requieren varios tipos de modelos de IA para trabajar en secuencia, también conocidas como un «pipeline». Los usuarios deben diseñar, entrenar, implementar y optimizar estos modelos de forma rápida y flexible.
Es por eso que tanto la versatilidad (la capacidad de ejecutar cada modelo en MLPerf y otros más), como el rendimiento líder son vitales para llevar la IA del mundo real a la producción.
Ofrecer el ROI con IA
Para los clientes, sus equipos de ciencia de datos e ingeniería son sus recursos más preciados, y su productividad determina el retorno de la inversión para la infraestructura de IA. Los clientes deben considerar el costo de los costosos equipos de ciencia de datos, que a menudo juegan un papel importante en el costo total de la implementación de la IA, así como el costo relativamente pequeño de implementar la infraestructura de IA en sí.
La productividad de los investigadores de IA depende de la capacidad de probar rápidamente nuevas ideas, ya que requieren tanto la versatilidad para entrenar cualquier modelo como la velocidad que ofrece entrenar esos modelos a la escala más grande. Es por eso que las organizaciones se centran en la productividad general por dólar para determinar las mejores plataformas de IA, una vista más integral que representa de manera más precisa el verdadero costo de implementar la IA.
Además, la utilización de su infraestructura de IA se basa en su fungibilidad o la capacidad de acelerar todo el workflow de IA (desde la preparación de datos hasta el entrenamiento y la inferencia) en una única plataforma.
Con la IA de NVIDIA, los clientes pueden usar la misma infraestructura para todo el proceso de IA, reutilizarla para igualar las diferentes demandas entre la preparación, el entrenamiento y la inferencia de datos, lo que aumenta drásticamente la utilización y, por extensión, genera un ROI muy alto.
Y, a medida que los investigadores descubren nuevos avances de IA, la compatibilidad con las innovaciones más recientes del modelo es clave para maximizar la vida útil de la infraestructura de IA.
La IA de NVIDIA ofrece la productividad más rentable, ya que es universal y se adapta a cada modelo, se escala a cualquier tamaño y acelera la IA de forma integral (desde la preparación de datos hasta el entrenamiento y la inferencia).
Los resultados de hoy proporcionan la demostración más reciente de la amplia y profunda experiencia en IA de NVIDIA, que se demuestra en cada entrenamiento, inferencia y HPC de MLPerf hasta la fecha.
23 Veces Más Rendimiento en 3.5 Años
En los dos años transcurridos desde nuestra primera presentación en MLPerf con A100, nuestra plataforma ha logrado un rendimiento 6 veces más alto. Las optimizaciones continuas en nuestra pila de software ayudaron a impulsar esas ganancias.
Desde la aparición de MLPerf, la plataforma de IA de NVIDIA ha ofrecido 23 veces más rendimiento en 3.5 años de evaluación (el resultado de la innovación de pila completa abarca GPU, software y mejoras a escala). Es este compromiso continuo con la innovación que asegura a los clientes que la plataforma de IA en la que invierten en la actualidad y que mantienen en servicio durante 3 a 5 años, continuará creciendo para apoyar a las empresas de vanguardia.
Además, la arquitectura NVIDIA Hopper, que se anunció en marzo promete otro enorme salto en el rendimiento en futuras rondas de MLPerf.
Cómo Lo Logramos
La innovación de software continúa desbloqueando más rendimiento en la arquitectura NVIDIA Ampere.
Por ejemplo, CUDA Graphs (un software que ayuda a minimizar la sobrecarga de lanzamiento en trabajos que se ejecutan en muchos aceleradores) se utiliza extensamente en todas nuestras presentaciones. Los kernels optimizados en nuestras bibliotecas, como cuDNN y el preprocesamiento en DALI, desbloquean aceleraciones adicionales. También implementamos mejoras de pila completa en hardware, software y redes como NVIDIA Magnum IO y SHARP, que descargan algunas funciones de IA a la red para impulsar aún más el rendimiento, especialmente a escala.
Todo el software que usamos está disponible en el repositorio de MLPerf, para que todos puedan obtener nuestros resultados de clase mundial. Incorporamos continuamente estas optimizaciones en contenedores disponibles en NGC, nuestro centro de software para aplicaciones de GPU, y ofrecemos NVIDIA AI Enterprise para brindar software optimizado que sea totalmente compatible con NVIDIA.
Dos años después del debut de A100, la plataforma de IA de NVIDIA continúa ofreciendo el rendimiento más alto en MLPerf 2.0 y es la única plataforma que se incluye en cada evaluación. Nuestra arquitectura Hopper de próxima generación promete otro salto gigantesco en futuras rondas de MLPerf.
Nuestra plataforma es universal para adaptarse a cada modelo y framework a cualquier escala, y proporciona fungibilidad para manejar cada parte de la carga de trabajo de IA. Está disponible en los principales fabricantes de servidores y nubes.