
Los grandes modelos de lenguaje (LLM – Large Language Models) han generado entusiasmo en todo el mundo debido a su capacidad para comprender y procesar el lenguaje humano a una escala sin precedentes. Ha transformado la forma en que interactuamos con la tecnología.
Al haber sido capacitados en un vasto corpus de texto, los LLM pueden manipular y generar texto para una amplia variedad de aplicaciones sin mucha instrucción o capacitación. Sin embargo, la calidad de este resultado generado depende en gran medida de las instrucciones que le dé al modelo, lo que se conoce como indicación. ¿Qué significa esto para ti? Interactuar con los modelos hoy en día es el arte de diseñar un mensaje en lugar de diseñar la arquitectura del modelo o los datos de entrenamiento.
Tratar con LLM puede tener un costo dada la experiencia y los recursos necesarios para construir y entrenar sus modelos. NVIDIA NeMo ofrece modelos de lenguaje previamente entrenados que se pueden adaptar de manera flexible para resolver casi cualquier tarea de procesamiento de lenguaje, mientras que nosotros podemos concentrarnos por completo en el arte de obtener los mejores resultados de los LLM disponibles.
En esta publicación, analizo algunas formas de moverse con los LLM, para que puedas aprovecharlos al máximo. Para obtener más información sobre cómo comenzar con los LLM, consulte An Introduction to Large Language Models: Prompt Engineering and P-Tuning.
Mecanismo Detrás de la Incitación
Antes de entrar en las estrategias para generar resultados óptimos, dé un paso atrás y comprenda lo que sucede cuando solicita un modelo. El mensaje se divide en fragmentos más pequeños llamados tokens y se envía como entrada al LLM, que luego genera los siguientes tokens posibles según el mensaje.
Tokenización
Los LLM interpretan los datos textuales como tokens. Los tokens son palabras o fragmentos de caracteres. Por ejemplo, la palabra «sándwich» se dividiría en los tokens «sánd» y «wich», mientras que palabras comunes como «tiempo» y «gustar» serían un token único.
NeMo utiliza codificación de pares de bytes para crear estos tokens. El mensaje se divide en una lista de tokens que el LLM toma como entrada.
Generación
Detrás de las cortinas, el modelo primero genera logits para cada token de salida posible. Los logits son una función que representa valores de probabilidad de 0 a 1 y de infinito negativo a infinito. Luego, esos logits se pasan a una función softmax para generar probabilidades para cada salida posible, brindándole una distribución de probabilidad sobre el vocabulario. Aquí está la ecuación de softmax para calcular la probabilidad real de un token:

En la fórmula, 


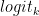
Luego, el modelo seleccionaría la palabra más probable y la agregaría a la secuencia de indicaciones.

Mientras el modelo decide cuál es el resultado más probable, usted puede influir en esas probabilidades girando hacia arriba y hacia abajo algunos controles de parámetros del modelo. En la siguiente sección, analizo cuáles son esos parámetros y cómo ajustarlos para obtener los mejores resultados.
Modificar los Parámetros
Para desbloquear todo el potencial de los LLM, explore el arte de perfeccionar los resultados. Estas son las categorías de parámetros clave que se deben considerar modificar:
- Informe al modelo cuándo detenerse
- Previsibilidad versus creatividad
- Reducir la repetición
Experimente con estos parámetros y descubra las mejores combinaciones que funcionen para su caso de uso específico. En muchos casos, experimentar con el parámetro de temperatura puede obtener lo que necesita. Sin embargo, si tiene algo específico y desea un control más granular sobre la salida, comience a experimentar con los demás.
Informe al Modelo Cuándo Detenerse
Hay parámetros que pueden guiar al modelo para decidir cuándo dejar de generar más texto:
- Número de Tokens
- Palabras Vacías
Número de Tokens
Anteriormente mencioné que el LLM se centra en generar el siguiente token dada la secuencia de tokens. El modelo hace esto en un bucle agregando el token predicho a la secuencia de entrada. No querrás que el LLM siga y siga.
Si bien existe un límite en la cantidad de tokens que van desde 2048 a 4096 que los modelos NeMo pueden aceptar por ahora, no recomiendo alcanzar estos límites ya que el modelo puede generar respuestas incorrectas.
