La IA generativa tiene el potencial de transformar todas las industrias. Los trabajadores humanos ya están utilizando grandes modelos de lenguaje (LLM) para explicar, razonar y resolver tareas cognitivas difíciles. La generación aumentada de recuperación (RAG, por sus siglas en inglés) conecta los LLM con los datos, ampliando la utilidad de los LLM al darles acceso a información actualizada y precisa.
Muchas empresas ya han comenzado a explorar cómo RAG puede ayudarlas a automatizar los procesos comerciales y extraer datos para obtener información. Aunque la mayoría de las empresas han iniciado múltiples pilotos alineados con los casos de uso de IA generativa, se estima que el 90% de ellos no pasarán de la fase de evaluación en un futuro próximo. Transformar una demostración convincente de RAG en un servicio de producción que ofrezca un valor comercial real sigue siendo un desafío.
En este blog, describimos cómo la IA de NVIDIA te ayuda a llevar las aplicaciones RAG de la fase de pruebas a la producción en cuatro pasos.
Creación de Un Pipeline de RAG Listo para la Empresa
Hay muchos obstáculos asociados con el desarrollo y la implementación de un pipeline RAG empresarial lista para la producción.
Los administradores de TI se enfrentan a desafíos relacionados con la seguridad, la usabilidad, la portabilidad y la gobernanza de datos de LLM. Los desarrolladores empresariales pueden tener dificultades con la precisión de LLM y la madurez general de los frameworks de programación de LLM. Y la gran velocidad de la innovación de código abierto es abrumadora para todos, con nuevos modelos de LLM y técnicas de RAG que aparecen todos los días.
Bases para Simplificar el Desarrollo y la Implementación de RAG de Producción
NVIDIA ayuda a gestionar esta complejidad al proporcionar una arquitectura de referencia para aplicaciones RAG de extremo a extremo nativas de la nube. La arquitectura de referencia es modular, combinando el popular software de código abierto con la aceleración de NVIDIA. Aprovechar un conjunto completo de bases modulares ofrece varios beneficios.
En primer lugar, las empresas pueden integrar selectivamente nuevos componentes en su infraestructura existente.
En segundo lugar, pueden elegir entre componentes comerciales y de código abierto para cada etapa del pipeline. Las empresas son libres de seleccionar los componentes adecuados para sus propios casos de uso y, al mismo tiempo, evitar la dependencia de un proveedor.
Por último, la arquitectura modular simplifica la evaluación, la observación y la resolución de problemas en cada etapa del pipeline.
En la figura 1 se muestran los componentes básicos esenciales para implementar un pipeline de RAG.
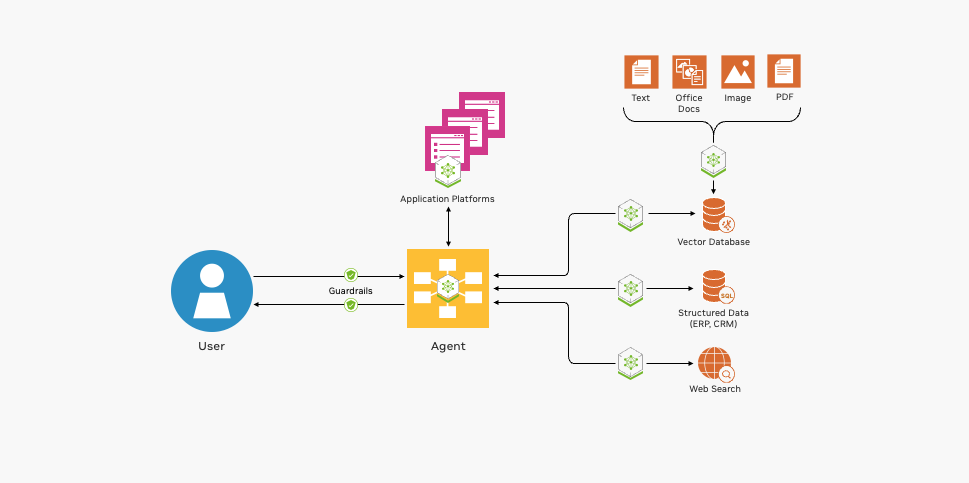
NVIDIA ofrece integración de código abierto, contenedores acelerados por GPU y mucho más para ayudarte a desarrollar tus aplicaciones RAG.
