
Los últimos años han sido testigos del aumento de la popularidad de la IA generativa y los grandes modelos de lenguaje (LLM), como parte de una amplia revolución de la IA. A medida que las aplicaciones basadas en LLM se implementan en todas las empresas, existe la necesidad de determinar la rentabilidad de las diferentes soluciones de servicio de IA. El costo de la implementación de una aplicación LLM depende de la cantidad de consultas que pueda procesar por segundo y, al mismo tiempo, responder a los usuarios finales y admitir un nivel aceptable de precisión de respuesta. Esta publicación se centra específicamente en el rendimiento de LLM y la medición de la latencia como parte de la evaluación de los costos de las aplicaciones de LLM.
NVIDIA empodera a los desarrolladores con innovaciones de pila completa, que abarcan chips, sistemas y software. La pila de software de inferencia de NVIDIA incluye microservicios NVIDIA Dynamo, NVIDIA TensorRT-LLM y NVIDIA NIM. Para ayudar a los desarrolladores con el rendimiento de la inferencia de evaluación comparativa, NVIDIA también ofrece GenAI-Perf, una herramienta de evaluación comparativa de IA generativa de código abierto. Obtén más información sobre el uso de GenAI-Perf para realizar pruebas comparativas.
La evaluación del rendimiento de los LLM se puede lograr utilizando una variedad de herramientas. Estas herramientas del lado del cliente ofrecen métricas específicas para aplicaciones basadas en LLM, pero difieren en la forma en que definen, miden y calculan las diferentes métricas. Esto puede ser confuso y puede dificultar la comparación de los resultados de una herramienta con los resultados de otra.
En esta publicación, aclaramos las métricas comunes y las sutiles diferencias en cómo las herramientas de evaluación comparativa populares definen y miden estas métricas. También discutimos los parámetros importantes para la evaluación comparativa.
Pruebas de Carga y Evaluación Comparativa del Rendimiento
Las pruebas de carga y la evaluación comparativa del rendimiento son dos enfoques distintos para evaluar la implementación de un LLM. Las pruebas de carga se centran en simular un gran número de solicitudes simultáneas a un modelo para evaluar su capacidad para manejar el tráfico del mundo real a escala. Este tipo de pruebas ayuda a identificar problemas relacionados con la capacidad del servidor, las tácticas de escalado automático, la latencia de la red y la utilización de recursos.
Por el contrario, la evaluación comparativa del rendimiento, como lo demuestra la herramienta NVIDIA GenAI-Perf, se ocupa de medir el rendimiento real del modelo en sí, como su rendimiento, latencia y métricas a nivel de token. Este tipo de pruebas ayuda a identificar problemas relacionados con la eficiencia, la optimización y la configuración del modelo.
Si bien las pruebas de carga son esenciales para garantizar que el modelo pueda manejar un gran volumen de solicitudes, la evaluación comparativa del rendimiento es crucial para comprender la capacidad del modelo para procesar solicitudes de manera eficiente. Al combinar ambos enfoques, los desarrolladores pueden obtener una comprensión integral de sus capacidades de implementación de LLM e identificar áreas de mejora.
Cómo Funciona la Inferencia de LLM
Antes de examinar las métricas de referencia, es importante comprender cómo funciona la inferencia de LLM y familiarizarse con la terminología relacionada. Una aplicación de LLM produce resultados a través de etapas de inferencia. Para una solicitud de LLM específica determinada, estas etapas incluyen:
- Solicitud: El usuario proporciona una consulta
- En cola: la consulta se une a la cola para su procesamiento
- Prerelleno: El modelo LLM procesa la solicitud
- Generación: El modelo LLM genera una respuesta, un token a la vez
Un token de IA es un concepto específico de los LLM y es fundamental para las métricas de rendimiento de inferencia de LLM. Es la unidad, o entidad lingüística más pequeña, que los LLM utilizan para descomponer y procesar el lenguaje natural. La colección de todas las fichas se conoce como vocabulario. Cada LLM tiene su propio tokenizador que se aprende de los datos para representar el texto de entrada de manera eficiente. Como aproximación, para muchos LLM populares, cada token tiene ~0,75 palabras en inglés.
