
Nota del editor: Este post forma parte de la serie con IA Descodificada, que desmitifica la IA haciendo que la tecnología sea más accesible y presentando nuevo hardware, software, herramientas y aceleraciones para usuarios de PC RTX.
Los grandes modelos lingüísticos están impulsando algunos de los avances más interesantes de la IA gracias a su capacidad para comprender, resumir y generar rápidamente contenidos basados en texto.
Estas capacidades impulsan una gran variedad de casos de uso, como herramientas de productividad, asistentes digitales, personajes no jugables en videojuegos y mucho más. Pero no son una solución única, y los desarrolladores a menudo deben ajustar los LLM a las necesidades de sus aplicaciones.
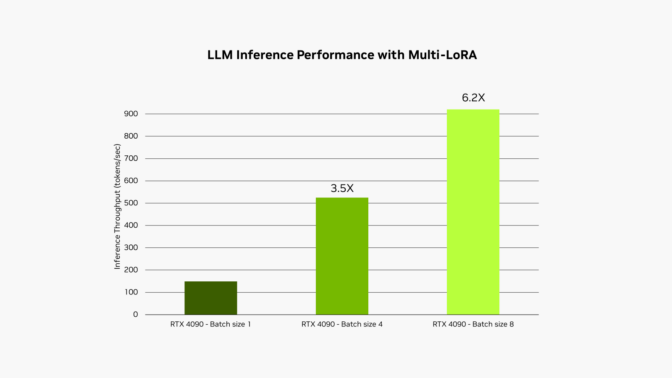
El kit de herramientas NVIDIA RTX AI Toolkit facilita el ajuste y la implementación de modelos de IA en PC y estaciones de trabajo RTX AI mediante una técnica denominada adaptación de bajo rango o LoRA. Una nueva actualización, ya disponible, permite utilizar varios adaptadores LoRA simultáneamente en la biblioteca de aceleración de IA NVIDIA TensorRT-LLM, lo que multiplica por 6 el rendimiento de los modelos ajustados.
Rendimiento optimizado
Los LLM deben personalizarse cuidadosamente para lograr un mayor rendimiento y satisfacer las crecientes demandas de los usuarios.
Estos modelos fundacionales se entrenan con enormes cantidades de datos, pero a menudo carecen del contexto necesario para el caso de uso específico de un desarrollador. Por ejemplo, un LLM genérico puede generar diálogos de videojuegos, pero es probable que no incluya los matices y la sutileza necesarios para escribir al estilo de un elfo del bosque con un pasado oscuro y un desdén apenas disimulado por la jerarquía.
Para obtener resultados más personalizados, los desarrolladores pueden ajustar el modelo con información relacionada con el caso de uso de la aplicación.
Tomemos como ejemplo el desarrollo de una aplicación para generar diálogos en el juego utilizando un LLM. El proceso de ajuste comienza con el uso de los pesos de un modelo entrenado previamente, como la información sobre lo que un personaje puede decir en el juego. Para que el diálogo tenga el estilo adecuado, el desarrollador puede ajustar el modelo en un conjunto de datos más pequeño, como un diálogo escrito en un tono más espeluznante o de villano.
En algunos casos, los desarrolladores pueden querer ejecutar todos estos procesos de ajuste simultáneamente. Por ejemplo, pueden querer generar textos de marketing escritos con distintas voces para varios canales de contenido. Al mismo tiempo, es posible que quieran resumir un documento y hacer sugerencias estilísticas, así como redactar la descripción de una escena de un videojuego y la indicación de imágenes para un generador de texto a imagen.
No resulta práctico ejecutar varios modelos a la vez, ya que no caben todos en la memoria de la GPU al mismo tiempo. Y aunque así fuera, el tiempo de inferencia dependería del ancho de banda de la memoria, es decir, de la velocidad a la que los datos pueden leerse de la memoria a la GPU.
