La simulación de yacimientos ayuda a los ingenieros de yacimientos a optimizar la exploración de recursos naturales mediante la simulación de escenarios complejos y la comparación con datos de campo. Esto se extiende a la simulación de embalses agotados que podrían reutilizarse para el almacenamiento de carbono. La simulación de yacimientos es crucial para las empresas energéticas que buscan aumentar la eficiencia operativa en la exploración y la producción.
Esta publicación demuestra cómo la CPU NVIDIA Grace se destaca en la resolución de sistemas lineales dentro del workflow de Petrobras, logrando un tiempo de solución hasta 4,5 veces más rápido, una eficiencia energética 4,3 veces mayor y una escalabilidad 1,5 veces mayor en comparación con las CPU alternativas basadas en x86.
Petrobras es una empresa brasileña líder en energía, que está en transición a nuevas fuentes de energía mientras mantiene su negocio principal de exploración y producción de petróleo y gas (O&G). De acuerdo con las Top500 y Green500, Petrobras cuenta con la infraestructura HPC más grande de América Latina, impulsada por la plataforma de computación acelerada full-stack de NVIDIA. Sus principales cargas de trabajo son el procesamiento sísmico y la simulación de yacimientos.
La compañía fue pionera en la exploración en aguas ultraprofundas, con operaciones que alcanzaron profundidades de hasta 7 km. Con una perforación de un solo pozo que cuesta hasta 100 millones de dólares, la computación de alto rendimiento (HPC) ayuda a reducir la incertidumbre de la exploración de recursos y a mejorar las tasas de éxito de la producción.
Simulación de Yacimientos y el Proyecto SolverBR
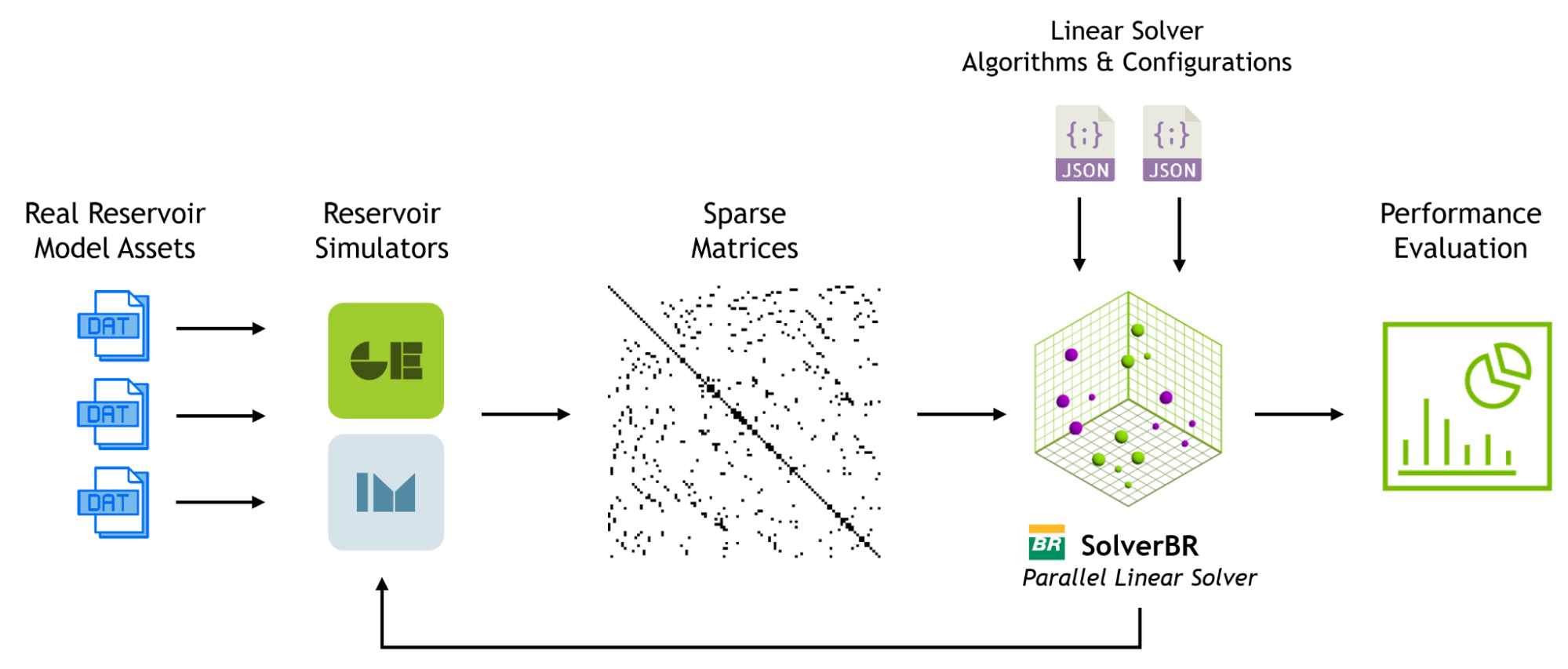
La resolución de sistemas lineales es la tarea que más tiempo consume en las simulaciones de yacimientos (Figura 1). Este proceso puede representar hasta el 70% del tiempo total de cómputo dentro de la cartera de simulación de Petrobras. Por lo tanto, la optimización de los solucionadores lineales dispersos mientras se mantiene una alta precisión es crucial para estudios de yacimientos confiables.