Integración de Código Abierto con Frameworks y Herramientas Populares
NVIDIA proporciona pipelines de ejemplo para ayudar a poner en marcha el desarrollo de aplicaciones RAG. Los ejemplos de pipelines de NVIDIA RAG muestran a los desarrolladores cómo combinarse con los frameworks de programación LLM de código abierto más populares, incluidos LangChain, LlamaIndex y Haystack, con el software acelerado de NVIDIA. Al utilizar estos ejemplos como punto de partida, los desarrolladores empresariales pueden disfrutar de lo mejor de ambos mundos, combinando la innovación de código abierto con un rendimiento y una escala acelerados.
Los ejemplos también demuestran la integración con herramientas populares de código abierto para la evaluación, la observabilidad de la canalización y la ingesta de datos, lo que hace que las operaciones de canalización del segundo día sean más fáciles y rentables.
Contenedores Acelerados por GPU para Respuestas Rápidas y Precisas
Las aplicaciones RAG empresariales con tecnología LLM deben ser receptivas y precisas. Los sistemas basados en CPU no pueden ofrecer un rendimiento aceptable a escala empresarial. El catálogo de API de NVIDIA incluye contenedores para impulsar cada etapa de un pipeline RAG que se beneficia de la aceleración de GPU.
- NVIDIA NIM ofrece el mejor rendimiento y escala de la industria para la inferencia de LLM.
- NVIDIA NeMo Retriever simplifica y acelera las funciones de incrustación, recuperación y consulta de documentos en el corazón de un pipeline RAG.
- NVIDIA RAPIDS acelera la búsqueda y la indexación de las bases de datos que almacenan las representaciones vectoriales de los datos empresariales.
Compatibilidad con Entrada, Salida y Procesamiento de Datos Multimodales
Las aplicaciones RAG están evolucionando rápidamente de chatbots basados en texto a workflows complejos basados en eventos que involucran una variedad de modalidades, como imágenes, audio y video. El software de IA de NVIDIA mejora la facilidad de uso y la funcionalidad de los pipelines RAG para abordar estos casos de uso emergentes.
- NVIDIA Riva ofrece interfaces de texto a voz, voz a texto y traducción aceleradas por GPU para interactuar con pipelines RAG utilizando el lenguaje hablado.
- NVIDIA RAPIDS puede acelerar las acciones de GPU activadas por agentes LLM. Por ejemplo, los agentes de LLM pueden llamar a RAPIDS cuDF para realizar cálculos matemáticos estadísticos en datos estructurados.
- NVIDIA Morpheus se puede utilizar para preprocesar volúmenes masivos de datos empresariales e ingerirlos en tiempo real.
- NVIDIA Metropolis y NVIDIA Holoscan añaden capacidades de procesamiento de vídeo y sensores al pipeline RAG.
Los desarrolladores empresariales pueden aprovechar NVIDIA AI Enterprise para implementar estos componentes de software de IA para la producción. NVIDIA AI Enterprise proporciona el tiempo de ejecución más rápido y eficiente para aplicaciones de IA generativa de nivel empresarial.
Cuatro Pasos para Llevar Tu Aplicación RAG de la Fase de Pruebas a la Producción
La creación de aplicaciones RAG de producción requiere la colaboración entre muchas partes interesadas.
- Los científicos de datos evalúan el rendimiento y la precisión de los LLM.
- Los desarrolladores de IA empresarial escriben, prueban y mejoran las aplicaciones RAG.
- Los ingenieros de datos conectan y transforman los datos empresariales para su indexación y recuperación.
- MLOps, DevOps e ingenieros de confiabilidad del sitio (SRE) implementan y mantienen los sistemas de producción.
La IA de NVIDIA se extiende desde la nube hasta el silicio para respaldar cada etapa del desarrollo, la implementación y el funcionamiento de las aplicaciones RAG. En la figura 2 se muestran los cuatro pasos para mover una aplicación RAG de la evaluación a la producción.
