Nota del editor: Este post forma parte de la serie IA decodificada, que permite desmitificar la IA haciendo que la tecnología sea más accesible, y muestra nuevo hardware, software, herramientas y aceleraciones para usuarios de PC RTX.
La era de la PC con IA ya está aquí, y viene impulsada por las tecnologías NVIDIA RTX y GeForce RTX. Con ella llega una nueva forma de evaluar el rendimiento de las tareas aceleradas por IA y un nuevo lenguaje que puede resultar desalentador descifrar a la hora de elegir entre desktops y laptops disponibles.
Mientras que los jugadores de PC entienden de fotogramas por segundo (FPS) y estadísticas similares, medir el rendimiento de la IA requiere nuevas métricas.
Salir en los TOPS
La primera es TOPS, o billones de operaciones por segundo. Trillones es la palabra importante aquí: las cifras de procesamiento detrás de las tareas de IA generativa son absolutamente masivas. Piense en TOPS como una métrica de rendimiento bruto, similar a la potencia de un motor. Mayor es mejor.
Comparemos, por ejemplo, la línea de PC Copilot+ anunciada recientemente por Microsoft, que incluye unidades de procesamiento neural (NPU) capaces de realizar más de 40 TOPS. Realizar 40 TOPS es suficiente para algunas tareas ligeras asistidas por IA, como preguntar a un chatbot local dónde están las notas de ayer.
Pero muchas tareas de IA generativa son más exigentes. Las GPUs NVIDIA RTX y GeForce RTX proporcionan un rendimiento sin precedentes en todas las tareas generativas: la GPU GeForce RTX 4090 ofrece más de 1.300 TOPS. Este es el tipo de potencia necesaria para manejar la creación de contenidos digitales asistida por IA, la superresolución de IA en los juegos de PC, la generación de imágenes a partir de texto o vídeo, la consulta de grandes modelos de lenguaje locales (LLM) y mucho más.
Insertar Tokens para Jugar
TOPS es sólo el principio de la historia. El rendimiento del LLM se mide por el número de tokens generados por el modelo
