
Uno de los principales desafíos para los sistemas de generación aumentada de recuperación (RAG) es lidiar con consultas de usuarios que carecen de claridad explícita o tienen una intención implícita. Los usuarios a menudo formulan preguntas de manera imprecisa. Por ejemplo, considere la consulta del usuario: «Cuénteme sobre la última actualización en el entrenamiento del modelo NVIDIA NeMo». Es posible que el usuario esté implícitamente interesado en los avances en las capacidades de personalización de grandes modelos de lenguaje (LLM) de NeMo, en lugar de sus modelos de voz. Sin embargo, esta preferencia no se expresa explícitamente, lo que puede conducir a resultados subóptimos.
Superar estas limitaciones y desbloquear el verdadero potencial de RAG requiere ir más allá de las técnicas básicas. Esta publicación presenta las capacidades de razonamiento de IA de los LLM de NVIDIA Nemotron que mejoran significativamente las canalizaciones de RAG. Vemos un ejemplo de la vida real de cómo aplicamos estrategias avanzadas, como el análisis y la reescritura de consultas, para refinar las capacidades de búsqueda de un motor de consultas.
¿Qué es la reescritura de consultas en RAG?
La reescritura de consultas en RAG es un paso crucial que transforma el mensaje inicial de un usuario en una consulta más optimizada para mejorar la recuperación de información. Este proceso es vital para aumentar el rendimiento de RAG porque cierra la brecha semántica entre cómo un usuario hace una pregunta y cómo se estructura la información en la base de conocimientos. Al refinar la consulta, el sistema puede superar problemas como la inexactitud o la complejidad excesiva, lo que lleva a la recuperación de documentos más precisos y relevantes. Este contexto de alta calidad permite directamente que el modelo de lenguaje genere respuestas más precisas, completas y basadas en hechos.
Han surgido varias técnicas para la reescritura efectiva de consultas, particularmente aprovechando los LLM:
- Q2E (Query2Expand): genera consultas o expansiones semánticamente equivalentes que cubren diferentes formas en que se puede expresar la información del usuario, lo que aumenta la posibilidad de recuperar documentos relevantes.
- Q2D (Query2Doc): Construye un pseudodocumento a partir de la consulta original, que refleja el estilo y el contenido de los pasajes de recuperación. Esto mejora la alineación con la forma en que se almacena la información en el corpus.
- Reescritura de consultas de cadena de pensamiento (CoT): este método utiliza un mensaje específico que indica al LLM que proporcione lógica paso a paso, dividiendo la consulta original y elaborando el contexto relacionado antes de proporcionar la consulta expandida. En lugar de reescribir la consulta directamente, las indicaciones de método generan explicaciones lógicas detalladas que tienden a incluir un amplio conjunto de palabras clave relevantes incorporadas naturalmente en el razonamiento.
Al emplear estas técnicas, los sistemas RAG pueden reestructurar preguntas mal formadas, introducir palabras clave vitales y anclar las consultas de los usuarios más estrechamente en la semántica del corpus, elevando sustancialmente la calidad de la búsqueda y la respuesta.
Para incorporar la técnica de reescritura de consultas en RAG, el mensaje debería adaptarse específicamente a los casos de uso de RAG. A continuación, se muestran algunos ejemplos de indicaciones para cada método:
Q2E Prompt
Your task is to brainstorm a set of useful search terms and related key phrases that could help locate information
about the following question. Focus on capturing alternate expressions, synonyms, and specific entities or events
mentioned in the query.
Original Question: {query}
Related Search Keywords:
Q2D Prompt
Imagine you are composing a short informative article that directly addresses a given question. Write a detailed passage
that would help someone fully understand the subject or find an answer to the query.
Query: {query}
Passage:
Prompt de reescrita de consulta CoT
Please carefully consider the following question. First, break down what the question is asking and think through any
relevant facts, possible interpretations, or required background knowledge. Then, list out important words, concepts, or
phrases that emerge from your reasoning process, which could help retrieve detailed answers.
Question: {query}
Your step-by-step reasoning and expansion terms:
¿Cómo avanzan los modelos NVIDIA Nemotron en RAG?
