
MLPerf sigue siendo la medida definitiva del rendimiento de la IA como punto de referencia independiente de terceros. La plataforma de IA de NVIDIA ha mostrado constantemente liderazgo tanto en capacitación como en inferencia desde el inicio de MLPerf, incluidos los puntos de referencia de MLPerf Inference 3.0 publicados hoy.
“Hace tres años, cuando presentamos A100, el mundo de la IA estaba dominado por la visión artificial. La IA generativa ha llegado”, dijo el fundador y director ejecutivo de NVIDIA, Jensen Huang.
“Esta es exactamente la razón por la que construimos Hopper, específicamente optimizado para GPT con Transformer Engine. El MLPerf 3.0 de hoy destaca que Hopper ofrece 4 veces más rendimiento que A100.
“El siguiente nivel de IA generativa requiere una nueva infraestructura de IA para entrenar modelos de lenguaje grandes con gran eficiencia energética. Los clientes están aumentando Hopper a escala, creando una infraestructura de IA con decenas de miles de GPU Hopper conectadas por NVIDIA NVLink e InfiniBand.
“La industria está trabajando arduamente en nuevos avances en IA generativa segura y confiable. Hopper está permitiendo este trabajo esencial”, dijo.
Los últimos resultados de MLPerf muestran que NVIDIA lleva la inferencia de IA a nuevos niveles de rendimiento y eficiencia desde el cloud hasta el edge.
Específicamente, las GPU NVIDIA H100 Tensor Core que se ejecutan en sistemas DGX H100 brindaron el rendimiento más alto en cada prueba de inferencia de IA, el trabajo de ejecutar redes neuronales en producción. Gracias a las optimizaciones de software , las GPU brindaron hasta un 54 % de aumento en el rendimiento desde su debut en septiembre.
