
La IA generativa ha evolucionado rápidamente de modelos basados en texto a capacidades multimodales. Estos modelos realizan tareas como el subtitulado de imágenes y la respuesta visual a preguntas, lo que refleja un cambio hacia una IA más similar a la humana. La comunidad ahora se está expandiendo de texto e imágenes a video, abriendo nuevas posibilidades en todas las industrias.
Los modelos de IA de vídeo están preparados para revolucionar sectores como la robótica, la automoción y el comercio minorista. En robótica, mejoran la navegación autónoma en entornos complejos y en constante cambio, lo cual es vital para sectores como la manufactura y la gestión de almacenes. En la industria automotriz, la IA de video está impulsando la conducción autónoma, impulsando la percepción, la seguridad y el mantenimiento predictivo del vehículo para mejorar la eficiencia.
Para crear modelos básicos de imagen y vídeo, los desarrolladores deben seleccionar y preprocesar una gran cantidad de datos de entrenamiento, tokenizar los datos de alta calidad resultantes con alta fidelidad, entrenar o personalizar modelos previamente entrenados de forma eficiente y a escala y, a continuación, generar imágenes y vídeos de alta calidad durante la inferencia.
Anunciamos NVIDIA NeMo para IA Generativa Multimodal
NVIDIA NeMo es una plataforma integral para desarrollar, personalizar e implementar modelos de IA generativa.
NVIDIA acaba de anunciar la expansión de NeMo para respaldar el proceso de extremo a extremo para el desarrollo de modelos multimodales. NeMo le permite seleccionar fácilmente datos visuales de alta calidad, acelerar el entrenamiento y la personalización con tokenizadores altamente eficientes y técnicas de paralelismo, y reconstruir imágenes de alta calidad durante la inferencia.
Curación Acelerada de Datos de Vídeo e Imagen
Los datos de entrenamiento de alta calidad garantizan resultados de alta precisión de un modelo de IA. Sin embargo, los desarrolladores se enfrentan a varios desafíos en la creación de pipelines de procesamiento de datos, que van desde el escalado hasta la orquestación de datos.
NeMo Curator agiliza el proceso de curación de datos, lo que facilita y agiliza la creación de modelos de IA generativa multimodales. Su experiencia lista para usar minimiza el costo total de propiedad (TCO) y acelera el tiempo de comercialización.
Al trabajar con objetos visuales, las organizaciones pueden alcanzar fácilmente el procesamiento de datos a escala de petabytes. NeMo Curator proporciona un pipeline de orquestación que puede equilibrar la carga en varias GPU en cada etapa de la curación de datos. Como resultado, puede reducir el tiempo de procesamiento de video en 7 veces en comparación con una implementación ingenua basada en GPU. Los pipelines escalables pueden procesar de manera eficiente más de 100PB de datos, lo que garantiza el manejo sin problemas de grandes conjuntos de datos.
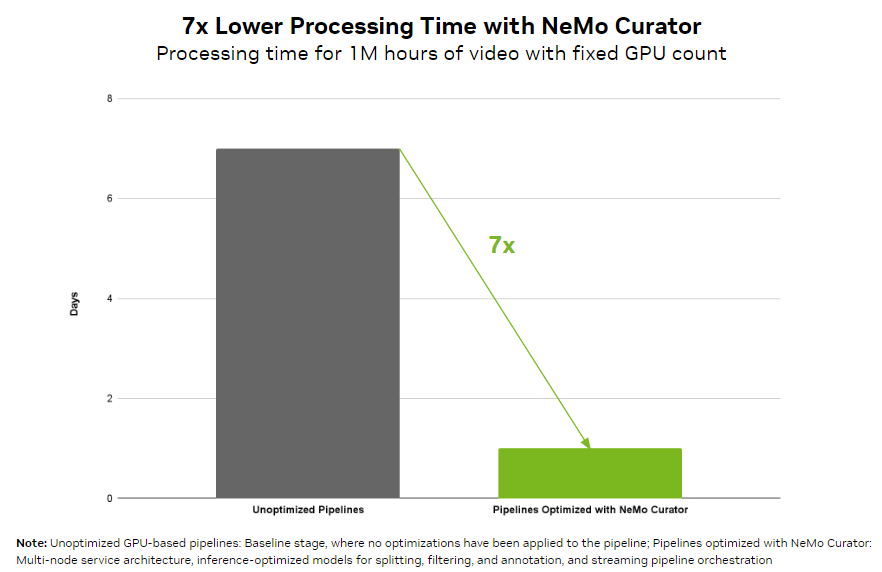
NeMo Curator proporciona modelos de curación de videos de referencia optimizados para etapas de filtrado, subtitulado e incrustación de alto rendimiento para mejorar la calidad del conjunto de datos, lo que le permite crear modelos de IA más precisos.
