
El paradigma de la computación de consumo ha girado en torno al concepto de dispositivo personal —desde PCs hasta smartphones y tablets. Ahora, la IA generativa —particularmente OpenClaw— ha introducido una nueva categoría: las computadoras de agentes (agent computers). Estos dispositivos, como la supercomputadora de escritorio para IA NVIDIA DGX Spark o las PCs dedicadas NVIDIA RTX, son ideales para ejecutar agentes personales de manera privada y gratuita.
NVIDIA GTC, que se celebra esta semana, presenta una serie de anuncios sobre IA agéntica, que incluyen:
-
Nuevos modelos abiertos para agentes locales, incluyendo NVIDIA Nemotron 3 Nano 4B y Nemotron 3 Super 120B, además de optimizaciones para Qwen 3.5 y Mistral Small 4.
-
NVIDIA NemoClaw, una pila (stack) de código abierto para OpenClaw que optimiza las experiencias en dispositivos NVIDIA, aumentando la seguridad y admitiendo modelos locales.
-
Ajuste fino (fine-tuning) simplificado con Unsloth Studio, para mejorar aún más la precisión de los modelos abiertos en flujos de trabajo agénticos.
Los asistentes presenciales a la GTC pueden visitar el evento «NVIDIA build-a-claw» en el GTC Park, que se lleva a cabo diariamente hasta el 19 de marzo, de 8 a.m. a 5 p.m. Expertos de NVIDIA ayudarán a los invitados a personalizar e implementar un asistente de IA proactivo y «siempre encendido» utilizando el dispositivo de su elección. Ya sean técnicos o simplemente curiosos, los participantes bautizarán a su agente, definirán su personalidad y le otorgarán acceso a las herramientas que necesite, creando un asistente personal accesible desde su aplicación de mensajería preferida.
Nuevos modelos abiertos brindan calidad de nivel de nube a los agentes locales
La próxima generación de modelos locales —con ventanas de contexto cada vez más amplias— ofrece la inteligencia necesaria para ejecutar agentes en la PC. Combinados con un contexto de usuario más rico y potentes herramientas locales, estos avances están desbloqueando nuevas posibilidades en las PCs con IA, especialmente en la DGX Spark, con sus 128 GB de memoria unificada que admite modelos con más de 120 mil millones de parámetros.
Nemotron 3 Super, lanzado la semana pasada, es un modelo abierto de 120 mil millones de parámetros con 12 mil millones de parámetros activos, diseñado para ejecutar sistemas complejos de IA agéntica. Es óptimo para alimentar agentes en la DGX Spark o en estaciones de trabajo NVIDIA RTX PRO. En PinchBench —un nuevo referente (benchmark) para determinar qué tan bien funcionan los grandes modelos de lenguaje con OpenClaw— Nemotron 3 Super obtuvo un 85,6%, convirtiéndose en el mejor modelo abierto de su clase.
Mistral Small 4, un modelo abierto de 119 mil millones de parámetros con 6 mil millones de parámetros activos (8 mil millones incluyendo todas las capas), unifica las capacidades de los modelos insignia de Mistral. Los usuarios disponen ahora de un modelo ultraeficiente optimizado para chat general, programación y tareas agénticas. Ambos modelos se ejecutan localmente en GPUs DGX Spark y RTX PRO.
Para los usuarios de GeForce RTX que buscan modelos más pequeños, Nemotron 3 Nano 4B es el modelo más reciente en unirse a la familia NVIDIA Nemotron 3, proporcionando un punto de partida compacto y capaz para crear agentes y asistentes localmente en PCs con IA RTX. El modelo es ideal para crear identidades conversacionales que ejecuten acciones en juegos y aplicaciones con hardware de recursos limitados. Está disponible en cualquier sistema con GPU NVIDIA y combina el seguimiento de instrucciones de vanguardia con un uso excepcional de herramientas y un consumo mínimo de VRAM.
Además, NVIDIA anunció optimizaciones para los modelos Qwen 3.5 de Alibaba, que han demostrado una precisión sobresaliente (27B, 9B y 4B) y son adecuados para ejecutar agentes locales en GPUs NVIDIA. Los nuevos modelos admiten de forma nativa visión, predicción de múltiples tokens y una amplia ventana de contexto de 262,000 tokens. El modelo denso de 27 mil millones de parámetros destaca al combinarse con una GPU RTX 5090.