Palabras Vacías
Las palabras vacías son un conjunto de secuencias de caracteres que le indican al modelo que deje de generar texto adicional, incluso si la longitud de salida no ha alcanzado el límite de token especificado.
Esta es otra forma de controlar la duración de la salida. Por ejemplo, si se le solicita al modelo que complete la siguiente oración “El cielo es azul, los limones son amarillos y las limas son” y usted especifica la palabra de parada simplemente “.”, el modelo se detiene después de terminar solo esta oración, incluso si el token límite es mayor que la secuencia generada (Figura 2).
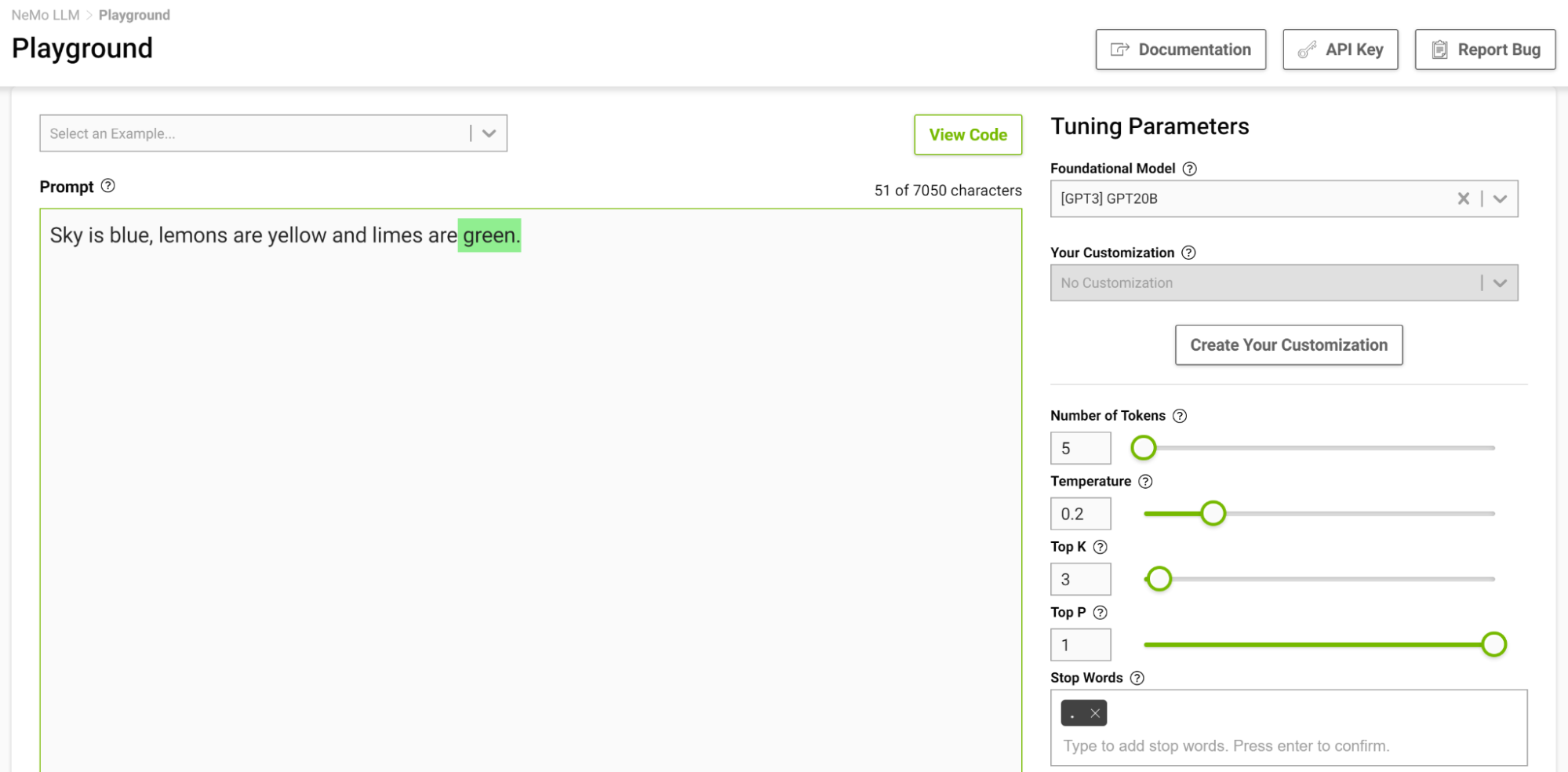
Es especialmente útil diseñar una plantilla de parada en una configuración de unos pocos disparos para que el modelo pueda aprender a detenerse adecuadamente al completar una tarea prevista. La Figura 3 muestra ejemplos separados con la cadena “===” y pasándola como palabra de parada.
