
La IA está evolucionando y los modelos de razonamiento están aumentando la demanda de tokens, lo que genera nuevos requisitos en cada capa de la infraestructura de IA. Más que nunca, la computación debe escalar de manera eficiente para maximizar la producción de tokens y mejorar la productividad para los creadores de modelos y usuarios.
Las GPU modernas operan a su capacidad máxima, lo que eleva el rendimiento con cada generación, pero el desempeño del sistema está cada vez más limitado por las tareas en serie vinculadas a la CPU dentro de un bucle agéntico, un ejemplo clásico de un principio central de la ciencia de la computación, llamado ley de Amdahl.
Esta dinámica es especialmente visible en dos clases de cargas de trabajo: el aprendizaje por refuerzo (RL) para entrenar modelos con nuevas habilidades especializadas, como codificación o ingeniería, y las acciones agénticas, que permiten a los agentes de IA usar herramientas como navegadores web, bases de datos, intérpretes de código y otro software para completar tareas en entornos reales o sandboxes.
Ambas cargas de trabajo combinan dos características de CPU históricamente separadas. Los entornos individuales requieren un sólido desempeño de un solo subproceso para ejecutar código complejo rápidamente, de un modo similar al de una estación de trabajo. Al mismo tiempo, los sistemas de IA modernos lanzan miles de estos entornos simultáneamente, lo que crea demandas de rendimiento a gran escala típicas de la infraestructura de servidores.
La CPU NVIDIA Vera está diseñada para cargas de trabajo de IA modernas, con características de diseño clave como:
- Desempeño extremo de un solo núcleo: La ejecución rápida de tareas individuales es crítica, y el desempeño debe mantenerse bajo carga constante con muchas tareas agénticas y usuarios simultáneos.
- Alta memoria y ancho de banda de estructura por núcleo: Para garantizar un SLA consistente bajo carga que mueva volúmenes de datos de manera eficiente para tareas de análisis en tiempo real y cambio de contexto.
- Diseño conjunto eficiente a escala de bastidor: Las fábricas de IA deben implementar y administrar rápidamente la capacidad para cumplir con la demanda de los agentes, a la vez que maximizan la eficiencia energética.
Los centros de datos desarrollados con Vera maximizan las inversiones en infraestructura de IA, ya sea que las CPU Vera estén conectadas directamente a los aceleradores o realicen tareas con capacidad de CPU independiente en el otro extremo.
La realidad del posentrenamiento
El aprendizaje por refuerzo requiere que los modelos evalúen constantemente sus resultados, reconociendo qué resultados tienen éxito o fracasan. Por ejemplo, los modelos que aprenden a desarrollar software generan grandes cantidades de código mediante modelos que se ejecutan en aceleradores, que luego se envía a clústeres de CPU para desarrollar, ejecutar y probar, actuando en un bucle de retroalimentación y recompensa (ver la figura 1).
Estas tareas abarcan la investigación de bases de código, la compilación, la ejecución en tiempo real, la creación de scripts, la conversión de datos y otras operaciones comunes. En general, este flujo requiere muchos entornos simultáneos similares a sandboxes, cada uno con un complemento completo de herramientas. A menudo, un solo núcleo de CPU ejecuta cada caso de pocos subprocesos de extremo a extremo a partir de un conjunto de solicitudes generadas por aceleradores.

Para maximizar la utilización de aceleradores y hacer cumplir la iteración rápida de modelos, las fases de generación y entrenamiento de tokens del ciclo operan con un cronograma (o política) estricto. A menudo, algunos trabajos de evaluación que se ejecutan en una CPU terminan demasiado tarde para influir en el siguiente paso del ciclo. Cuando esto sucede, el modelo tarda más en alcanzar el mismo nivel de calidad y se desperdician tokens valiosos.
Los bucles de agentes exigen una combinación única de alto desempeño de un solo núcleo, ancho de banda de datos masivo y ejecución determinista con latencias de cola mínimas de las CPU que emplean.