Petrobras colaboró con la UFRJ y otros institutos de investigación e innovación de Brasil para desarrollar SolverBR, un solucionador de ecuaciones lineales basado en CPU que utiliza nuevas técnicas de paralelización computacional con una implementación multinúcleo eficiente. SolverBR está integrado con simuladores geomecánicos y de flujo de terceros, incluyendo el IMEX y el GEM del Computer Modelling Group (CMG), ampliamente utilizados para la simulación composicional de reservas pre-sal.
Portabilidad de SolverBR de x86 a Arm
Los procesadores basados en Arm, como la CPU NVIDIA Grace, están ganando terreno en las soluciones de HPC, incluso en el sector energético. Petrobras, NVIDIA y el Centro de Innovación CESAR se han asociado para portar y comparar SolverBR con la CPU NVIDIA Grace en una iniciativa para medir los beneficios clave de las CPU basadas en Arm.
La CPU NVIDIA Grace cuenta con Arm Neoverse V2 de 72 núcleos, conectados por un tejido de coherencia escalable NVIDIA de alto ancho de banda con alto ancho de banda y bajo LPDDR5X de energía de memoria.
Los resultados iniciales demostraron que NVIDIA Grace ofrece las mejores tasas de rendimiento para el tiempo de solución (TTS) y la potencia estimada para la solución (ETS), en comparación con los principales procesadores basados en x86 disponibles tanto en infraestructuras locales como en la nube.
El proyecto se centra en mantener un sistema de compilación multiplataforma, lo que permite que una única base de código y scripts de compilación funcionen sin problemas en múltiples plataformas. Esto garantiza pruebas consistentes y comparaciones de rendimiento confiables al portar códigos x86 a Arm con un esfuerzo mínimo. El robusto ecosistema de Arm, con robustos compiladores y depuradores de código abierto, ha facilitado significativamente esta transición.
GCC 12.3 fue elegido como compilador de prueba debido a su excelente rendimiento. Se recomienda GCC 12.3, o superior, debido a su compatibilidad con optimizaciones automáticas para núcleos Arm Neoverse V2. El proceso de migración a Arm implicó los siguientes pasos:
- Eliminación de todas las marcas específicas de la arquitectura x86, como -maxv, -march y -mtune, que tienen significados diferentes en Arm.
- Utilice el nivel de optimización -O3 para desencadenar optimizaciones automáticas, como la inserción de funciones, la vectorización, el desenredo de bucles, el intercambio y la combinación. Para obtener aún más rendimiento, considere la posibilidad de usar la marca -Fast.
- Anexe -mcpu=native a CFLAGS para asegurarse de que el compilador detecta automáticamente la CPU del sistema de compilación.
- Por último, utilice -flto como indicador opcional para la optimización del tiempo de enlace. Dependiendo de la aplicación, también puede ser necesario -fsigned-char o -funsigned-char.
Se requirió un esfuerzo mínimo para resolver los errores de compilación reemplazando las funciones intrínsecas de Intel con funciones específicas de Arm utilizando las bibliotecas de encabezado sse2neon. Se han corregido errores en tiempo de ejecución, incluidos los problemas de sincronización de memoria causados por optimizaciones anteriores específicas del compilador, lo que dio lugar a un reordenamiento de las instrucciones y a las posteriores divergencias de precisión de punto flotante.