Previsibilidad versus Creatividad
Si se le solicita, es posible generar diferentes resultados según los parámetros que establezca. Según la aplicación del LLM, puedes optar por aumentar o disminuir la capacidad creativa del modelo. Estos son algunos de estos parámetros que pueden ayudarle a hacerlo:
- Temperatura
- Top-k y Top-p
- Ancho de búsqueda del haz
Temperatura
Este parámetro controla la capacidad creativa de su modelo. Como se analizó anteriormente, mientras genera el siguiente token en la secuencia de entrada, el modelo genera una distribución de probabilidad. El parámetro de temperatura ajusta la forma de esta distribución, lo que genera una mayor diversidad en el texto generado.
A una temperatura más baja, el modelo es más conservador y se limita a elegir tokens con mayores probabilidades. A medida que aumenta la temperatura, ese límite se vuelve indulgente, lo que permite al modelo elegir palabras menos probables, lo que da como resultado un texto más impredecible y creativo.
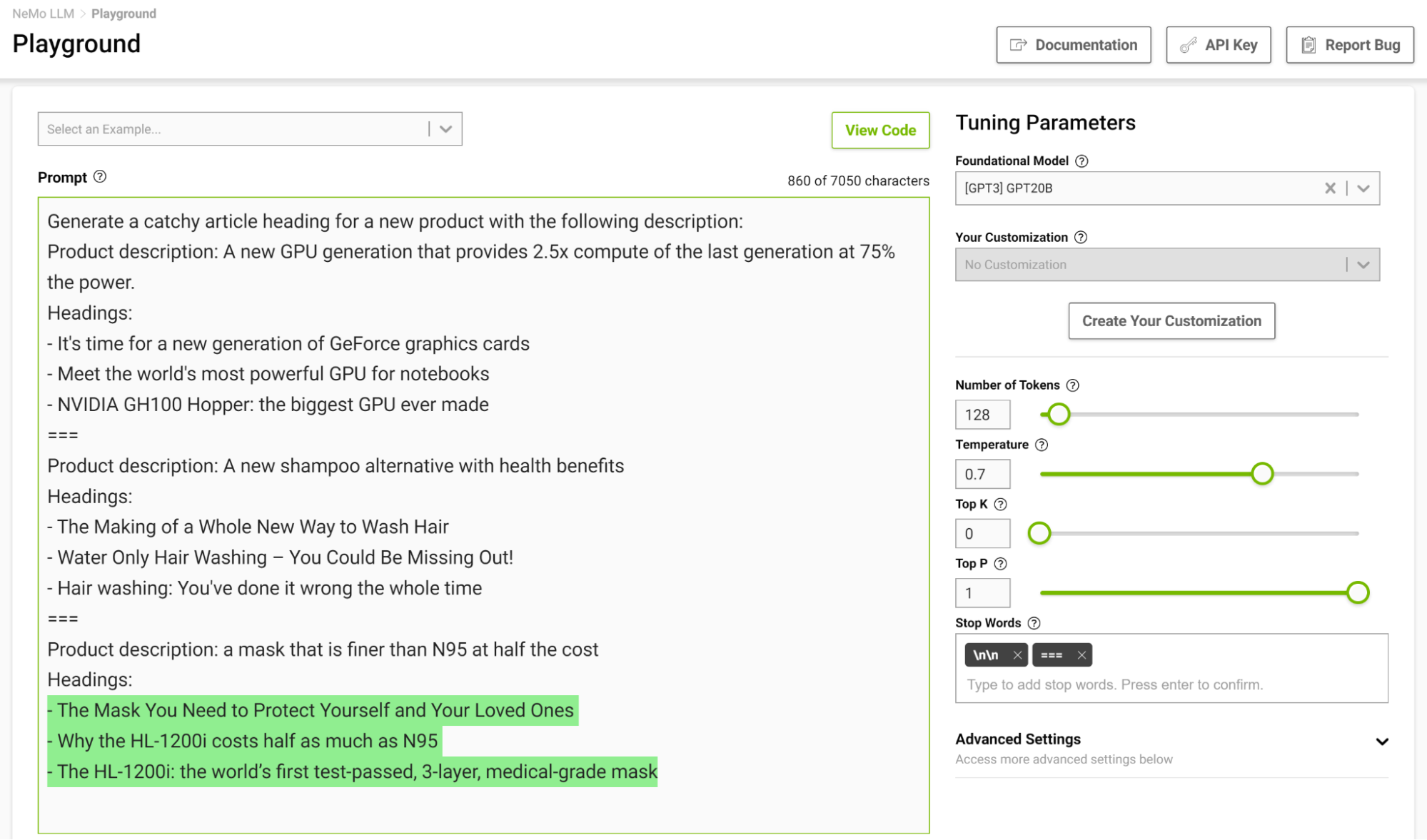
La Figura 4 muestra cómo se le asigna al modelo la tarea de completar la oración que comienza con “El océano”, donde se establece la temperatura en 0,1.