Estos requisitos son un enfoque central del diseño de las CPU NVIDIA Vera (Figura 2), que ofrece un desempeño de sandbox hasta un 50 % más rápido en comparación con las plataformas competitivas, 1.2 TB/s de ancho de banda de memoria y 88 núcleos Olympus con NVIDIA Spatial Multithreading (SMT) para la concurrencia de tareas necesaria para las fábricas de IA.

Núcleo NVIDIA Olympus
La necesidad de núcleos de mayor desempeño para admitir la IA llevó al núcleo NVIDIA Olympus, el primer núcleo de CPU de centros de datos completamente personalizado de NVIDIA. Olympus debuta en Vera junto con la segunda generación de la estructura de coherencia escalable (SCF) de NVIDIA, desarrollada originalmente para la CPU NVIDIA Grace.
Diseñado para una operación de alto nivel de instrucciones por ciclo (IPC) sostenida en cargas de trabajo de memoria intensiva con lógica de flujo de control, Olympus utiliza un frontend de decodificación y captación de instrucciones de 10 vías de ancho, y un predictor de ramificación neuronal capaz de evaluar dos ramas tomadas por ciclo. Es completamente compatible con el conjunto de instrucciones Arm v9.2 y el software existente para un alto desempeño en contenedores, binarios, bibliotecas y sistemas operativos basados en Arm.
Los usuarios pueden elegir entre el desempeño por subproceso y la cantidad de subprocesos en tiempo de ejecución con NVIDIA SMT. Esto le da a cada subproceso un desempeño estable, un aislamiento más fuerte y una latencia de cola predecible bajo cargas pesadas. El SMT tradicional se basa en recursos con tiempo compartido y en la conmutación contextual frecuente entre subprocesos, lo que introduce la variación de desempeño.
NVIDIA SCF y subsistema de memoria
La CPU Vera se basa en un solo chip y una sola estructura de computación monolítica, con dielets adyacentes que implementan subsistemas de memoria y E/S, a la vez que preservan la uniformidad de la topología de computación.
Desde el punto de vista de una aplicación, cada núcleo tiene la misma distancia práctica a recursos como otros núcleos, cachés, memoria y redes, y se aprovisiona con un ancho de banda uniforme y de alto rendimiento. La mayoría de las operaciones sensibles a la latencia siguen siendo locales, lo que evita el tráfico innecesario entre chips que se observa normalmente en las CPU tradicionales
La ruta en tiempo de ejecución de las tareas de agentes, las operaciones de análisis, las cachés de KV y blob, la orquestación y los planos de control son inherentemente impredecibles en una fábrica de IA. En las implementaciones tradicionales, la topología del procesador y los patrones de uso de las tareas vecinas que se ejecutan en él deben considerarse con antelación para maximizar el desempeño de las aplicaciones. El diseño permite un desempeño óptimo sin este estilo de ajuste.
El SCF de segunda generación conecta los 88 núcleos de Olympus a un subsistema de caché L3 y memoria compartido, lo que ofrece una latencia consistente y 3.4 TB/s de ancho de banda de bisección, lo que permite a la CPU Vera mantener más del 90 % del ancho de banda de memoria máximo bajo carga. Cada núcleo cuenta con hasta 14 GB/s de ancho de banda de memoria, aproximadamente el triple de la tasa por núcleo de las CPU tradicionales de centros de datos, lo que garantiza que Extraer-Transformar-Cargar (ETL), el análisis en tiempo real y las cargas de trabajo vinculadas a la memoria mantengan el rendimiento cuando cada núcleo está activo.
Alimentando al SCF se encuentra el subsistema de memoria LPDDR5X de segunda generación de Vera, que ofrece hasta 1.2 TB/s de ancho de banda total con menos de la mitad de la potencia de memoria de las configuraciones de DDR tradicionales y hasta 1.5 TB de capacidad, un aumento de 3 veces en comparación con la generación anterior. Los Small Outline Compression-Attached Memory Modules (SOCAMM) llevan la memoria de bajo consumo al centro de datos por primera vez, reemplazando la memoria soldada con módulos desmontables y actualizables que combinan la eficiencia de LPDDR con una capacidad de servicio de nivel de servidor.