La longitud de la secuencia es la longitud de la secuencia de datos. La longitud de la secuencia de entrada (ISL) es la cantidad de tokens que obtiene el LLM. Incluye la consulta del usuario, cualquier solicitud del sistema (instrucciones para el modelo, por ejemplo), el historial de chat anterior, el razonamiento de la cadena de pensamiento (CoT) y los documentos del pipeline de generación aumentada de recuperación (RAG). La longitud de la secuencia de salida (OSL) es la cantidad de tokens que genera el LLM. La longitud del contexto es la cantidad de tokens que utiliza el LLM en cada paso de generación, incluidos los tokens de entrada y salida generados hasta ese punto. Cada LLM tiene una longitud de contexto máxima que se puede asignar a los tokens de entrada y salida. Para obtener más información sobre la inferencia de LLM, consulte Mastering LLM Techniques: Inference Optimization.
El streaming es una opción que permite que las salidas parciales de LLM se transmitan de vuelta a los usuarios en forma de fragmentos de tokens generados de forma incremental. Esto es importante para las aplicaciones de chatbot, donde es deseable recibir una respuesta inicial rápidamente. Mientras el usuario digiere el contenido parcial, la siguiente parte del resultado llega a segundo plano. Por el contrario, en el modo sin transmisión, se devuelve la respuesta completa de una sola vez.
Métricas de Inferencia de LLM
En esta sección se explican algunas de las métricas comunes que se usan en el sector, incluido el tiempo hasta el primer token y la latencia entre tokens, como se muestra en la Figura 1. Aunque parecen sencillos, existen algunas diferencias leves pero significativas entre las diversas herramientas de evaluación comparativa.
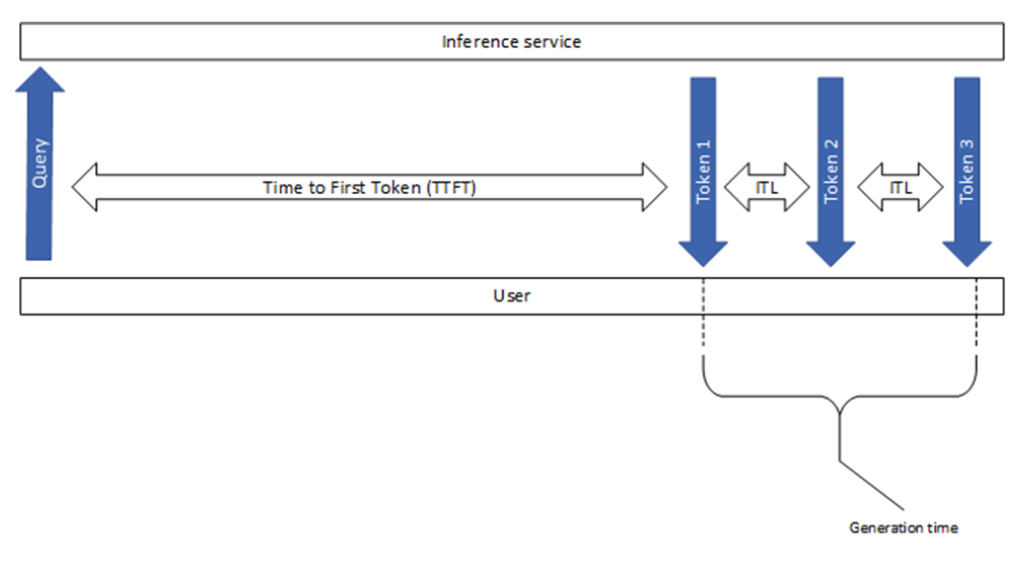
Tiempo Hasta el Primer Token
El tiempo hasta el primer token (TTFT) es el tiempo que se tarda en procesar el mensaje y generar el primer token (figura 2). En otras palabras, mide cuánto tiempo debe esperar un usuario antes de ver la salida del modelo.
Tenga en cuenta que las herramientas de evaluación comparativa GenAI-Perf y LLMPerf ignoran las respuestas iniciales que no tienen contenido o el contenido con una cadena vacía (sin token presente). Esto se debe a que la medición TTFT no tiene sentido cuando la primera respuesta no tiene ningún token.