Cuando piensas en completar una frase de este tipo, probablemente pienses en frases como “…es enorme” o “…es azul”. El resultado es prácticamente un simple hecho de que el océano es grande y tiene muchos peces.
Ahora, intente esto nuevamente con la temperatura configurada en 1 (Figura 5).
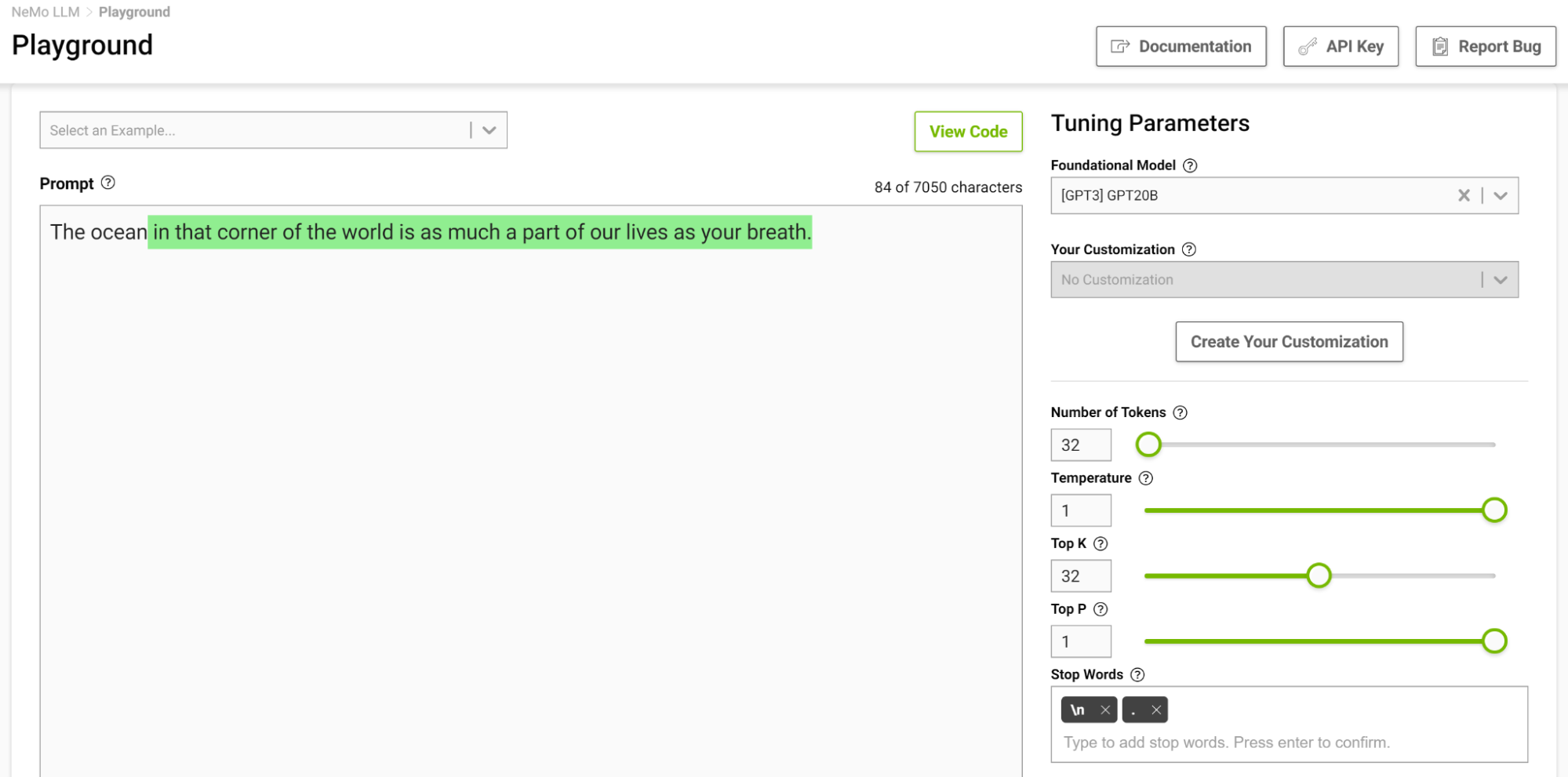
El modelo empezó a darte analogías en las que normalmente no piensas. Las temperaturas más altas son adecuadas para tareas que requieren escritura creativa, como poemas e historias. Pero tenga en cuenta que el texto generado a veces también puede resultar absurdo. Las temperaturas más bajas son adecuadas para tareas más definitivas, como responder preguntas o resumir.
Recomiendo experimentar con diferentes valores de temperatura para encontrar la mejor temperatura para su caso de uso. El rango [0,5, 0,8] debería ser un buen punto de partida en el playground de servicio de NeMo.
Top-k y Top-p
Estos dos parámetros también controlan la aleatoriedad de la selección del siguiente token. Top-k le dice al modelo que debe conservar los k tokens de mayor probabilidad, de los