En atención médica, las GPU H100 generaron un aumento del rendimiento del 31 % desde septiembre en 3D-UNet, el punto de referencia de MLPerf para imágenes médicas.
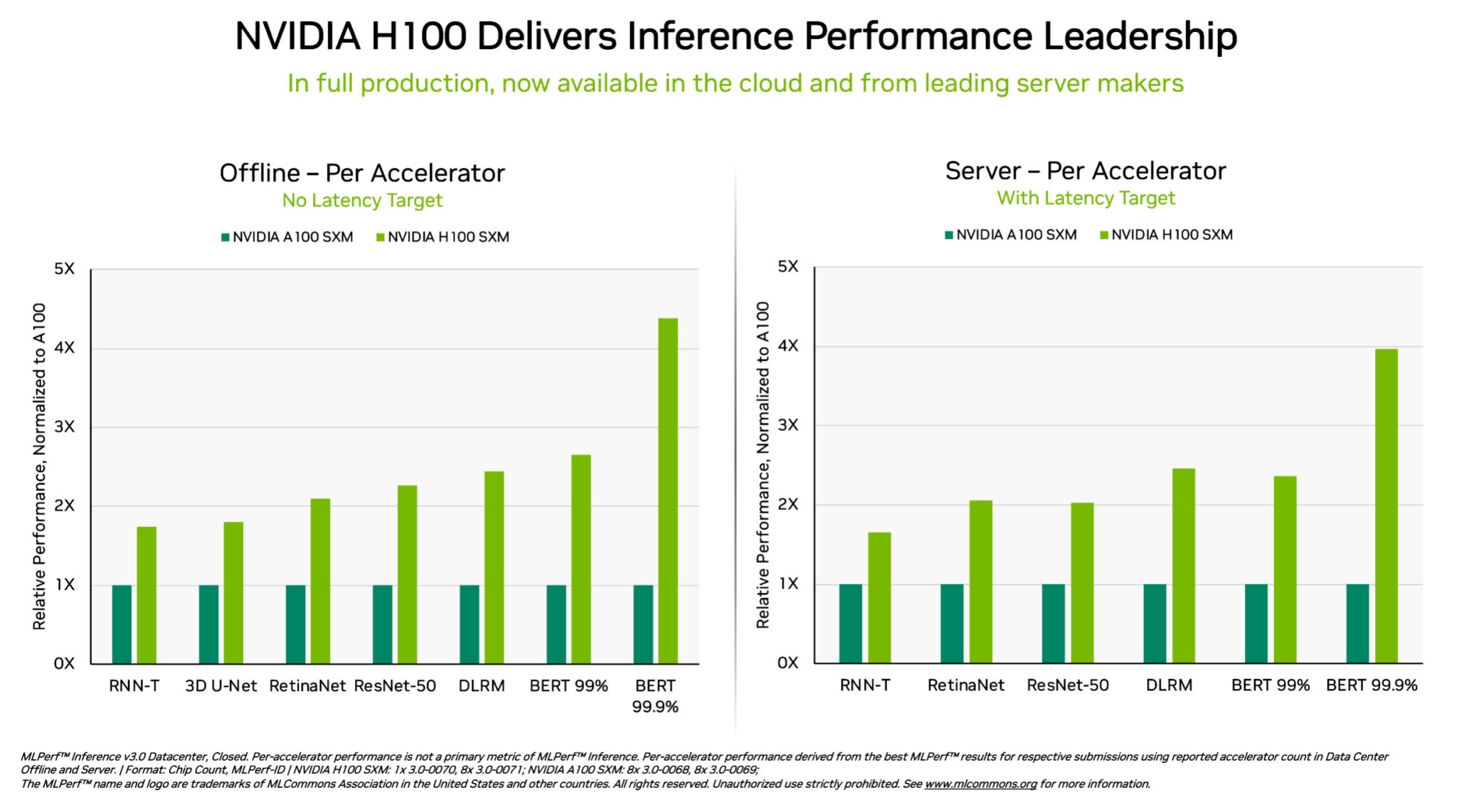
Impulsada por su Transformer Engine , la GPU H100, basada en la arquitectura Hopper, se destacó en BERT, un modelo de lenguaje grande basado en transformadores que allanó el camino para el amplio uso actual de la IA generativa.
La IA generativa permite a los usuarios crear rápidamente texto, imágenes, modelos 3D y más. Es una capacidad que las empresas, desde las empresas emergentes hasta los proveedores de servicios en el cloud, están adoptando rápidamente para permitir nuevos modelos comerciales y acelerar los existentes.
Cientos de millones de personas ahora usan herramientas de inteligencia artificial generativa como ChatGPT, también un modelo de transformador, esperando respuestas instantáneas.
En este momento iPhone de IA, el rendimiento de la inferencia es vital. El aprendizaje profundo ahora se está implementando en casi todas partes, lo que genera una necesidad insaciable de rendimiento de inferencia desde las plantas de producción hasta los sistemas de recomendación en línea .
Las GPU L4 aceleran desde el principio
Las GPU NVIDIA L4 Tensor Core hicieron su debut en las pruebas MLPerf a más de 3 veces la velocidad de las GPU T4 de la generación anterior. Empaquetados en un factor de forma de bajo perfil, estos aceleradores están diseñados para ofrecer un alto rendimiento y una baja latencia en casi cualquier servidor.
Las GPU L4 ejecutaron todos los workloads de MLPerf. Gracias a su soporte para el formato clave FP8, sus resultados fueron particularmente sorprendentes en el modelo BERT, hambriento de rendimiento.