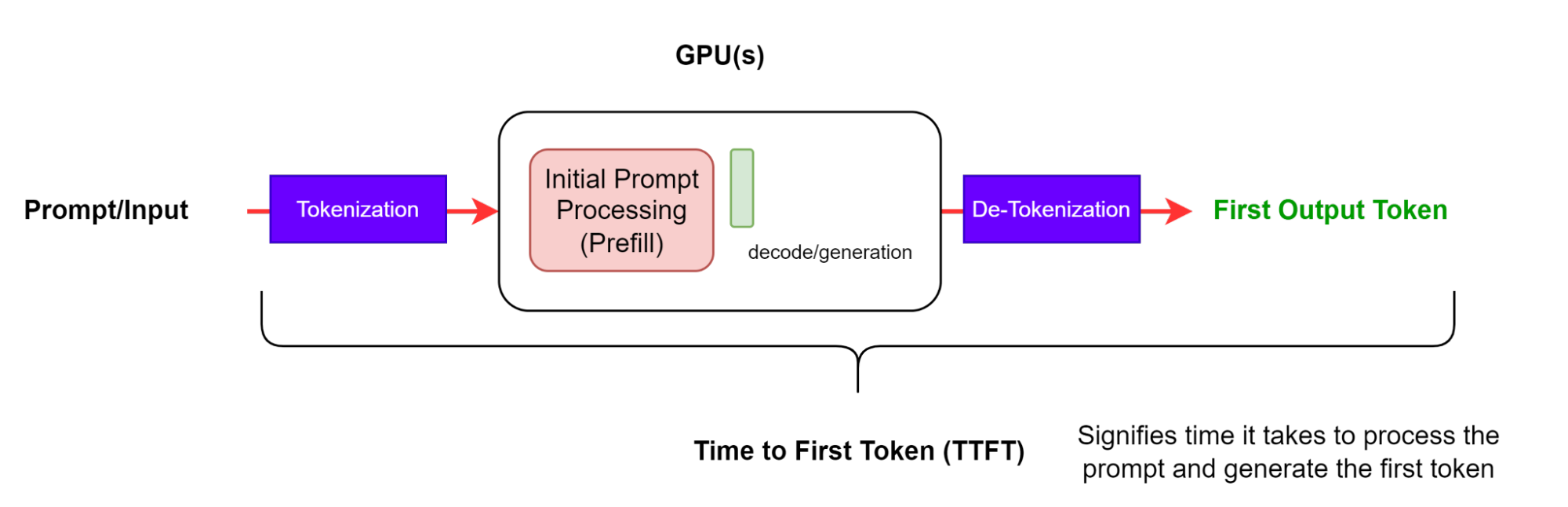
TTFT generalmente incluye el tiempo de cola de solicitudes, el tiempo de prellenado y la latencia de red. Cuanto más largo sea el mensaje, mayor será el TTFT. Esto se debe a que el mecanismo de atención requiere que toda la secuencia de entrada calcule y cree la llamada caché clave-valor (KV), a partir de la cual puede comenzar el bucle de generación iterativo. Además, una aplicación de producción puede tener varias solicitudes en curso, por lo que la fase de relleno previo de una solicitud puede superponerse con la fase de generación de otra solicitud.
Latencia de Solicitudes de Extremo a Extremo
La latencia de solicitud de extremo a extremo (e2e_latency) indica el tiempo que transcurre desde el envío de una consulta hasta la recepción de la respuesta completa, incluido el tiempo de colocación en cola y procesamiento por lotes y las latencias de red (figura 3). Tenga en cuenta que en el modo de transmisión, el paso de destokenización se puede realizar varias veces cuando se devuelven resultados parciales al usuario.

En el caso de una solicitud individual, la latencia de la solicitud de un extremo a otro es la diferencia de tiempo entre el momento en que se envía la solicitud y se recibe el token final:

Tenga en cuenta que generation_time es la duración desde que se recibe el primer token hasta que se recibe el último token (Figura 1). Además, GenAI-Perf elimina la última señal (finalizada) o la respuesta vacía, por lo que no se incluyen en el e2e_latency.
Latencia Entre Tokens
La latencia entre tokens (ITL) es el tiempo promedio entre la generación de tokens consecutivos en una secuencia. También se conoce como token de tiempo por salida (TPOT).