Los tokens son el resultado del LLM. Un token puede ser una palabra de una frase o incluso un fragmento más pequeño, como un signo de puntuación o un espacio en blanco. El rendimiento de las tareas aceleradas por IA puede medirse en «tokens por segundo».
Otro factor importante es el tamaño del grupo, es decir, el número de entradas procesadas simultáneamente en un solo paso de inferencia. Dado que un LLM será el núcleo de muchos sistemas de IA modernos, la capacidad de manejar múltiples entradas (por ejemplo, de una sola aplicación o de varias aplicaciones) será un factor diferenciador clave. Aunque los lotes de mayor tamaño mejoran el rendimiento de las entradas simultáneas, también requieren más memoria, especialmente cuando se combinan con modelos más grandes.
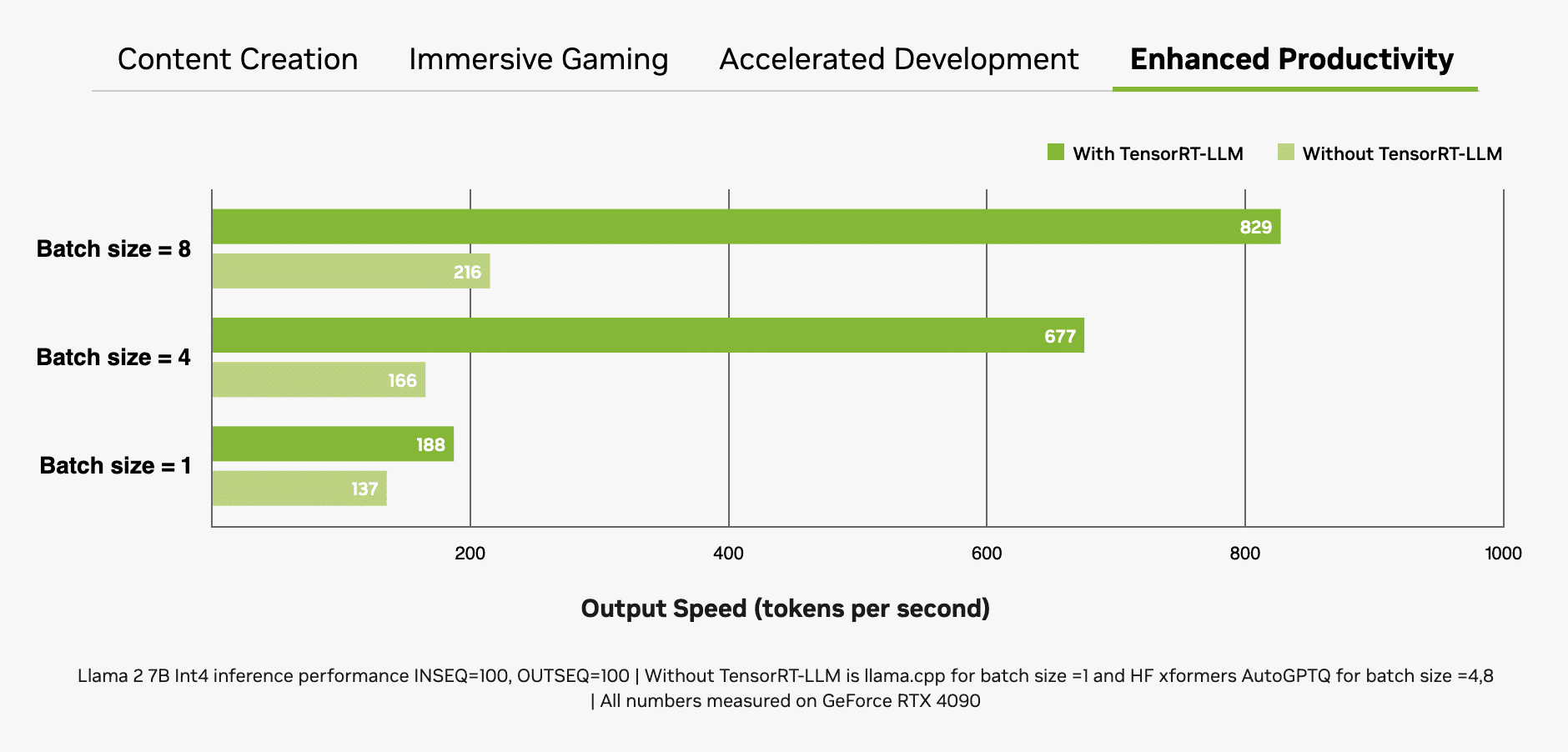
Las GPUs RTX son excepcionalmente adecuadas para los LLM gracias a su gran cantidad de memoria de acceso aleatorio de video (VRAM) dedicada, los Núcleos Tensor y el software TensorRT-LLM.
Las GPUs GeForce RTX ofrecen hasta 24 GB de VRAM de alta velocidad, y las GPUs NVIDIA RTX hasta 48 GB, lo que permite manejar modelos más grandes y posibilitar lotes de mayor tamaño. Las GPUs RTX también aprovechan los Núcleos Tensor, aceleradores de IA dedicados que aceleran drásticamente las operaciones de alta carga computacional necesarias para el aprendizaje profundo y los modelos generativos de IA. Este máximo rendimiento se obtiene fácilmente cuando una aplicación utiliza el kit de desarrollo de software (SDK) NVIDIA TensorRT, que libera la IA generativa de mayor rendimiento en los más de 100 millones de PCs y estaciones de trabajo Windows equipados con GPUs RTX.
La combinación de memoria, aceleradores de IA dedicados y software optimizado proporciona a las GPUs RTX grandes incrementos de rendimiento, especialmente a medida que aumenta el tamaño de los grupos.
De Texto a Imagen, Más Rápido que Nunca
Medir la velocidad de generación de imágenes es otra forma de evaluar el rendimiento. Una de las formas más sencillas utiliza la difusión estable, un popular modelo de IA basado en imágenes que permite a los usuarios convertir fácilmente descripciones de texto en representaciones visuales complejas.