Para este experimento inicial, Petrobras utilizó un conjunto fijo debanderas de compilación, para cada arquitectura (x86_64 y aarch64) sin ajustes específicos por procesador. Esto se hizo con el objetivo de comprender el comportamiento de rendimiento listo para usar. En la tabla 1 se muestran las marcas de compilación utilizadas.
Arquitectura |
Marcas del compilador |
x86_64 |
-std=c++17 -O3 -lrt -fPIC -m64 -march=nativo -mtune=nativo -fopenmp-simd -fopenmp |
aarch64 |
-std=c++17 -O3 -lrt –fPIC -mcpu=nativo -fopenmp-simd -fopen |
Tabla 1. Marcas de compilación para arquitecturas x86 y basadas en Arm
Medición del Rendimiento y la Eficiencia Energética
Se emplearon contenedores de singularidad para replicar la pila de cómputo de SolverBR en múltiples plataformas para garantizar la reproducibilidad. Se utilizó un único archivo de definición para generar varios contenedores, lo que dio como resultado archivos .sif únicos, uno para cada arquitectura de CPU. En la tabla 2 se especifican todas las CPU probadas, basadas en x86 y en Arm, locales y en la nube. NVIDIA llevó a cabo los experimentos en la arquitectura Grace, mientras que Petrobras y CESAR ejecutaron los benchmarks en las otras arquitecturas.
Medio ambiente |
Procesador |
Arquitectura |
Núcleos físicos |
En las instalaciones |
Intel Xeon Oro 6248* |
x86_64 |
20 |
En las instalaciones |
CPU NVIDIA Grace** |
Armv9 |
72 |
AWS EC2 R7g |
Gravitón de AWS3 |
Armv8 |
64 |
AWS EC2 R7i |
Intel Xeon Platinum 8488C (Sapphire Rapids) |
x86_64 |
48 |
AWS EC2 R7a |
AMD EPYC 9R14 (Génova) |
x86_64 |
96 |
Tabla 2. Especificaciones en procesadores basados en x86 y ARM en las instalaciones y en la nube
*Intel Xeon Gold 6248 es el principal clúster de CPU local del Centro de Investigación de Petrobras (CENPES)
**Datos de CPU NVIDIA Grace calculados en un solo SoC NVIDIA Grace utilizando la plataforma GH200 Superchip
La prueba de la porción lineal del pipeline de simulación del yacimiento que se muestra en la Figura 1 implicó la extracción de las matrices dispersas generadas por CMG a partir de conjuntos de datos de campos de petróleo y gas pre-sal (Búzios, Proxy 100, Proxy 200, Sapinhoá) y el modelo de referencia SPE10. El ejemplo establece cómo los simuladores de CMG se pueden modularizar y ampliar con componentes o software de terceros. Los ingenieros de CMG están explorando actualmente oportunidades adicionales para portar componentes y capacidades de sus simuladores, con el objetivo de optimizar el rendimiento en varias plataformas y arquitecturas de hardware.