cuales se selecciona al azar el siguiente token. Los valores más bajos reducen la aleatoriedad, ya que se recortan tokens con menos probabilidades de generar texto predecible. Si k se establece en 0, Top-k no se utiliza. Cuando se establece en 1, siempre seleccionará el token más probable a continuación.
Puede haber casos en los que la distribución de probabilidad del posible token sea amplia cuando hay tantos tokens probables. También puede haber casos en los que la distribución sea estrecha y solo haya unos pocos tokens que sean más probables.
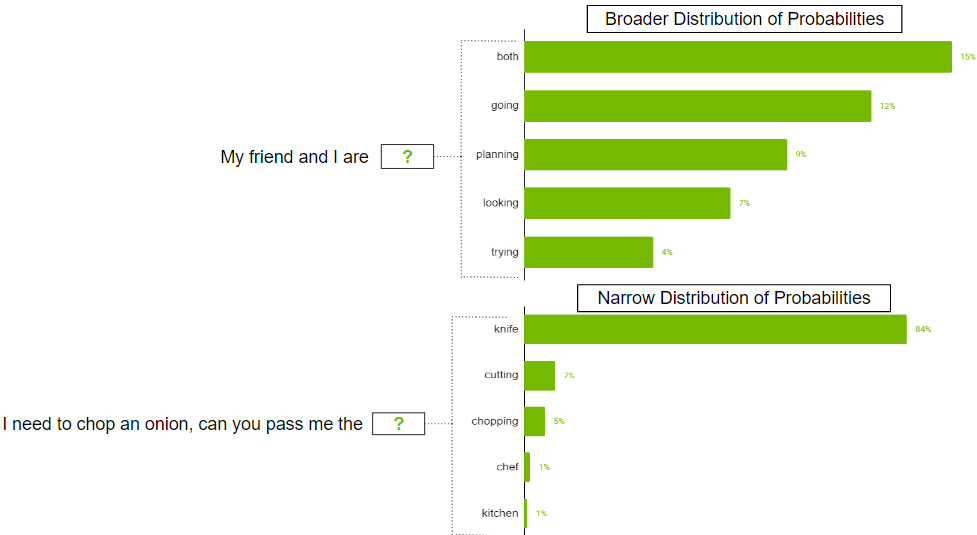
Probablemente no desee restringir estrictamente el modelo para que solo seleccione los k tokens principales en el escenario de distribución más amplio. Para solucionar esto, se puede utilizar el parámetro top-p donde el modelo selecciona al azar entre los tokens de mayor probabilidad cuyas probabilidades suman o superan el valor top-p. Si top-p se establece en 0,9, puede ocurrir uno de los siguientes escenarios:
- En el ejemplo de distribución más amplio, se pueden considerar los 50 tokens principales cuya suma de probabilidades sea igual o superior a 0,9.