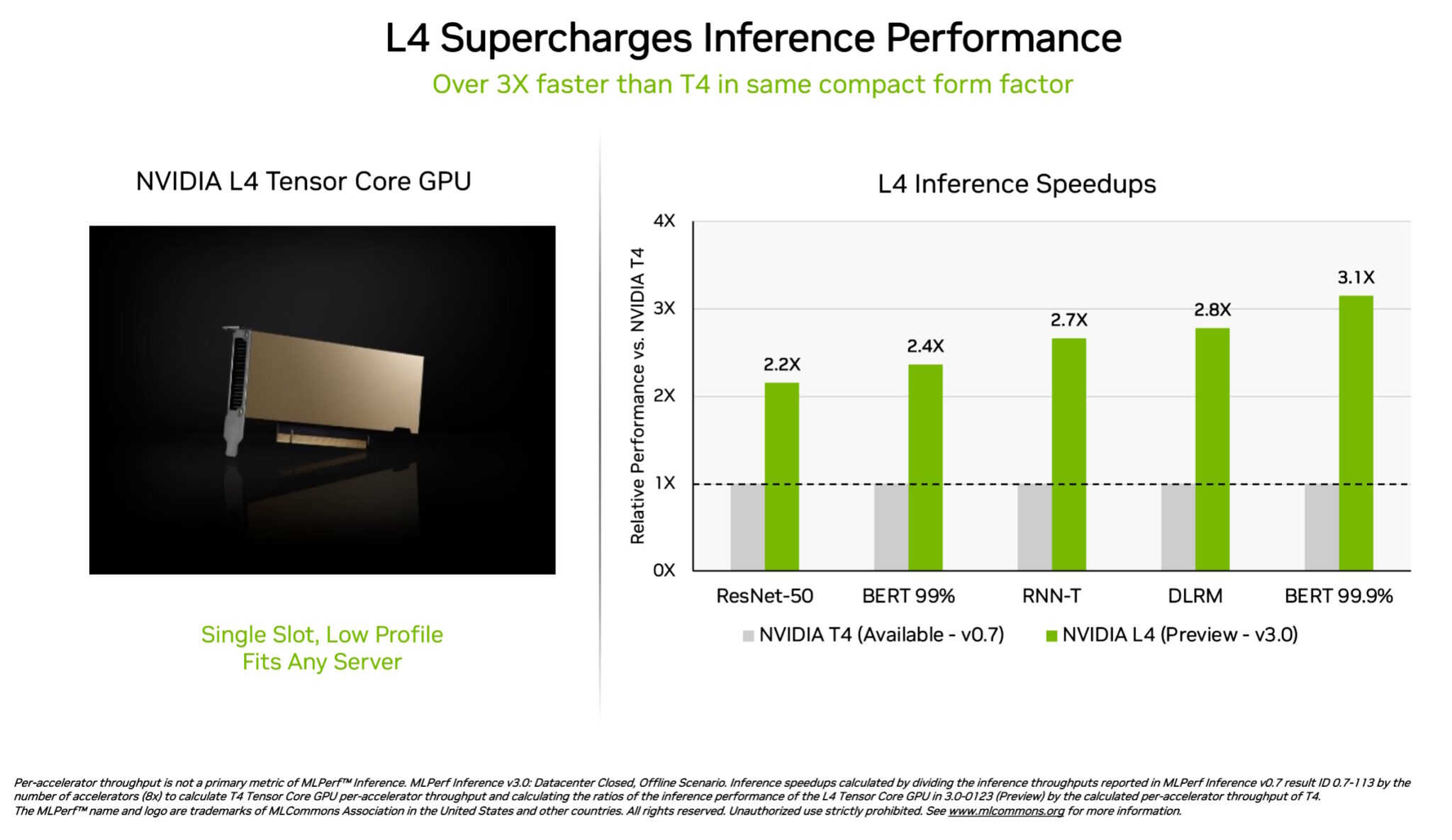
Además del rendimiento estelar de IA, las GPU L4 ofrecen una decodificación de imágenes hasta 10 veces más rápida, un procesamiento de video hasta 3,2 veces más rápido y gráficos más de 4 veces más rápidos y un rendimiento de representación en tiempo real.
Anunciados hace dos semanas en GTC , estos aceleradores ya están disponibles a través de los principales fabricantes de sistemas y proveedores de servicios en el cloud . Las GPU L4 son la última incorporación a la cartera de NVIDIA de plataformas de inferencia de IA lanzadas en GTC.
Software, redes brillan en la prueba del sistema
La plataforma de IA de pila completa de NVIDIA mostró su liderazgo en una nueva prueba de MLPerf.
El llamado punto de referencia de división de red transmite datos a un servidor de inferencia remoto. Refleja el escenario popular de usuarios empresariales que ejecutan trabajos de IA en el cloud con datos almacenados detrás de firewalls corporativos.