La familia NVIDIA Nemotron de modelos multimodales y de razonamiento se basa en la familia Meta Llama para proporcionar un conjunto de LLM optimizados para la eficiencia, el rendimiento y las aplicaciones avanzadas como RAG y agencia. Los modelos Nemotron son una familia abierta de modelos de IA avanzados diseñados para proporcionar sólidas capacidades de razonamiento, alta eficiencia e implementación flexible para agentes de IA empresariales. Disponibles en tamaños Nano, Super y Ultra, estos modelos combinan la arquitectura Meta Llama con las extensas técnicas posteriores al entrenamiento de NVIDIA para lograr la máxima precisión en los puntos de referencia de la industria.
Entre la familia de modelos Nemotron, descubrimos que el modelo Llama 3.3 Nemotron Super 49B v1 es más adecuado para el caso de uso para impulsar avances en RAG, particularmente considerando la latencia de inferencia y la capacidad de razonamiento adecuada. Los resultados del conjunto de datos de preguntas naturales (NQ) muestran claramente que la reescritura de consultas mejora significativamente la precisión de la recuperación. Accuracy@K indica la fracción de preguntas en las que se encuentra una respuesta correcta en los pasajes recuperados de la K superior.

Arquitectura para tubería RAG con Llama Nemotron
La Figura 1 muestra la arquitectura de un proceso RAG mejorado con el Llama 3.3 Nemotron Super 49B v1.
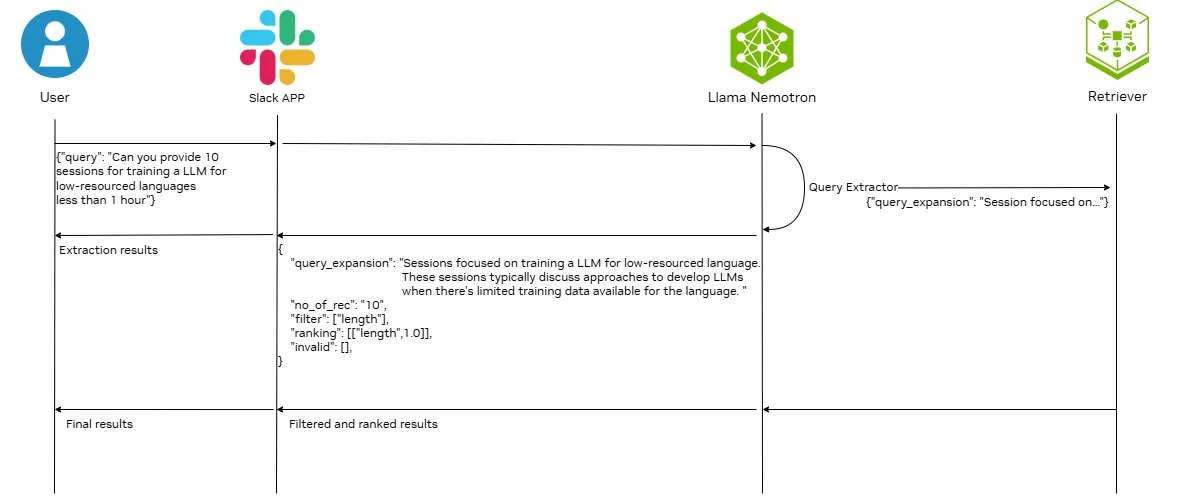
En la arquitectura, el modelo Llama Nemotron se utiliza como extractor de consultas con las siguientes funciones:
- Analice la consulta del usuario para extraer la consulta principal. Este paso refina la consulta del usuario para excluir frases innecesarias y que distraen, que probablemente afecten negativamente al resultado de la recuperación.
- Analice la consulta del usuario para extraer los criterios de filtrado u ordenación disponibles. Los criterios de filtrado extraídos se pueden utilizar para la investigación de recuperación híbrida o como entrada a un modelo de reclasificación para realizar un filtrado cualitativo. Los criterios de clasificación extraídos permiten a los usuarios establecer otros criterios de clasificación, excepto la relevancia.
- Expanda la consulta principal agregando información contextual relacionada. Este proceso puede incluir técnicas como la generación de paráfrasis, la división de consultas complejas en subpreguntas o la adjuntación de contexto de fondo. Expandir las consultas de esta manera es beneficioso porque mejora la precisión de la recuperación, especialmente cuando las consultas de los usuarios son ambiguas o incompletas.