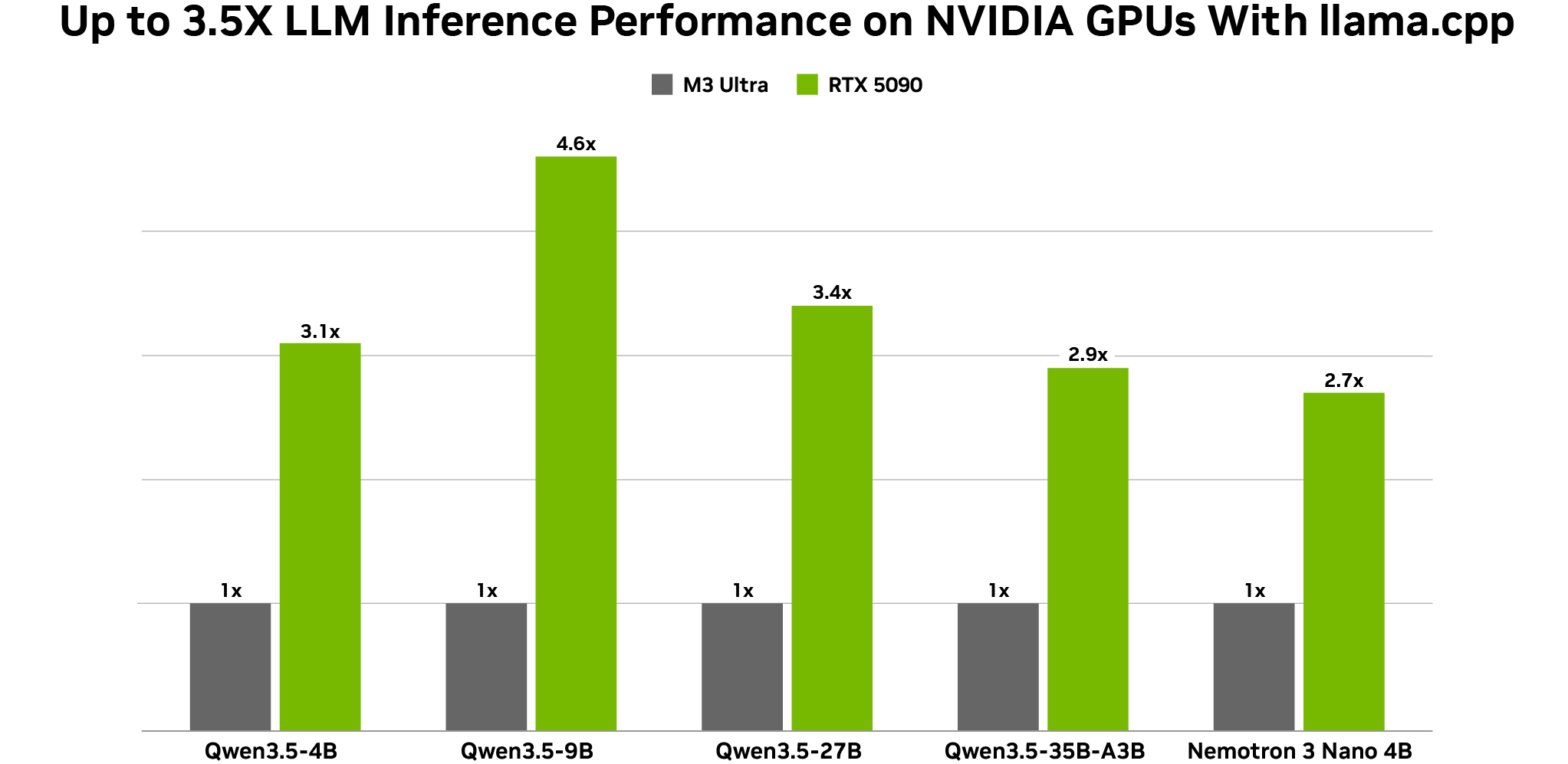
Los usuarios pueden probar estos modelos hoy mismo a través de Ollama, LM Studio y llama.cpp, con inferencia acelerada mediante GPUs RTX y DGX Spark.