Por ejemplo, NeMo Curator utiliza un modelo de subtitulado optimizado que ofrece una mejora en el rendimiento de un orden de magnitud en comparación con las implementaciones de modelos de inferencia no optimizados.
Tokenizadores de NVIDIA Cosmos
Los tokenizadores mapean datos visuales redundantes e implícitos en tokens compactos y semánticos, lo que permite un entrenamiento eficiente de modelos generativos a gran escala y democratiza su inferencia en recursos computacionales limitados.
Los tokenizadores de imágenes y videos abiertos de hoy en día a menudo generan representaciones de datos deficientes, lo que lleva a reconstrucciones con pérdidas, imágenes distorsionadas y videos temporalmente inestables y pone un límite a la capacidad de los modelos generativos construidos sobre los tokenizadores. Los procesos de tokenización ineficientes también dan lugar a una codificación y decodificación lentas y a tiempos de entrenamiento e inferencia más largos, lo que afecta negativamente tanto a la productividad de los desarrolladores como a la experiencia del usuario.
Los tokenizadores NVIDIA Cosmos son modelos abiertos que ofrecen una tokenización visual superior con tasas de compresión excepcionalmente grandes y una calidad de reconstrucción de vanguardia en diversas categorías de imágenes y videos.
Vídeo 1. Tokenizadores de IA generativa eficientes para imagen y video
Estos tokenizadores proporcionan facilidad de uso a través de un conjunto de modelos estandarizados de tokenizadores que admiten modelos de lenguaje de visión (VLM) con códigos latentes discretos, modelos de difusión con incrustaciones latentes continuas y varias relaciones de aspecto y resoluciones, lo que permite la gestión eficiente de imágenes y vídeos de gran resolución. Esto le proporciona herramientas para tokenizar una amplia variedad de datos de entrada visual para crear modelos de IA de imagen y video.
Arquitectura del Tokenizador de Cosmos
Un tokenizador de Cosmos utiliza una sofisticada estructura de codificador-decodificador diseñada para una alta eficiencia y un aprendizaje efectivo. En su núcleo, emplea bloques de convolución causal 3D, que son capas especializadas que procesan conjuntamente información espacio-temporal, y utiliza la atención temporal causal que captura dependencias de largo alcance en los datos.
La estructura causal garantiza que el modelo utilice solo fotogramas pasados y presentes al realizar la tokenización, evitando fotogramas futuros. Esto es crucial para alinearse con la naturaleza causal de muchos sistemas del mundo real, como los de la IA física o los LLM multimodales.
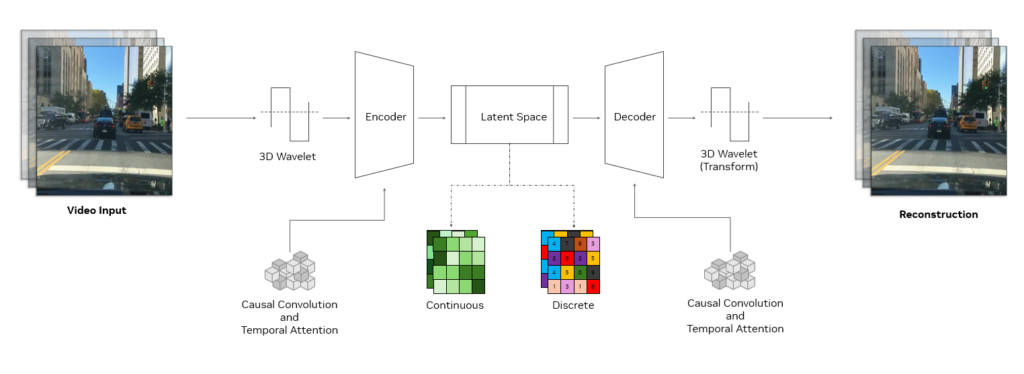
La entrada se reduce mediante ondículas 3D, una técnica de procesamiento de señales que representa la información de los píxeles de manera más eficiente. Una vez procesados los datos, una transformada wavelet inversa reconstruye la entrada original.