- En el escenario de distribución estrecha, puedes superar 0,9 solo con los dos tokens superiores. De esta manera, evitará elegir entre fichas aleatorias y, al mismo tiempo, conservará la variedad.
Ancho de Búsqueda del Haz
Este es otro parámetro útil que puede controlar la diversidad de salidas. La búsqueda por haz es un algoritmo comúnmente utilizado en muchos modelos de PNL y reconocimiento de voz como paso final en la toma de decisiones para elegir el mejor resultado dadas las opciones posibles. El ancho de búsqueda del haz es un parámetro que determina el número de candidatos que el algoritmo debe considerar en cada paso de la búsqueda.
Los valores más altos aumentan las posibilidades de encontrar un buen resultado, pero eso también conlleva el costo de más cálculos.
Reducir la Repetición
A veces, es posible que el texto repetido no sea deseable en el resultado. Si este es el caso, utilice el parámetro de penalización por repetición para ayudar a reducir la repetición.
Penalización por Repetición
Este parámetro puede ayudar a penalizar los tokens según la frecuencia con la que aparecen en el texto, incluido el mensaje de entrada. Una ficha que ya ha aparecido cinco veces se penaliza más que una ficha que ha aparecido sólo una vez. Un valor de 1 significa que no hay penalización y los valores mayores que 1 desalientan la repetición de tokens.
Estrategias de Pocas Posibilidades para un Diseño Rápido Eficaz
El diseño rápido es crucial para generar resultados relevantes y coherentes de los LLM. Tener estrategias para un diseño de indicaciones eficaz puede ayudar a crear indicaciones que sean relevantes y, al mismo tiempo, evitar errores comunes como el sesgo, la ambigüedad o la falta de especificidad. En esta sección, comparto algunas estrategias clave para un diseño de mensajes efectivos.
Preguntar con Restricciones
Restringir el comportamiento del modelo mediante un diseño cuidadoso puede resultar muy útil. Usted sabe que los modelos lingüísticos, en esencia, intentan predecir la siguiente palabra en una secuencia. Es posible que el modelo de lenguaje no entienda una descripción de tarea que tenga perfecto sentido para un ser humano. Esta es la razón por la que el aprendizaje en pocas oportunidades suele funcionar bien: a medida que se demuestra un patrón al modelo, éste hace un buen trabajo al adherirse a él.
Considere el siguiente mensaje: «Traduzca del inglés al francés: hoy es un hermoso día.»
Con esta indicación, el modelo probablemente intentaría continuar la oración o agregar más oraciones en lugar de realizar la traducción. Cambiando el mensaje a «Traduce esta oración del inglés al francés: Hoy es un hermoso día.» aumenta la probabilidad de que el modelo comprenda esta tarea como una tarea de traducción y genere un resultado más confiable.
¡Los Caracteres Importan!
Como vio en el ejemplo de traducción anterior, pequeños cambios pueden generar resultados variados. Otra cosa para tener en cuenta es que los tokens a menudo se generan con un espacio inicial, por lo que caracteres como el espacio y la siguiente línea también pueden afectar sus resultados. Si un mensaje no funciona, intente cambiar la forma en que lo estructuró.