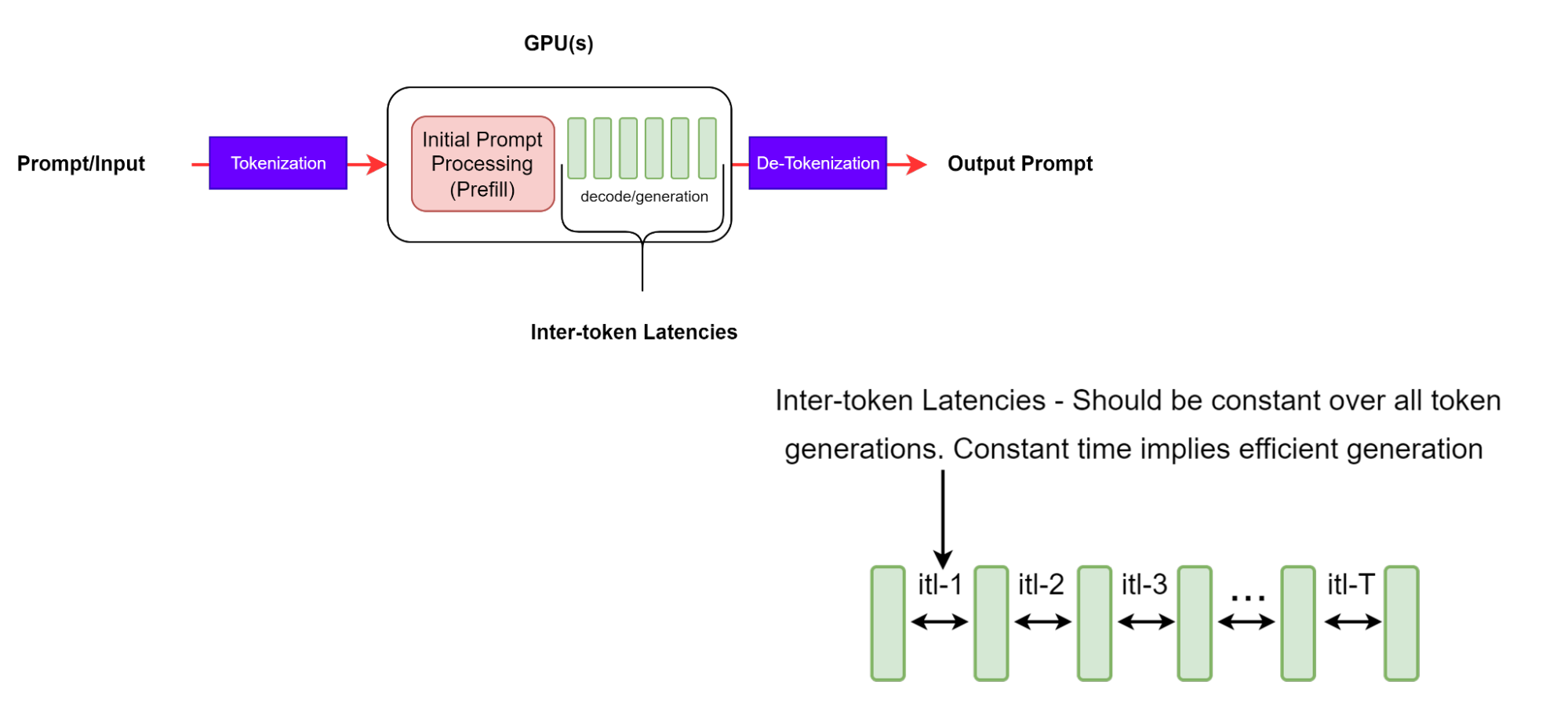
Aunque esta parece ser una definición sencilla, existen algunas diferencias intrincadas en la forma en que se recopila la métrica a través de las diferentes herramientas de evaluación comparativa. Por ejemplo, GenAI-Perf no incluye TTFT en el cálculo promedio (a diferencia de LLMPerf, que sí incluye TTFT).
GenAI-Perf define el ITL con la siguiente ecuación:

La ecuación utilizada para esta métrica no incluye el primer token (por lo tanto, resta 1 en el denominador). Esto se hace para que el DIT sea únicamente una característica de la parte de decodificación de la tramitación de la solicitud.
Es importante tener en cuenta que con secuencias de salida más largas, la caché KV crece, por lo que el costo de memoria también aumenta. El costo del cálculo de la atención también crece: para cada nuevo token, este costo es lineal en la longitud de la secuencia de entrada y salida generada hasta ahora. Sin embargo, este cálculo no suele estar vinculado al proceso. Los ITL coherentes significan una gestión eficiente de la memoria y un mejor ancho de banda de memoria, así como un cálculo eficiente de la atención.
Tokens Por Segundo
Los tokens por segundo (TPS) por sistema representan el rendimiento total de tokens de salida por segundo, lo que representa todas las solicitudes que ocurren simultáneamente. A medida que aumenta el número de solicitudes, el TPS total por sistema aumentará, hasta que alcance un punto de saturación para todos los recursos de computación de GPU disponibles, más allá del cual posiblemente disminuirá.