NVIDIA DGX A100 remotos entregaron hasta el 96 % de su rendimiento local máximo, en parte porque necesitaban esperar a que las CPU completaran algunas tareas. En la prueba ResNet-50 para visión por computadora, manejada únicamente por GPU, alcanzaron el 100 %.
Ambos resultados se deben, en gran parte, a las redes NVIDIA Quantum Infiniband , las tarjetas NVIDIA ConnectX SmartNIC y software como NVIDIA GPUDirect .
Orin muestra ganancias 3.2x en el edge
Por separado, el sistema en módulo NVIDIA Jetson AGX Orin generó ganancias de hasta un 63 % en eficiencia energética y un 81 % en rendimiento en comparación con sus resultados hace un año. Jetson AGX Orin proporciona inferencia cuando se necesita IA en espacios confinados a bajos niveles de energía, incluso en sistemas alimentados por baterías.
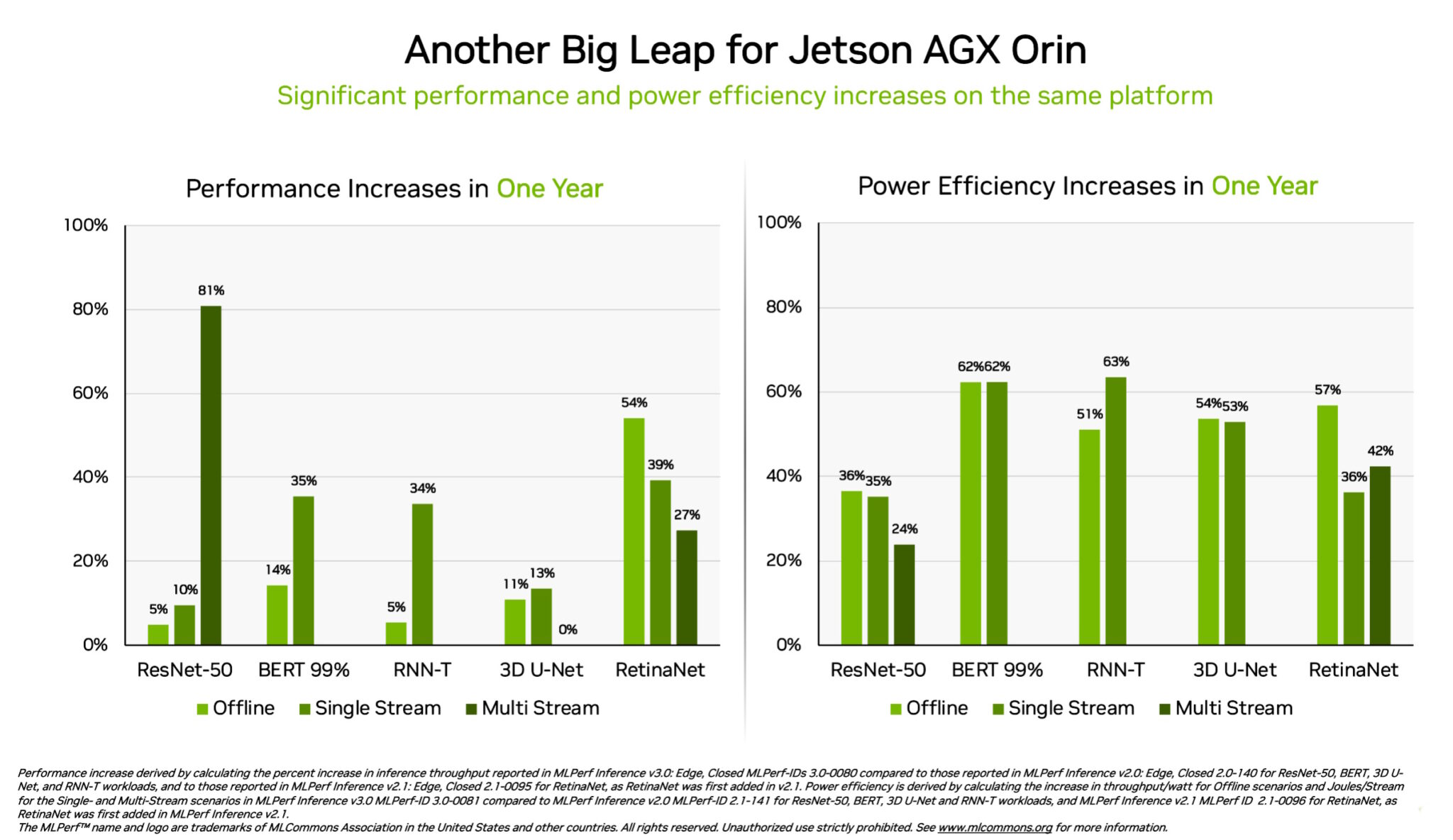
Para aplicaciones que necesitan módulos aún más pequeños que consuman menos energía, el Jetson Orin NX 16G brilló en su debut en los puntos de referencia. Entregó hasta 3,2 veces el rendimiento del procesador Jetson Xavier NX de la generación anterior.