Considere Ciertas Frases
A menudo, cuando desee que su modelo responda sus indicaciones de manera lógica y llegue a conclusiones precisas o simplemente que haga que el modelo logre un resultado determinado, puede considerar el uso de las siguientes frases:
- Pensemos en esto paso a paso: esto anima al modelo a abordar un problema de manera lógica y llegar a respuestas precisas. Este estilo de motivación también se conoce como promoción de cadena de pensamiento (CoT).
- En el estilo de <persona notable>: Esto coincide con el estilo de escritura de la persona notable. Por ejemplo, para generar texto como Shakespeare o Edgar Allen Poe, agréguelo al mensaje y la generación coincidirá estrechamente con su estilo de escritura.
- Como <profesión/rol>: esto ayuda al modelo a comprender mejor el contexto de la pregunta. Con una mejor comprensión, el modelo suele dar mejores respuestas.
Solicitar con el Conocimiento Generado
Para obtener respuestas más precisas, puede solicitar al LLM que genere conocimientos potencialmente útiles sobre una pregunta determinada antes de generar una respuesta final (Figura 7).

Este tipo de error muestra que los LLM a veces requieren más conocimientos para responder una pregunta. Los siguientes ejemplos muestran cómo generar algunos datos sobre la puntuación de golf en un entorno de pocos golpes.
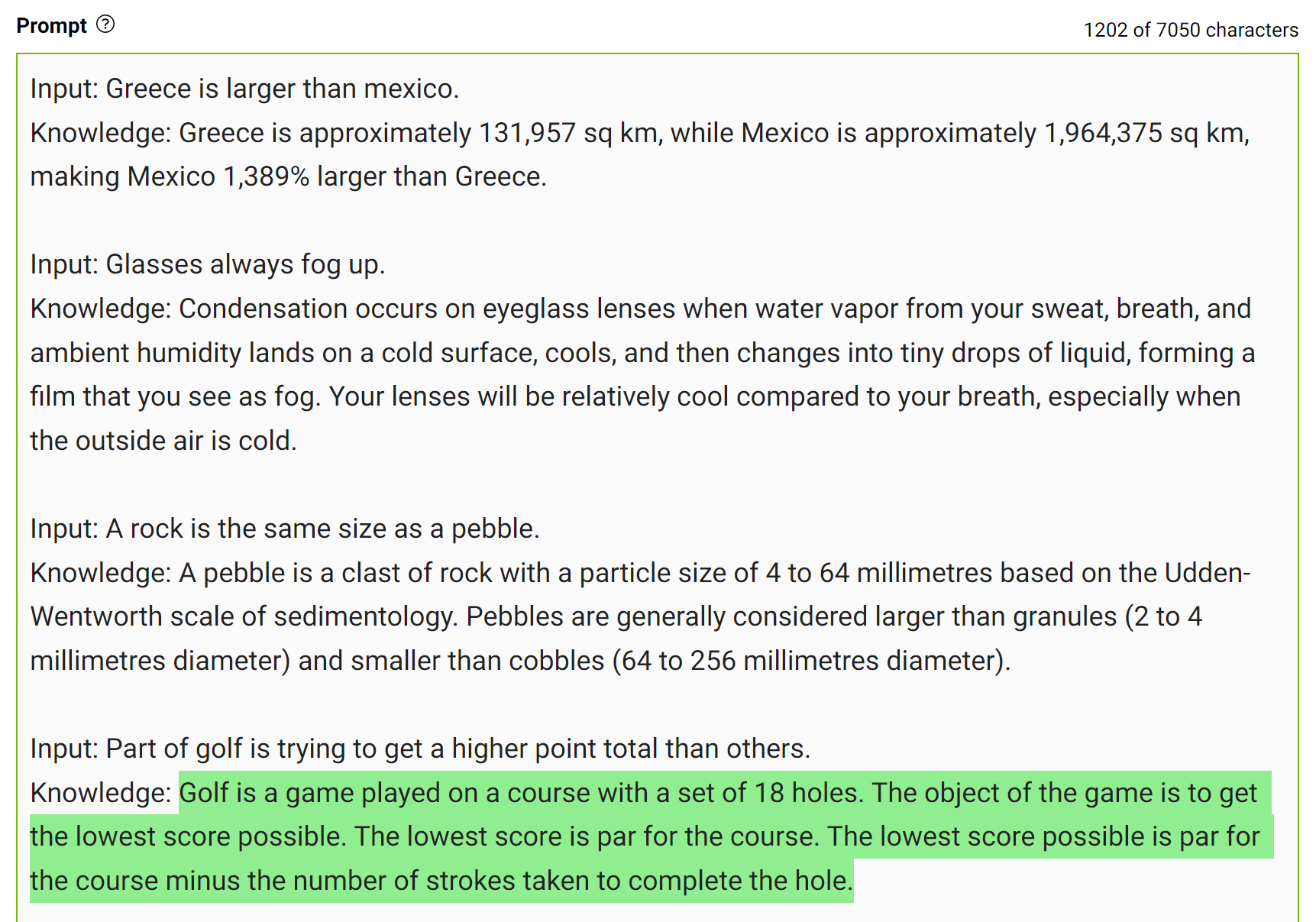
Integre este conocimiento en la mensaje y vuelva a hacer la pregunta.