- Pase la consulta expandida a NVIDIA NeMo Retriever para una ingesta, incorporación y reclasificación aceleradas.
Slack está integrado en el backend con Slack para permitir la integración con aplicaciones adicionales y eliminar la necesidad de desarrollar y mantener un frontend tradicional. Varios componentes clave garantizan una comunicación fluida entre los usuarios de Slack y el backend, que incluyen:
- Manejo de eventos en tiempo real: SocketModeHandler permite el manejo de eventos en tiempo real, lo que garantiza una comunicación fluida entre los usuarios de Slack y el backend.
- Configuración modular de bots: para cargar componentes, conectarse a la lógica central y configurar controladores de eventos y registros.
- Experiencia de usuario interactiva organizada: para mejorar la experiencia del usuario publicando todas las respuestas como mensajes encadenados para minimizar el desorden y mantener las conversaciones organizadas.
Para los fines de esta publicación, la arquitectura que se muestra en la Figura 1 se aplica para ayudar a mejorar los resultados de búsqueda de las sesiones de NVIDIA GTC 2025. La reescritura de consultas garantiza que la búsqueda de similitud semántica recupere un conjunto de sesiones más enfocado. Esto se explica con ejemplos en la siguiente sección.
Cómo refinar un motor de consulta de búsqueda con funciones de razonamiento
Uno de los desafíos clave que destaca la necesidad de reescribir consultas en un workflow RAG es la brecha semántica entre el lenguaje de los usuarios y el vocabulario de contenido. Por ejemplo, considere la consulta del usuario, «Sesiones para entrenar un LLM para un lenguaje con pocas funciones». El desafío en esta consulta es la frase «lenguaje con pocos recursos».
Con esta consulta, el usuario busca sesiones sobre sesiones relacionadas con la formación de LLMs multilingües o IA soberana. Si bien varias sesiones de GTC 2025 discuten este tema, ninguna de ellas usa la frase clave «lenguaje con pocos recursos». En cambio, las frases más comunes incluyen «multilingüe», «no inglés», «IA soberana» o idiomas específicos como «coreano» o «francés». Por este motivo, es poco probable que el uso de la consulta original para recuperar y ordenar las sesiones relevantes produzca un resultado satisfactorio.
Para resolver este problema, adoptamos técnicas de Q2E para reescribir las consultas. En este caso de usuario, la reescritura de consultas Q2D y COT no es adecuada porque la consulta del usuario será específica del dominio y el LLM de propósito general no tiene conocimiento sobre la creación de pseudodocumentos o contexto para la consulta del usuario, lo que genera una alta probabilidad de alucinación de LLM. A continuación se muestra un ejemplo de solicitud de Q2E para este caso de uso.
## Instruction
### Goal
You are given a user query about querying for GTC sessions. Your task is to determine what topic or particular sessions
the user is looking for.
### Steps
1. You should first extract the major request from the user query.
– Understand the main search target in the user query, make sure you know what the user is looking for
– Pay attention to all the details or keywords that are relevant to the main search target and include them.
Please note that it is possible that the user will place the relevant keywords anywhere in the query but not necessarily
right next to the main search target. Please relate ALL relevant search keywords and complete the main search query.
– Include ALL non-filter/non-ranking **descriptive phrases** in `main_query` even if they don’t match available
criteria, but **Remove subjective descriptors** like «promising» in `main_query`
– EXCLUDE ALL the filtering and ranking criteria
– **Remove event references** (e.g., «GTC», «SIGGRAPH») from `main_query` even if they appear mid-phrase
2. Provide your understanding/explanation on the main query extracted.
– Write **EXACTLY 1-3 sentences** describing ONLY what the sessions are about, based strictly on the literal words
in `main_query`.