IA creativa más rápida con los últimos modelos optimizados para RTX
LTX 2.3, el modelo de audio y video de última generación de Lightricks lanzado a principios de este mes, ahora cuenta con soporte para modelos destilados NVFP4 y FP8, acelerando el rendimiento en 2.1x.
Además, FLUX.2 Klein 9B de Black Forest Lab recibió una actualización la semana pasada, acelerando la edición de imágenes hasta 2 veces. NVIDIA ha colaborado con Black Forest Labs para lanzar una versión FP8, optimizada para el rendimiento más rápido y un consumo de memoria óptimo en GPUs RTX.
NVIDIA NemoClaw — Optimizaciones de NVIDIA para OpenClaw
Los desarrolladores y entusiastas de la IA están adquiriendo supercomputadoras DGX Spark o construyendo PCs RTX dedicadas para ejecutar agentes de IA autónomos, como OpenClaw, que obtienen contexto de archivos personales, aplicaciones y flujos de trabajo, y pueden automatizar tareas diarias. Sin embargo, a medida que crece la adopción de sistemas agénticos, también aumentan las preocupaciones sobre los costos de tokens, así como la seguridad y la privacidad.
Para abordar estas inquietudes, NVIDIA presentó esta semana NemoClaw, una pila de código abierto que despliega optimizaciones para OpenClaw en dispositivos NVIDIA. Las primeras funciones disponibles en NemoClaw son los modelos abiertos NVIDIA Nemotron y el entorno de ejecución (runtime) NVIDIA OpenShell. Los modelos locales Nemotron permiten realizar inferencias localmente, lo que significa mayor privacidad y sin costos de tokens. OpenShell es el runtime diseñado para ejecutar los «claws» (agentes) de forma más segura.
Ajuste fino (Fine-Tuning) facilitado con Unsloth Studio
A medida que los modelos abiertos dan pasos agigantados, una forma de mejorar aún más la precisión es el ajuste fino, que permite personalizar un modelo para datos y casos de uso propios. Esta técnica normalmente requiere experiencia técnica profunda y programación compleja. Unsloth, una biblioteca líder de código abierto para el ajuste y alineación de modelos, lanzó hoy Unsloth Studio, una interfaz de usuario web fácil de usar que simplifica el proceso.
Unsloth Studio ofrece soporte para más de 500 modelos de IA. La interfaz facilita el entrenamiento: los usuarios solo tienen que soltar su conjunto de datos, tocar el lienzo basado en gráficos para generar datos sintéticos adicionales de alta calidad e iniciar la tarea de ajuste fino. Admite QLoRA, LoRA y ajuste fino completo. A medida que se ajusta el modelo, los usuarios pueden monitorear y visualizar el progreso. Finalmente, pueden exportar el modelo al marco de trabajo (framework) de su elección.
La nueva interfaz de Unsloth Studio se basa en la biblioteca Unsloth, que ofrece un entrenamiento hasta 2 veces más rápido con ahorros de hasta un 70% de VRAM. Esto significa que los nuevos usuarios pueden aprovechar al máximo sus GPUs NVIDIA RTX y DGX Spark desde el primer momento.
#ICYMI de GTC 2026
-
✨ Guía de generación de video con IA RTX: Utiliza flujos de texto a imagen en ComfyUI para crear videos en 4K localmente. Comparte con #AIonRTX.
-
💿 NVIDIA AI for Media: Actualización de SDKs para efectos de IA (Broadcast) en medios en vivo. Incluye sincronización de labios más precisa y escalado 4K más rápido en GPUs RTX Serie 40 y 50.
-
💻 NVIDIA DLSS 5: Disponible este otoño, ofrece un avance en fidelidad visual para juegos mediante iluminación y materiales fotorrealistas impulsados por IA.
-
🤖 Maxon Redshift 2026.4: Nuevo flujo de trabajo de visualización en tiempo real potenciado por DLSS para arquitectura.
-
🪟 Reincubate Camo: Añadió Windows ML en NVIDIA TensorRT para AI Autotune, mejorando el rendimiento en GPUs RTX.