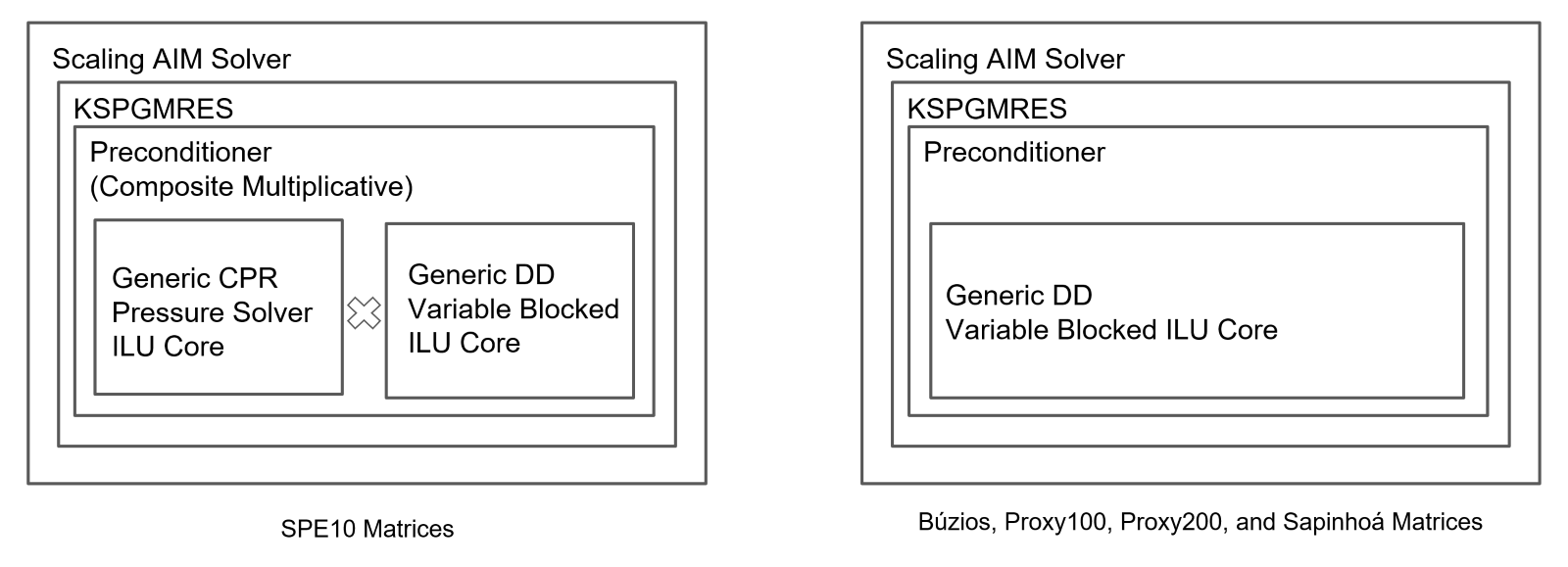
La Figura 2 muestra las configuraciones de los métodos lineales: Método Implícito Adaptativo (AIM), Proyección Subespacial de Krylov Residuo Mínimo Generalizado (KSPGMRES), Residuo de Presión Restringida (CPR), Descomposición de Dominio (DD), Factorización Incompleta de LU (ILU). Cada sistema de ecuaciones se resolvió 50 veces para todos los modelos a lo largo de 3 años, lo que resultó en miles de ejecuciones.
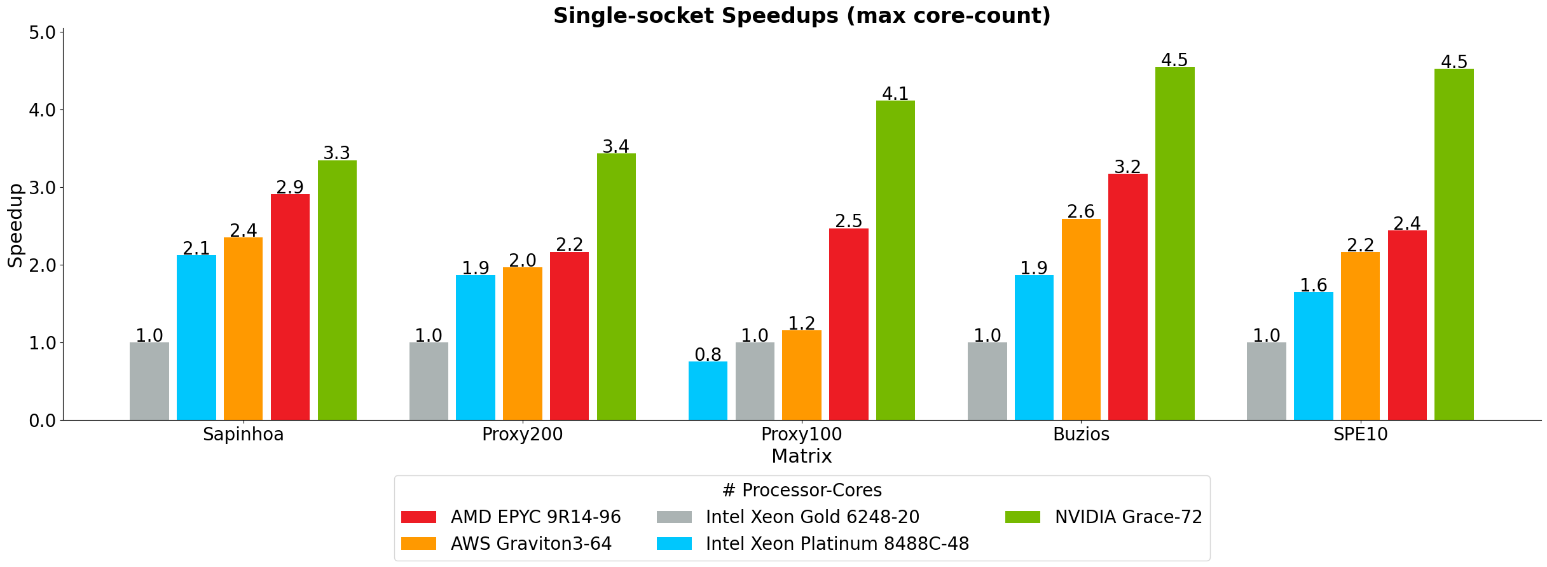
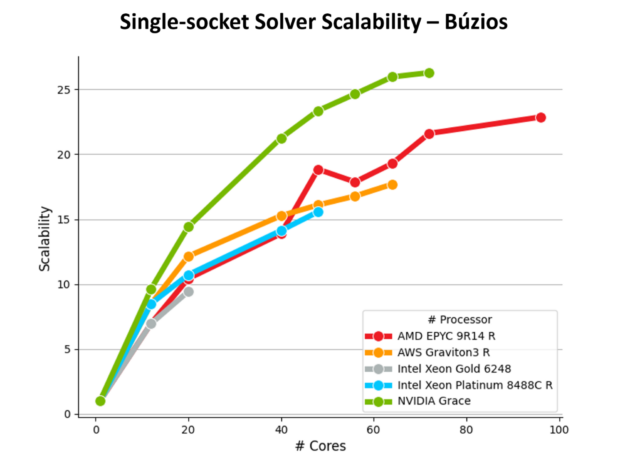
En la Figura 3 se presentan los resultados de aceleración para cada modelo, utilizando el máximo de núcleos disponibles en procesadores de un solo socket. Actualmente, Petrobras utiliza la plataforma Intel Xeon Gold 6248 en su clúster de CPU de producción local, que sirve como punto de referencia para la normalización de resultados.
La arquitectura NVIDIA Grace demuestra un rendimiento superior, logrando las proporciones de rendimiento más altas en todos los modelos, incluidos:
- Hasta 4,5 veces más velocidad que Intel Xeon Gold 6248 (CPU básica de Petrobras)
- Hasta 2,9 veces más velocidad que Intel Xeon Platinum 8488C
- Hasta 1,9 veces más velocidad que AMD EPYC 9R14
La Figura 4 muestra que la CPU NVIDIA Grace tiene la mejor escalabilidad al variar el número total de núcleos al máximo disponible en cada procesador, con hasta un 53% mejores resultados que la opción menos escalable. La CPU NVIDIA Grace demuestra un rendimiento excepcional para esta carga de trabajo debido a sus características únicas, que incluyen un alto ancho de banda de memoria efectivo, un tejido coherente escalable de CPU avanzado (NVIDIA SCF) y la adopción de núcleos Arm Neoverse V2 de clase servidor.