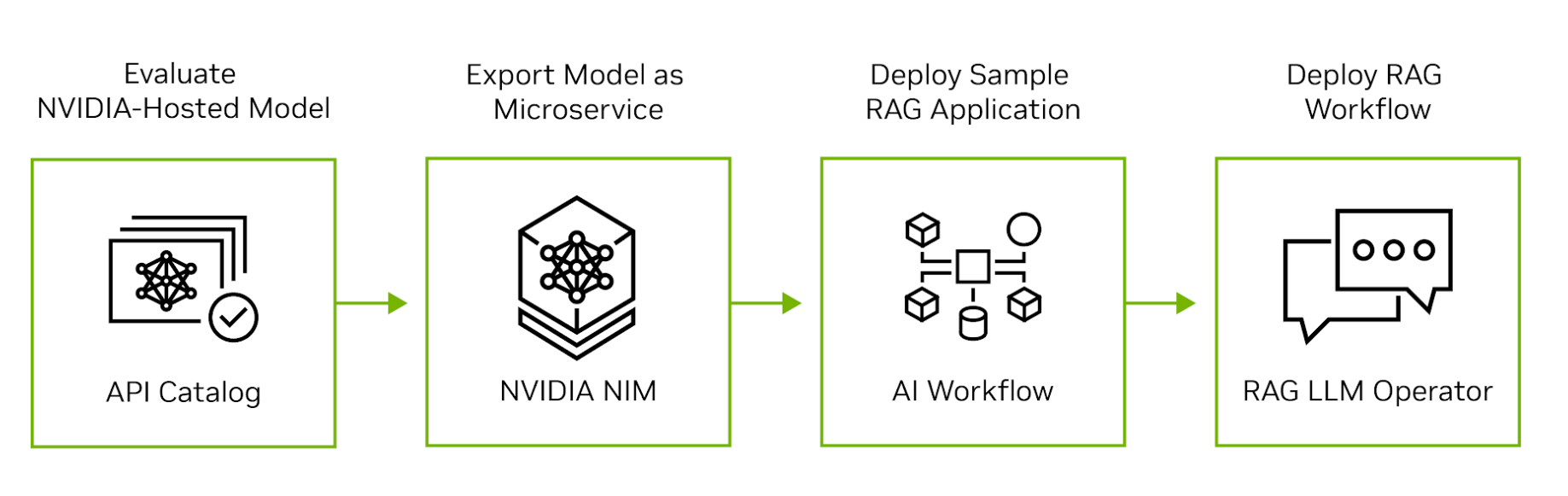
Paso 1. Evaluar los LLM en el Catálogo de API de NVIDIA
Comience visitando el catálogo de API de NVIDIA para experimentar los principales modelos comerciales y de código abierto que se ejecutan en GPU NVIDIA. Los desarrolladores pueden interactuar con los modelos a través de una interfaz de usuario y, a continuación, ver las llamadas a la API de back-end generadas por la interacción. Las llamadas a la API se pueden exportar como fragmentos de código de Python, Go o TypeScript, o como scripts de shell.
Paso 2. Exportación de un Modelo como Microservicio
A continuación, exporte un modelo como NVIDIA NIM. Un NIM es un microservicio autohospedado y fácil de usar diseñado para acelerar la implementación de la IA generativa. El microservicio se puede ejecutar como un contenedor en una máquina virtual en cualquier nube principal o se puede instalar en un clúster de Kubernetes a través de Helm. Si le preocupa la privacidad o la seguridad de los datos, puede evaluar el modelo en su propio data center o nube privada virtual.
Paso 3. Desarrollar una Aplicación RAG de Ejemplo
Después de evaluar el modelo autohospedado, explora los Ejemplos de IA Generativa de NVIDIA para escribir aplicaciones RAG de ejemplo. Los ejemplos ilustran cómo los microservicios de NVIDIA se integran con los frameworks de programación LLM de código abierto populares para producir pipelones RAG de extremo a extremo. Los científicos de datos pueden usar estos ejemplos para ajustar el rendimiento de las aplicaciones y evaluar su precisión. Los clientes de NVIDIA AI Enterprise también tienen acceso a los workflows de IA de NVIDIA que demuestran cómo los ejemplos de IA generativa se pueden aplicar a casos de uso específicos de la industria.