Para el ejemplo que se muestra en la figura 5, suponga la escala de tiempo de todo el banco de pruebas con n solicitudes en total. Los eventos se definen de la siguiente manera:
- Li: Latencia de extremo a extremo de la i-ésima solicitud
- T_start: Inicio del benchmark
- Tx: Marca de tiempo de la primera solicitud
- Ty: Marca de tiempo de la última respuesta de la última solicitud
- T_end: Fin del índice de referencia

GenAI-Perf define el TPS como el total de tokens de salida dividido por la latencia de extremo a extremo entre la primera solicitud y la última respuesta de la última solicitud:

LLMPerf define TPS como el total de tokens de salida dividido por toda la duración del benchmark:

Por lo tanto, el rendimiento del LLM también incluye los siguientes gastos generales en la métrica:
- Generación de mensajes de entrada
- Preparación de la solicitud
- Almacenamiento de las respuestas.
En nuestra observación, estos gastos generales en el escenario de concurrencia única a veces pueden representar el 33% de toda la duración del referencia.
Tenga en cuenta que el cálculo de TPS se realiza por lotes y no es una métrica en ejecución. Además, GenAI-Perf utiliza una técnica de ventana deslizante para encontrar mediciones estables. Esto significa que las mediciones proporcionadas procederán de un subconjunto representativo de las solicitudes completadas, lo que significa que las solicitudes de «calentamiento» y «enfriamiento» no se incluyen al calcular las métricas.
El TPS por usuario representa el rendimiento desde una perspectiva de usuario único y se define como:

Esta definición es para la solicitud de cada usuario, que asintóticamente se aproxima a 1/ITL a medida que aumenta la longitud de la secuencia de salida. Tenga en cuenta que a medida que aumenta el número de solicitudes simultáneas en el sistema, el TPS total para todo el sistema aumentará, mientras que el TPS por usuario disminuye a medida que aumenta la latencia.
Solicitudes Por Segundo
Solicitudes por segundo (RPS) es el número promedio de solicitudes que el sistema puede completar con éxito en un período de 1 segundo. Se calcula de la siguiente manera:

Parámetros de Evaluación Comparativa y Mejores Prácticas
En esta sección se presentan algunos parámetros de prueba importantes y su rango de barrido, lo que garantiza una evaluación comparativa significativa y una garantía de calidad.
Casos de Uso de Aplicaciones y Su Impacto en el Rendimiento de LLM
Los casos de uso específicos de una aplicación influirán en las longitudes de las secuencias (ISL y OSL), lo que a su vez afectará la rapidez con la que un sistema digiere la entrada para formar KV-cache y generar tokens de salida. Un ISL más largo aumentará el requisito de memoria para la etapa de prellenado y, por lo tanto, aumentará el TTFT. Un OSL más largo aumentará el requerimiento de memoria (tanto de ancho de banda como de capacidad) para la etapa de generación y, por lo tanto, aumentará el ITL. Es importante comprender la distribución de entradas y salidas en la implementación de LLM para optimizar mejor la utilización del hardware.
Los casos de uso comunes y los pares ISL/OSL probables incluyen:
- Traducción: Incluye la traducción entre idiomas y código y se caracteriza por tener ISL y OSL similares de aproximadamente 500~2000 tokens cada uno.
- Generación: incluye la generación de código, historia y contenido de correo electrónico y contenido genérico a través de la búsqueda. Este se caracteriza por tener un OSL de O(1.000) tokens, mucho más largo que un ISL de O(100) tokens.
- Resumen: Incluye recuperación, incitación en cadena de pensamiento y conversaciones de varios turnos. Este se caracteriza por tener un ISL de O(1000) tokens, mucho más largo que un OSL de O(100) tokens.
- Razonamiento: Los modelos de razonamiento recientes generan un gran número de tokens de salida en un enfoque de razonamiento explícito de cadena de pensamiento, autorreflexión y verificación para resolver problemas complejos, como codificación, matemáticas o acertijos. Se caracteriza por un ISL corto de tokens O(100) y un OSL grande de tokens O(1000-10000).
Parámetros de Control de Carga
Los parámetros de control de carga, tal como se definen en esta sección, se utilizan para inducir cargas en sistemas LLM.
Simultaneidad N es el número de usuarios simultáneos, cada uno con una solicitud activa, o equivalentemente, el número de solicitudes atendidas simultáneamente por un servicio LLM. Tan pronto como la solicitud de cada usuario recibe una respuesta completa, se envía otra solicitud para garantizar que en cualquier momento el sistema tenga exactamente N solicitudes. La simultaneidad se usa con mayor frecuencia para describir y controlar la carga inducida en el sistema de inferencia.