– Use this template:
`»Sessions focused on [exact field from main_query]. These sessions typically discuss [general description of what
such sessions typically cover, elaborating on all KEY PHRASES from the main_query. Where appropriate, briefly mention
common goals, benefits, or general approaches relevant to the topic, as long as they are directly related to the key
phrases and align with common understanding in the field.].»`
– **Do NOT mention any specific techniques, challenges, industries, methods, or examples unless they are explicitly stated
in the main_query.**
– **Do NOT add or infer information that is not present or clearly implied in the main_query.**
– **Elaborate on each key phrase in the main_query, providing context or typical session content that aligns with standard
interpretations in the AI/tech field.**
– **Ensure your explanation is clear, human-like, and aligns with normal human perception and expectations for such
sessions.**
– **Do NOT include any preamble, reasoning, or formatting other than the explanation sentence(s).**
– **Example**:
– User query 1: «Sessions about enabling AI-recommended knowledge articles for customer service agents»
– Explanation 1: «Sessions focused on enabling AI-recommended knowledge articles for customer service agents.
These sessions typically discuss how AI can recommend relevant articles in real time to help agents resolve customer
issues more efficiently.»
– User query 2: «Any sessions that introduce large language models (LLMs) and their applications?»
– Explanation 2: «Sessions focused on introducing large language models (LLMs) and their applications. These sessions
typically discuss what LLMs are, how they are developed, and their uses in tasks like text generation, translation,
and summarization.»
– User query 3: «Sessions on AI ethics and societal impact in technology»
– Explanation 3: «Sessions focused on AI ethics and societal impact in technology. These sessions typically discuss
ethical considerations in AI development and the broader effects of AI technologies on society.»
### Output
Output as the following JSON format
{{
«main_query»: «», // string of major requests from the user query. Be as concise as possible while capturing all
the descriptive phrases.
«main_query_explanation»: «», // Understanding/explanation on what kind of sessions the user is looking for
based on the main query
}}
## User query
{query}
## Your Final output
«`json
{{
YOUR OUTPUT
}}
«`
Para la consulta de ejemplo, «Sesiones para entrenar un LLM para un lenguaje de bajos recursos», expandir la consulta puede aumentar significativamente la clasificación de las sesiones más relevantes devueltas por un recuperador en función de la similitud semántica. En el cuadro 2 se proporcionan más detalles.
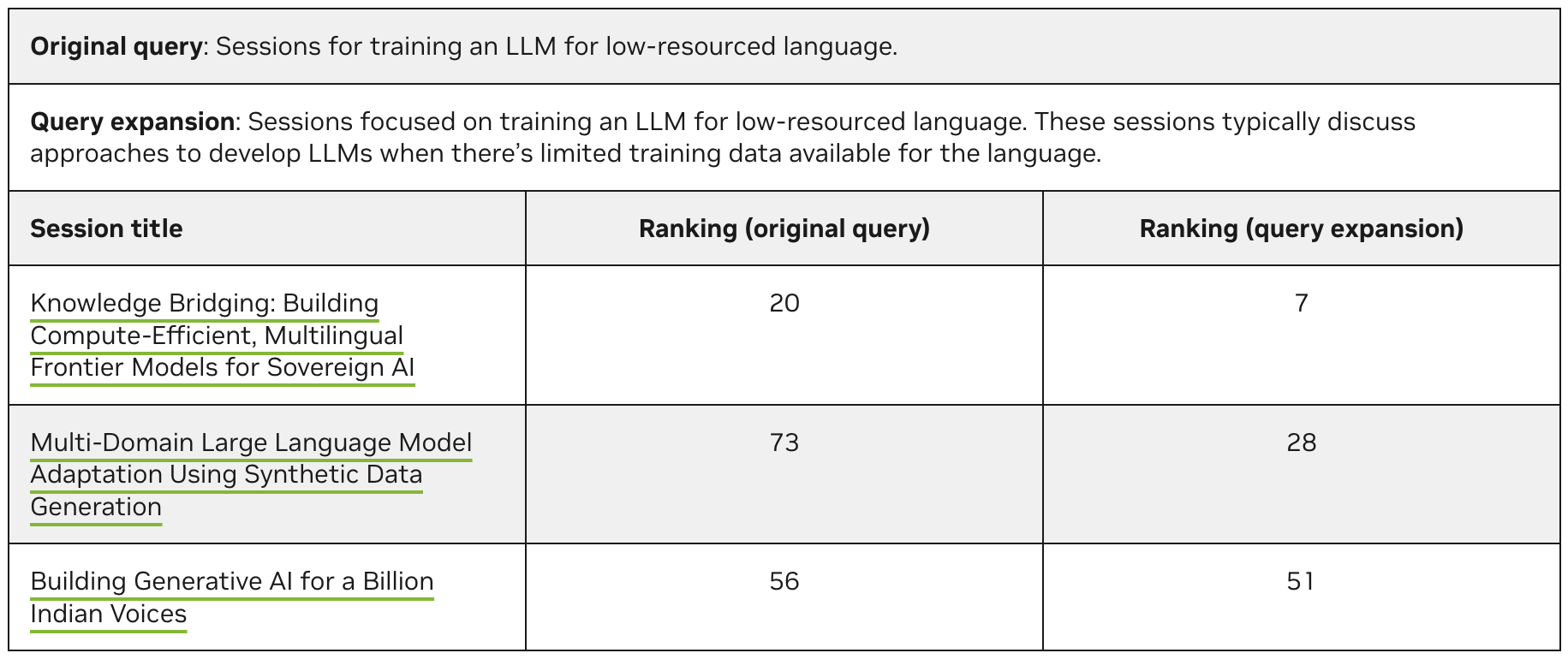