Con Stable Diffusion, los usuarios pueden crear y refinar rápidamente imágenes a partir de indicaciones de texto para obtener el resultado deseado. Cuando se utiliza una GPU RTX, estos resultados pueden generarse más rápido que procesando el modelo de IA en una CPU o NPU.
Ese rendimiento es aún mayor cuando se utiliza la extensión TensorRT para la popular interfaz Automatic1111. Los usuarios de RTX pueden generar imágenes a partir de indicaciones hasta dos veces más rápido con el punto de control SDXL Base, lo que agiliza considerablemente los workflows de Stable Diffusion.
ComfyUI, otra popular interfaz de usuario de Stable Diffusion, incorporó la aceleración TensorRT la semana pasada. Los usuarios de RTX ahora pueden generar imágenes a partir de indicaciones hasta un 60% más rápido, e incluso pueden convertir estas imágenes en videos usando Stable Video Diffuson hasta un 70% más rápido con TensorRT.
La aceleración de TensorRT puede ponerse a prueba en la nueva evaluación comparativa UL Procyon AI Image Generation, que proporciona un aumento de la velocidad del 50% en una GPU GeForce RTX 4080 SUPER en comparación con la implementación más rápida sin TensorRT.
Pronto se lanzará la aceleración TensorRT para Stable Diffusion 3, el nuevo y esperado modelo de conversión de texto a imagen de Stability AI, que aumentará el rendimiento en un 50%. Además, el nuevo optimizador de modelos TensorRT permite acelerar aún más el rendimiento. Esto se traduce en una aceleración del 70% en comparación con la implementación sin TensorRT, junto con una reducción del 50% en el consumo de memoria.
Por supuesto, ver para creer: la verdadera prueba está en el caso de uso real de iterar sobre una indicación original. Los usuarios pueden refinar la generación de imágenes retocando las indicaciones mucho más rápido en las GPU RTX, tardando segundos por iteración en comparación con minutos en un Macbook Pro M3 Max. Además, los usuarios obtienen velocidad y seguridad, ya que todo permanece privado cuando se utiliza localmente en una PC o workstation con RTX.
Los Resultados están Disponibles y son de Código Abierto
Pero no nos creas. El equipo de investigadores e ingenieros de IA que hay detrás de Jan.ai, una aplicación de código abierto, integró recientemente TensorRT-LLMen su chatbot local y evaluado por sí mismo estas optimizaciones.
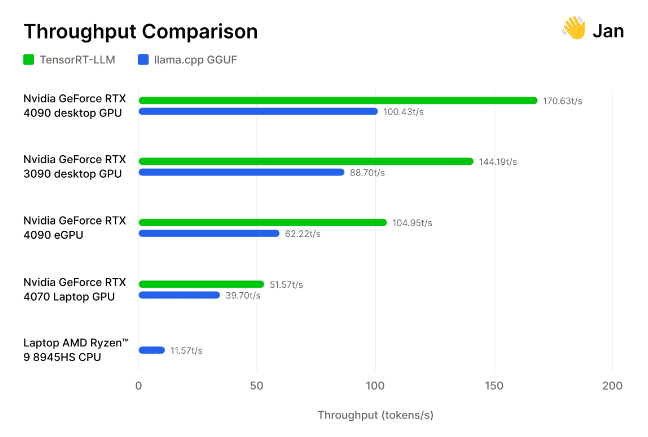
Los investigadores probaron su implementación de TensorRT-LLM frente al motor de inferencia de código abierto llama.cpp en diversas GPU y CPU utilizadas por la comunidad. Comprobaron que TensorRT es «entre un 30 y un 70% más rápido que llama.cpp en el mismo hardware», así como más eficiente en ejecuciones de procesamiento consecutivas. El equipo también incluyó su metodología, invitando a otros a medir el rendimiento de la IA generativa por sí mismos.
De los juegos a la IA generativa, la velocidad gana. Los TOPS, las imágenes por segundo, los tokens por segundo y el tamaño del grupo se tienen en cuenta a la hora de determinar los campeones de rendimiento.
La IA generativa está transformando los juegos, las videoconferencias y las experiencias interactivas de todo tipo. Entérate de las novedades y lo que está por venir suscribiéndote al boletín AI Descodificada.