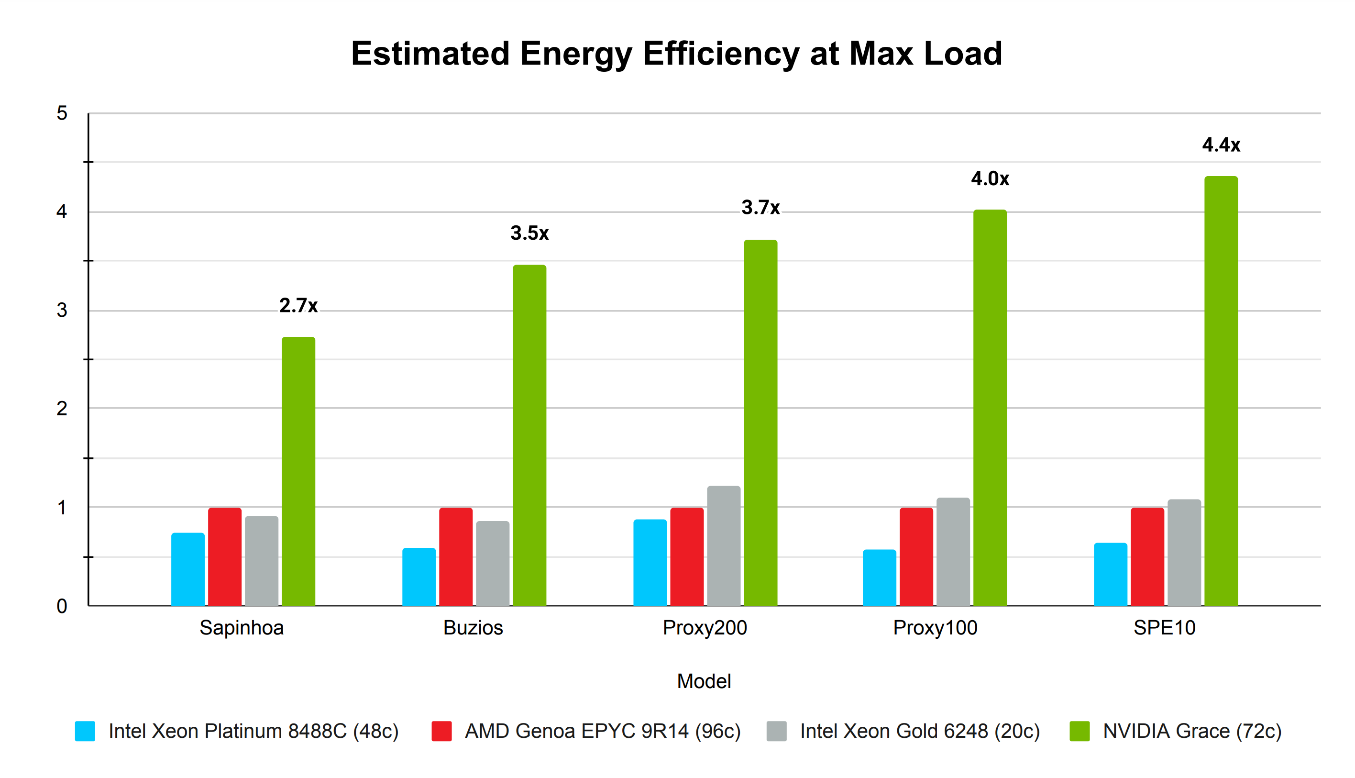
Para estimar la eficiencia energética de la CPU NVIDIA Grace en comparación con las CPU locales, se evaluó la potencia de diseño térmico (TDP) máxima de cada CPU a plena carga con un consumo de memoria estimado basado en la capacidad del procesador y la generación de tecnología. Para el SoC de CPU NVIDIA Grace, el consumo de memoria de la CPU fue de aproximadamente 250 W, y las aceleraciones se informaron utilizando la referencia AMD EPYC 9R14.
NVIDIA Grace demostró la mayor eficiencia energética estimada en todas las pruebas de solucionadores lineales, con una eficiencia energética hasta 4,3 veces mayor (Figura 5).
Conclusión
La CPU NVIDIA Grace superó a todas las CPU x86 y basadas en Arm probadas en TTS, escalabilidad y eficiencia energética. Este éxito se debe principalmente a la arquitectura NVIDIA Grace, que se centra en combinar la eficiencia energética con el alto rendimiento, que es la demanda de las aplicaciones HPC. Características como la memoria LPDDR5X, el diseño de caché coherente unificada (SCF) y una pila de software optimizada basada en GCC contribuyeron a estos resultados.
Como próximos pasos, Petrobras planea portar y comparar sus simuladores geomecánicos y de yacimientos con Arm y explorar todo el potencial de varios superchips NVIDIA Grace para mejorar aún más el tiempo de la solución.
Para obtener más información sobre NVIDIA Grace CPU, vea la sesión on demand de NVIDIA GTC, Aceleración de Solucionadores Lineales en NVIDIA Grace.
Reconocimientos
Este trabajo fue ejecutado por los siguientes ingenieros y analistas: Felipe Portella (Petrobras), José Roberto Pereira Rodrigues (Petrobras), Leonardo Gasparini (Petrobras), Vitor Aquino (CESAR), Luigi Marques da Luz (CESAR).