Además, la expansión de la consulta ayuda al reclasificador a centrarse en un ámbito más amplio pero muy relevante durante el proceso de clasificación. Por ejemplo, el token de pensamiento lógico truncado del modelo Llama Nemotron con una consulta diferente:
- Consulta original: «Las frases clave son ‘entrenamiento’, ‘LLM’ y ‘lenguaje de bajos recursos'»
- Expansión de la consulta: «Las frases clave son ‘lenguaje con pocos recursos’, ‘datos de entrenamiento limitados’, ‘multilingüe’, ‘adaptación de dominio’, etc.»
Tenga en cuenta que con la expansión de consultas, el reclasificador está mejor equipado para identificar sesiones que analizan conceptos relacionados, incluso si no usan los términos de consulta originales exactos. Esta perspectiva más amplia permite al reclasificador crear una clasificación más completa y centrada en el usuario mediante la presentación de sesiones que proporcionan una comprensión más profunda de la necesidad general de información del usuario.
¿Cuáles son los beneficios de la reescritura de consultas?
Al mejorar los resultados de búsqueda a través de la reescritura de consultas, la canalización mejorada proporciona una ventaja convincente sobre los enfoques RAG tradicionales. La principal ventaja proviene de la reformulación inteligente de las consultas de los usuarios. Esto agrega contexto y detalles cruciales. Este paso es responsable de crear un grupo de candidatos de alta calidad y altamente relevantes, que es el factor más importante para mejorar el rendimiento del sistema.
¿Cuáles son los desafíos de este enfoque?
La reescritura de consultas requiere inferencia de IA, que consume muchos recursos y es más lenta que los métodos tradicionales, lo que limita la escalabilidad. Además, los LLM solo pueden procesar un número limitado de documentos a la vez, lo que requiere estrategias de ventana deslizante para grandes grupos de solicitantes. Esto aumenta la complejidad y puede socavar la calidad de la clasificación global.
Cuándo optimizar una canalización de RAG
Esta canalización RAG mejorada es especialmente valiosa en dominios donde la exactitud y la precisión son más importantes que la velocidad, como se detalla en la Tabla 3.

Comience a mejorar sus canalizaciones de RAG
En esta publicación, presentamos un enfoque innovador para mejorar las canalizaciones RAG utilizando las capacidades de razonamiento de la familia de modelos NVIDIA Llama Nemotron. Al abordar las limitaciones de los métodos tradicionales, esta arquitectura mejorada permite un acceso a la información más eficaz y centrado en el usuario, especialmente en escenarios que requieren una alta precisión y una comprensión matizada.
Para obtener más información sobre todas las características de la colección de modelos LLM de Llama Nemotron, consulte Creación de agentes de IA empresarial con modelos de razonamiento avanzado de NVIDIA Llama Nemotron. Puede probar los modelos NVIDIA NIM en el catálogo de API de NVIDIA. Mejora y acelera aún más tus canalizaciones RAG con NVIDIA NeMo Retriever y el proyecto NVIDIA RAG.