Desempeño en toda la fábrica de IA
Todos estos elementos arquitectónicos permiten a la CPU Vera ofrecer hasta 1.5 veces el desempeño del sandbox agéntico bajo una carga de zócalo completo, en comparación con plataformas x86 competitivas, en compiladores, herramientas de scripts, motores de tiempo de ejecución, conversión de texto, compresión y llamadas a herramientas agénticas (Figura 3).

Esta ventaja se potencia en tres dimensiones. En el posentrenamiento de RL, un sandbox 1.5 veces más rápido arroja resultados de evaluación dentro de ventanas de tiempo más estrechas, lo que permite a los modelos capturar los mejores tokens de gradiente y acelera los ciclos de entrenamiento.
En la inferencia agéntica, reduce el tiempo de espera de los usuarios, lo que mejora la utilización de aceleradores y alivia la presión sobre la descarga de caché de KV.
Para los problemas de entrenamiento de vanguardia, un desempeño de un solo núcleo un 50 % mayor significa que se completan más pruebas secuenciales antes de alcanzar los límites de tiempo, lo que expande la gama de problemas difíciles de los que un modelo puede aprender.
Entornos de agentes por bastidor
Cada fábrica de IA requiere millones de núcleos de CPU para habilitar el bucle de agentes de RL y el uso de herramientas. Para habilitar el potencial de la infraestructura de IA, la implementación debe ser rápida. Para muchos operadores de fábricas de IA, la CPU Vera será la primera en su flota, llegando a los centros de datos diseñados para alta potencia de bastidor y refrigeración líquida.
El nuevo bastidor de CPU NVIDIA Vera ofrece una densidad y un desempeño increíbles dentro de las mismas restricciones de planificación, infraestructura de bastidor, refrigeración y energía que los productos NVL72 que se implementan en la actualidad.
Con una capacidad de más de 22,000 sandboxes, el bastidor de CPU Vera ofrece más de 4 veces la capacidad y dos veces el desempeño por vatio de los bastidores de servidores basados en x86 (Figura 4). Las fábricas de IA implementan y administran la capacidad a nivel de bastidor, lo que reduce radicalmente los tiempos de desarrollo y mejora el tiempo de lanzamiento al mercado de nueva capacidad, a la vez que simplifica la planificación de sitios.
Cada CPU Vera está conectada con las SmartNIC NVIDIA BlueField-4 que contienen núcleos de administración dedicados basados en Grace, lo que descarga tareas de red como la seguridad y la administración, y garantiza que la capacidad de mejor desempeño del sistema esté completamente disponible para tareas agénticas.

Plataformas y configuraciones de Vera
Además del bastidor de CPU Vera, NVIDIA ha diseñado una familia completa de plataformas basadas en Vera para las diversas cargas de trabajo de las fábricas de IA modernas. Al ofrecer muchas opciones de densidades, capacidades de refrigeración, configuraciones y factores de forma, el diseño y los socios de sistemas de Vera están permitiendo una implementación rápida y el aumento de capacidad, adaptables a las limitaciones de espacio disponible en cualquier instalación de centros de datos.