Este enfoque mejora la eficiencia del aprendizaje, lo que permite que los módulos aprendibles del codificador-decodificador tokenizador se centren en características significativas en lugar de en detalles de píxeles redundantes. La combinación de tales técnicas y su receta de entrenamiento única hace que los tokenizadores de Cosmos sean una arquitectura de vanguardia para una tokenización eficiente y poderosa.
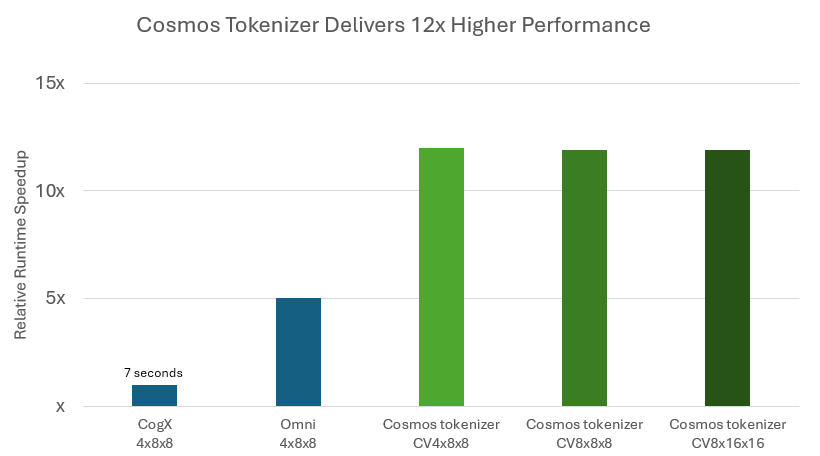
Durante la inferencia, los tokenizadores de Cosmos reducen significativamente el costo de ejecución del modelo al ofrecer una reconstrucción hasta 12 veces más rápida en comparación con los principales tokenizadores de peso abierto (Figura 3).
Los tokenizadores de Cosmos también producen imágenes y videos de alta fidelidad mientras comprimen más que otros tokenizadores, lo que demuestra una compensación de calidad y compresión sin precedentes.