Paso 4. Implementación del Pipeline de RAG en Producción
Una vez desarrollada la aplicación, los administradores de MLOps pueden usar el operador NVIDIA RAG LLM para implementarla en un espacio de nombres de prueba o producción. Ahora disponible para acceso anticipado, el operador RAG LLM permite una implementación rápida y sencilla de aplicaciones RAG en clústeres de Kubernetes sin tener que reescribir ningún código de aplicación.
El operador RAG LLM se ejecuta sobre el Operador de GPU NVIDIA, un popular software de infraestructura que automatiza la implementación y administración de GPU NVIDIA en Kubernetes. Reduce la complejidad de la gestión del ciclo de vida y permite la implementación, el escalado y la gestión sin problemas de los pipelines RAG.
Pipelines RAG de Producción que Mejoran la Productividad
Los sistemas RAG de producción pueden aumentar la productividad de los trabajadores al reducir el trabajo duro, facilitar la búsqueda de datos pertinentes y automatizar eventos.
NVIDIA utiliza un pipeline RAG para ayudar a crear software empresarial seguro. La herramienta de análisis CVE de NVIDIA combina NVIDIA NIM, NeMo Retriever y el framework de IA de ciberseguridad de Morpheus para identificar y clasificar vulnerabilidades y exposiciones comunes (CVE) en contenedores NGC. Este proceso empresarial crítico, que garantiza la integridad de todos los contenedores publicados en el registro de contenedores de NGC, ahora tarda horas en lugar de días.
Organizaciones como Deepset, Sandia National Laboratories, Infosys, Quantiphi, Slalom y Wipro están desbloqueando información valiosa con la IA generativa de NVIDIA, lo que permite la búsqueda semántica de datos empresariales.
La nueva integración de Haystack 2.0 de Deepset con NVIDIA NIM y NeMo Retriever ayuda a las organizaciones a examinar de manera eficiente los LLM acelerados por GPU para admitir la creación rápida de prototipos de aplicaciones RAG.
Sandia National Laboratories y NVIDIA están colaborando para evaluar las herramientas emergentes de IA generativa para maximizar la información de los datos y mejorar la precisión y el rendimiento.
Infosys ha ampliado su colaboración estratégica con NVIDIA al combinar Infosys Generative AI, parte de Infosys Topaz, con NVIDIA NeMo para crear aplicaciones RAG listas para la empresa para diversas industrias. Estas aplicaciones alteran las normas y ofrecen valor para los casos de uso, desde la automatización de informes de ensayos clínicos biofarmacéuticos hasta la búsqueda de información a partir de más de 100.000 documentos financieros patentados.
Quantiphi incorpora la IA generativa acelerada de NVIDIA para desarrollar soluciones basadas en RAG que pueden extraer información de vastos repositorios de documentos de descubrimiento de fármacos y ayudar a ofrecer resultados innovadores mediante la optimización de las cadenas de suministro minoristas adaptadas a la demografía y la geolocalización.
Slalom ayuda a las organizaciones a navegar por las complejidades de la IA generativa y los RAG, incluido el diseño, la implementación y la gobernanza, con un framework sólido para mitigar los riesgos y garantizar la aplicación responsable de la IA.
Al trabajar con herramientas de IA generativa, Wipro está ayudando a las organizaciones del área de la salud a mejorar los resultados a través de la mejora de la prestación de servicios a millones de pacientes en los Estados Unidos.
Comenzar
Las empresas recurren cada vez más a la IA generativa para resolver desafíos empresariales complejos y mejorar la productividad de los empleados. Muchos también incorporarán IA generativa en sus productos. Las empresas pueden confiar en la seguridad, el soporte y la estabilidad que proporciona NVIDIA AI Enterprise para trasladar sus aplicaciones RAG del piloto a la producción. Y, al estandarizar la IA de NVIDIA, las empresas obtienen un socio comprometido que les ayuda a seguir el ritmo del ecosistema de LLM en rápida evolución.
Explora los Ejemplos de IA Generativa de NVIDIA para comenzar a crear un chatbot que pueda responder con precisión preguntas específicas del dominio en lenguaje natural utilizando información actualizada.
Para conocer las últimas innovaciones y las prácticas recomendadas para crear aplicaciones RAG, consulte las sesiones de generación aumentada de recuperación en NVIDIA GTC 2024. Mira on demand al RAG Developer Day para aprender a crear una aplicación impulsada por RAG con una interfaz de voz humana.