Lo(RA) y Consulta
Una forma popular de abordar estos problemas es utilizar técnicas de ajuste fino como la adaptación de bajo rango. Una forma sencilla de verlo es como un archivo de parches que contiene las personalizaciones del proceso de ajuste fino.
Una vez entrenados, los adaptadores LoRA personalizados pueden integrarse perfectamente con el modelo base durante la inferencia, añadiendo una sobrecarga mínima. Los desarrolladores pueden adjuntar los adaptadores a un único modelo para servir a múltiples casos de uso. De este modo, se reduce la huella de memoria y se proporcionan los detalles adicionales necesarios para cada caso de uso específico.
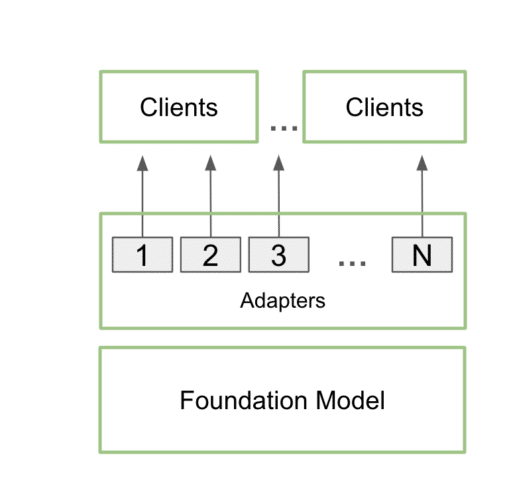
En la práctica, esto significa que una aplicación puede mantener sólo una copia del modelo base en la memoria, junto con muchas personalizaciones utilizando múltiples adaptadores LoRA.
Este proceso se denomina servicio multi-LoRA. Cuando se realizan varias llamadas al modelo, la GPU puede procesar todas las llamadas en paralelo, maximizando el uso de sus núcleos tensoriales y minimizando las demandas de memoria y ancho de banda para que los desarrolladores puedan utilizar de forma eficiente los modelos de IA en sus flujos de trabajo. Los modelos ajustados que utilizan adaptadores multi-LoRA rinden hasta 6 veces más rápido.
En el ejemplo de la aplicación de diálogo en el juego descrito anteriormente, el alcance de la aplicación podría ampliarse, utilizando el servicio multi-LoRA, para generar tanto elementos de la historia como ilustraciones, impulsados por una única indicación.
El usuario podría introducir una idea básica para la historia, y el LLM desarrollaría el concepto, ampliando la idea para proporcionar una base detallada. A continuación, la aplicación podría utilizar el mismo modelo, mejorado con dos adaptadores LoRA distintos, para refinar la historia y generar las imágenes correspondientes. Un adaptador LoRA genera una indicación de Difusión Estable para crear imágenes utilizando un modelo de Difusión Estable XL desplegado localmente. Mientras tanto, el otro adaptador LoRA, perfeccionado para escribir historias, podría elaborar una narración bien estructurada y atractiva.
En este caso, se utiliza el mismo modelo para ambas pasadas de inferencia, lo que garantiza que el espacio necesario para el proceso no aumente significativamente. La segunda pasada, que implica la generación de texto e imágenes, se realiza utilizando la inferencia por lotes, lo que hace que el proceso sea excepcionalmente rápido y eficiente en las GPU NVIDIA. Esto permite a los usuarios iterar rápidamente a través de diferentes versiones de sus historias, refinando la narrativa y las ilustraciones con facilidad.
Este proceso se describe con más detalle en un blog técnico reciente.
Los LLM se están convirtiendo en uno de los componentes más importantes de la IA moderna. A medida que crezca su adopción e integración, aumentará la demanda de LLM potentes y rápidos con personalizaciones específicas para cada aplicación. El soporte multi-LoRA añadido hoy al RTX AI Toolkit ofrece a los desarrolladores una nueva y potente forma de acelerar estas capacidades.