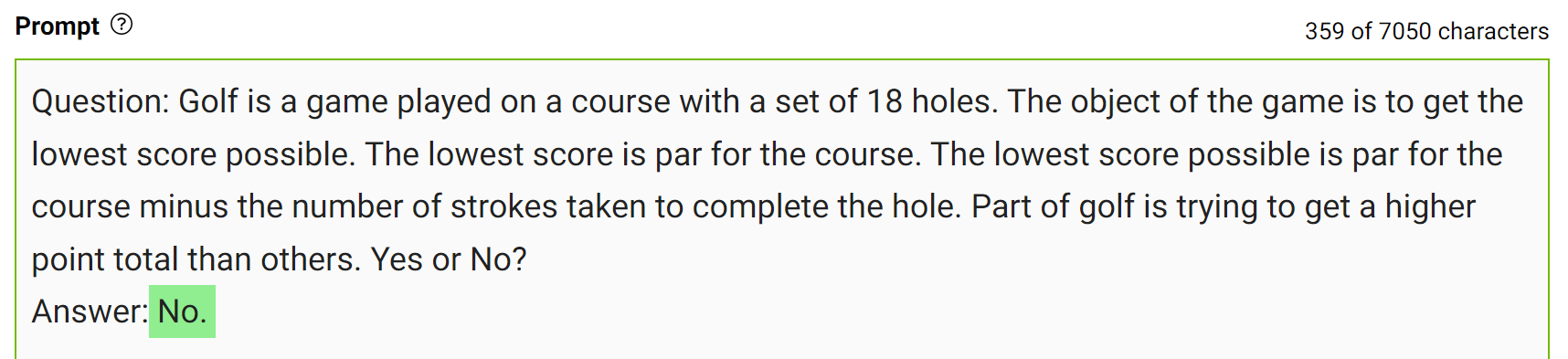
La modelo respondió con confianza «No» a la misma pregunta. Ésta es una demostración sencilla de este tipo de indicaciones. Sin embargo, hay algunos detalles más a considerar antes de llegar a la respuesta final. Para obtener más información, consulte Generated Knowledge Prompting for Commonsense Reasoning.
En la práctica, genera múltiples respuestas y selecciona la respuesta que ocurre con más frecuencia como la final.
¡Experimenta con Ello!
La mejor manera de escribir indicaciones que se ajusten a su caso de uso es experimentar y jugar. Es una experiencia de aprendizaje diseñar un mensaje que pueda brindarle los resultados correctos, ya sea cómo lo escribe o la forma en que configura los parámetros del modelo.
El playground de servicio de NeMo puede ayudarlo a probar sus indicaciones y diseñar su caso de uso. Si está interesado en acceder al playground, consulte el Servicio NVIDIA NeMo.
Conclusión
En esta publicación, compartí formas de generar mejores resultados de los LLM. Hablé sobre cómo se podrían modificar los parámetros del modelo para obtener los resultados deseados y algunas estrategias