Tenga en cuenta que LLMPerf envía solicitudes en lotes de N solicitudes, pero hay un período de drenaje en el que espera a que se completen todas las solicitudes antes de enviar el siguiente lote. Como tal, hacia el final del lote, el número de solicitudes simultáneas se reduce gradualmente a 0. Esto difiere de GenAI-Perf, que siempre garantiza N solicitudes activas durante todo el período de evaluación comparativa.
El parámetro de tamaño máximo de lote define el número máximo de solicitudes que el motor de inferencia puede procesar simultáneamente, donde lote es el grupo de solicitudes simultáneas que procesa el motor de inferencia. Puede ser un subconjunto de las solicitudes simultáneas.
Si la simultaneidad supera el tamaño máximo del lote multiplicado por el número de réplicas activas, algunas solicitudes tendrán que esperar en una cola para su procesamiento posterior. En este caso, es posible que vea un aumento en el valor de TTFT debido al efecto de cola de esperar a que se abra una ranura.
La tasa de solicitudes es otro parámetro que se puede utilizar para controlar la carga determinando la velocidad a la que se envían nuevas solicitudes. El uso de una tasa de solicitudes constante (o estática) r significa que se envía 1 solicitud cada 1/r segundos, mientras que el uso de una tasa de solicitudes de Poisson (o exponencial) determina el tiempo promedio entre llegadas.
GenAI-Perf admite tanto la simultaneidad como la tasa de solicitudes. Sin embargo, se recomienda usar la simultaneidad. Al igual que con la tasa de solicitudes, el número de solicitudes pendientes puede crecer sin límites si la solicitud por segundo supera el rendimiento del sistema.
Al especificar las simultaneidades que se van a probar, es útil barrer un intervalo de valores, desde un valor mínimo de 1 hasta un valor máximo no mucho mayor que el tamaño máximo del lote. Esto se debe a que, cuando la simultaneidad es mayor que el tamaño máximo de lote del motor, algunas solicitudes tendrán que esperar en una cola. Por lo tanto, el rendimiento del sistema generalmente se satura alrededor del tamaño máximo del lote, mientras que la latencia continuará aumentando de manera constante.
Otros Parámetros
Además, existen parámetros de servicio de LLM relevantes que pueden afectar el rendimiento de la inferencia, así como la precisión del punto de referencia.
La mayoría de los LLM tienen un token especial de fin de secuencia (EOS), que significa el final de la generación. Indica que el LLM ha generado una respuesta completa y debe detenerse. Bajo uso general, la inferencia de LLM debería respetar esta señal y dejar de generar más tokens. El parámetro ignore_eos generalmente indica si un framework de inferencia LLM debe ignorar el token EOS y continuar generando tokens hasta alcanzar el límite de max_tokens. A efectos de evaluación comparativa, este parámetro debe establecerse en True, para alcanzar la longitud de salida prevista y obtener una medición coherente.
Diferentes parámetros de muestreo (como codicioso, top_p, top_k y temperatura) pueden tener impactos en la velocidad de generación de LLM. Greedy, por ejemplo, se puede implementar simplemente seleccionando el token con el logit más alto. No es necesario normalizar y ordenar la distribución de probabilidad sobre los tokens, lo que ahorra en cálculo. Cualquiera que sea el método de muestreo que se elija, es una buena práctica mantener la coherencia dentro de la misma configuración de evaluación comparativa. Para obtener una explicación detallada de los diferentes métodos de muestreo, vea How to Generate Text: Using Different Decoding methods for Language Generation with Transformers.
Empieza Ahora
La evaluación comparativa del rendimiento de LLM es un paso crítico para garantizar un alto rendimiento y un servicio de LLM rentable a escala. En este post se han analizado las métricas y parámetros más importantes a la hora de comparar la inferencia de LLM. Para obtener más información, consulte estos recursos:
- Inferencia de IA: Equilibrio Entre el Costo, la Latencia y el Rendimiento
- Cómo Implementar NVIDIA NIM en 5 Minutos
- Una Guía Sencilla para Implementar IA Generativa con NVIDIA NIM
Explore la plataforma de inferencia de IA de NVIDIA y vea los datos más recientes de rendimiento de inferencia de IA. Las optimizaciones de las bibliotecas de TensorRT, TensorRT-LLM y TensorRT Model Optimizer se combinan y están disponibles a través de implementaciones listas para producción mediante microservicios NVIDIA NIM.