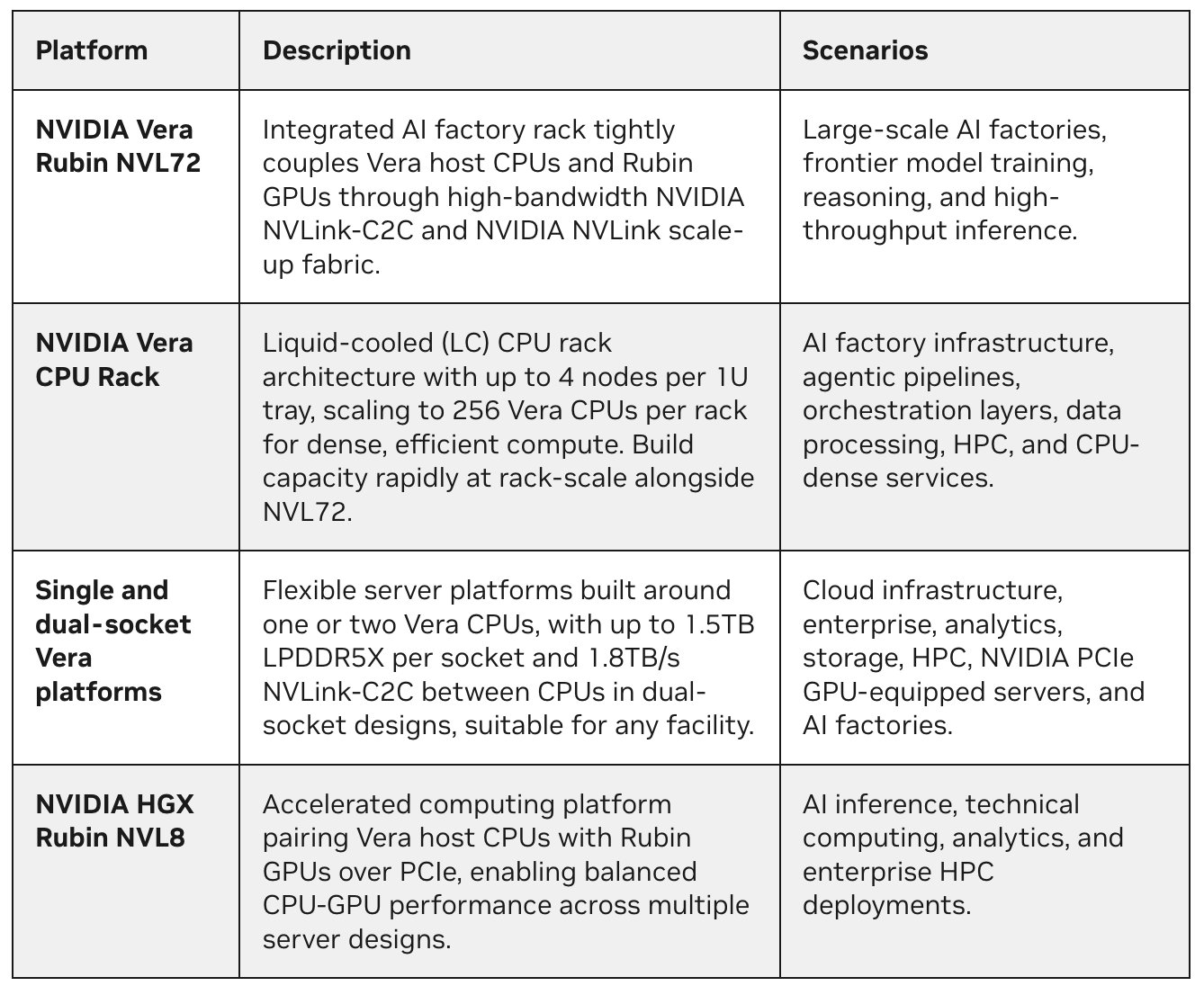

Disponibilidad de plataforma
Los sistemas Vera estarán disponibles en los principales OEM, como Dell, HPE, Lenovo y Supermicro, en la segunda mitad de 2026. Consulte la página web de CPU Vera para obtener más detalles
Más Información sobre la CPU Vera y Vera Rubin.
Desempeño de NVIDIA Vera en comparación con AMD EPYC Turin e Intel Xeon 6, en una variedad de cargas de trabajo, como compilación de código, intérpretes, scripts, motores de tiempo de ejecución, ETL, análisis de datos y gráficos.