Un amplio ecosistema de IA de NVIDIA
Los resultados de MLPerf muestran que NVIDIA AI está respaldada por el ecosistema de aprendizaje automático más amplio de la industria.
Diez empresas presentaron resultados en la plataforma NVIDIA en esta ronda. Provenían de los fabricantes de sistemas y servicios en el cloud de Microsoft Azure, incluidos ASUS, Dell Technologies , GIGABYTE, H3C, Lenovo , Nettrix, Supermicro y xFusion.
Su trabajo muestra que los usuarios pueden obtener un gran rendimiento con NVIDIA AI tanto en el cloud como en servidores que se ejecutan en sus propios data center.
Los socios de NVIDIA participan en MLPerf porque saben que es una herramienta valiosa para los clientes que evalúan proveedores y plataformas de IA. Los resultados de la última ronda demuestran que el rendimiento que ofrecen hoy crecerá con la plataforma NVIDIA.
Los usuarios necesitan un rendimiento versátil
NVIDIA AI es la única plataforma que ejecuta todas los workloads y escenarios de inferencia de MLPerf en el data center y la computación en el edge. Su rendimiento y eficiencia versátiles hacen que los usuarios sean los verdaderos ganadores.
Las aplicaciones del mundo real generalmente emplean muchas redes neuronales de diferentes tipos que a menudo necesitan brindar respuestas en tiempo real.
Por ejemplo, una aplicación de IA puede necesitar comprender la solicitud hablada de un usuario, clasificar una imagen, hacer una recomendación y luego entregar una respuesta como un mensaje hablado con una voz que suena humana. Cada paso requiere un tipo diferente de modelo de IA.
Los puntos de referencia de MLPerf cubren estas y otros workloads populares de IA. Es por eso que las pruebas aseguran que los tomadores de decisiones de TI obtendrán un rendimiento confiable y flexible para implementar.
Los usuarios pueden confiar en los resultados de MLPerf para tomar decisiones de compra informadas, porque las pruebas son transparentes y objetivas. Los puntos de referencia cuentan con el respaldo de un amplio grupo que incluye Arm, Baidu, Facebook AI, Google, Harvard, Intel, Microsoft, Stanford y la Universidad de Toronto.
Software que puede usar
La capa de software de la plataforma NVIDIA AI, NVIDIA AI Enterprise , garantiza que los usuarios obtengan un rendimiento optimizado de sus inversiones en infraestructura, así como el soporte, la seguridad y la confiabilidad de nivel empresarial necesarios para ejecutar AI en el data center corporativo.
Todo el software utilizado para estas pruebas está disponible en el repositorio de MLPerf , por lo que cualquiera puede obtener estos resultados de clase mundial.
Las optimizaciones se pliegan continuamente en contenedores disponibles en NGC , el catálogo de NVIDIA para software acelerado por GPU. El catálogo alberga NVIDIA TensorRT , utilizado por cada presentación en esta ronda para optimizar la inferencia de IA.
Lea este blog técnico para profundizar en las optimizaciones que impulsan el rendimiento y la eficiencia de MLPerf de NVIDIA.