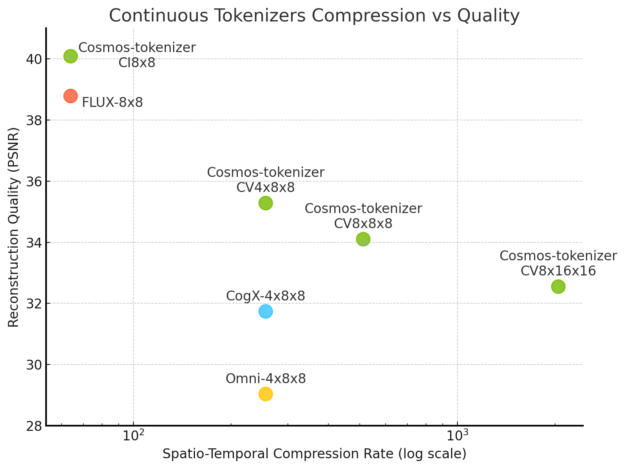
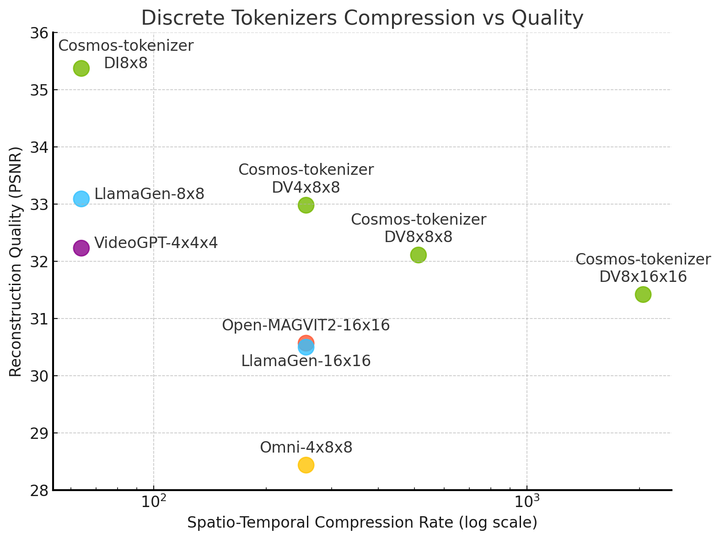
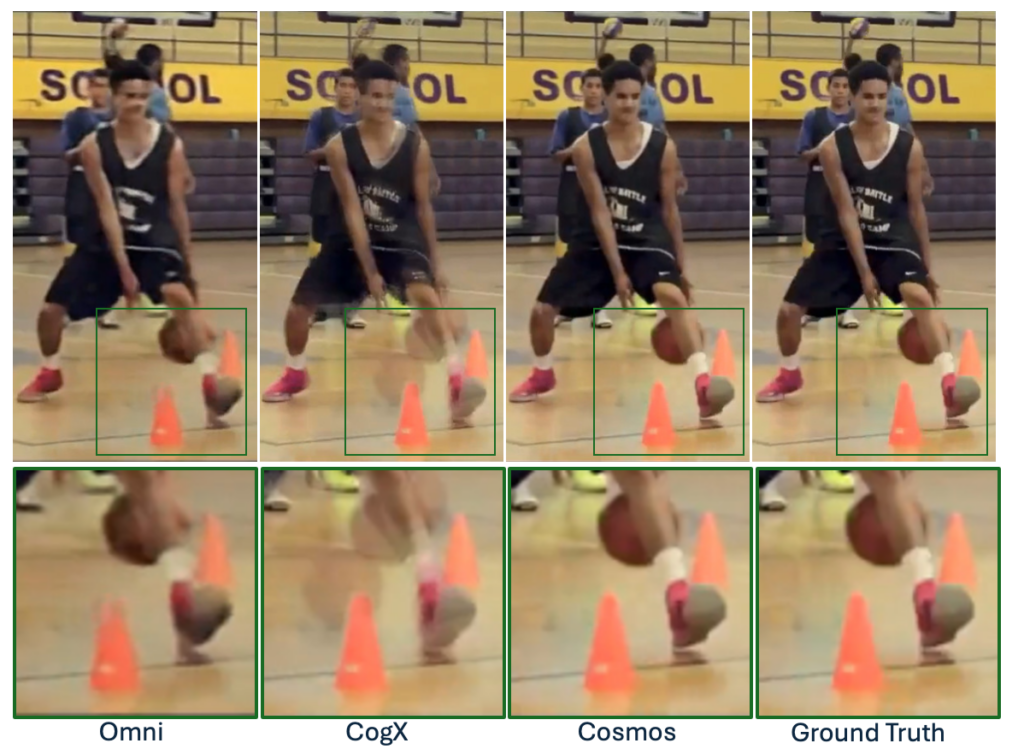
Aunque el tokenizador Cosmos se regenera a partir de tokens altamente comprimidos, es capaz de crear imágenes y videos de alta calidad debido a una innovadora técnica y arquitectura de entrenamiento de redes neuronales.
Construya Sus Propios Modelos Multimodales con NeMo
La expansión de la plataforma NVIDIA NeMo con procesamiento de datos a escala mediante NeMo Curator y la tokenización de alta calidad y la reconstrucción visual mediante el tokenizador Cosmos le permiten crear modelos de IA generativa y multimodales de última generación.
Únase a la lista de espera y reciba una notificación cuando NeMo Curator esté disponible. El tokenizador ya está disponible en el repositorio de GitHub /NVIDIA/cosmos-tokenizer y en Hugging Face.