
NVIDIA Groq 3 LPX es un nuevo acelerador de inferencia a escala de bastidor para la plataforma NVIDIA Vera Rubin, diseñado para la baja latencia y las grandes demandas de contexto de los sistemas agénticos. LPX, diseñado conjuntamente con NVIDIA Vera Rubin NVL72, equipa a la fábrica de IA con un motor optimizado para la generación rápida y predecible de tokens, mientras que Vera Rubin NVL72 sigue siendo el caballito de batalla flexible y de propósito general para el entrenamiento y la inferencia, lo que ofrece un alto rendimiento en el precargado y la decodificación, incluido el procesamiento en contexto largo, la atención de la decodificación y el servicio de alta simultaneidad a escala.
Esta combinación es importante porque el futuro agéntico exige una nueva categoría de inferencia. A medida que las velocidades de generación se acercan a los 1,000 tokens por segundo por usuario, los modelos se mueven más allá de la interacción a velocidad de conversación hacia la computación a la velocidad del pensamiento. A ese ritmo, los sistemas de IA pueden razonar, simular y responder de forma continua, lo que posibilita experiencias que se sienten menos como un chat por turnos y más como la colaboración en tiempo real.
Este cambio también eleva el techo para los sistemas de múltiples agentes. Los agentes individuales pueden ser potentes por sí solos, pero los grupos coordinados de agentes pueden lograr mucho más, al igual que las sociedades humanas escalan su capacidad a través de la inteligencia colectiva y la coordinación.
La compatibilidad con estas cargas de trabajo emergentes requiere una infraestructura que pueda ofrecer un alto rendimiento y una latencia extremadamente baja. La combinación de Vera Rubin NVL72 y LPX posibilita esta arquitectura heterogénea, que combina el desempeño de las fábricas de IA a gran escala con la generación rápida de tokens necesaria para impulsar sistemas agénticos en ejecución continua y aplicaciones de IA de última generación.
Presentamos NVIDIA Groq 3 LPX
Vera Rubin y LPX unen el desempeño extremo de las GPU y LPU Rubin para ofrecer un rendimiento de inferencia por megavatio hasta 35 veces mayor y una oportunidad de ingresos hasta diez veces mayor para modelos de billones de parámetros. Integrado con la arquitectura de bastidores NVIDIA MGX ETL y alineado con la plataforma Vera Rubin más amplia, LPX brinda a los centros de datos una forma de implementar una ruta de inferencia de baja latencia dedicada junto con Vera Rubin NVL72, dentro de un diseño de infraestructura común.
El sistema se desarrolla en torno a 256 aceleradores de LPU NVIDIA Groq 3 interconectados. Su arquitectura enfatiza la ejecución determinista, el alto ancho de banda SRAM en el chip y la comunicación de escalabilidad estrechamente coordinada, para que la inferencia interactiva pueda seguir respondiendo, incluso a medida que aumenta la concurrencia y varían las formas de solicitud.
LPX, implementado junto con Vera Rubin NVL72, acelera las porciones sensibles a la latencia del bucle de decodificación, incluida la ejecución de expertos en FFN y MoE, mientras que las GPU Rubin continúan manejando el precargado y la atención de la decodificación. Juntos, ofrecen una ruta de servicio heterogénea que mejora la capacidad de respuesta interactiva sin sacrificar el rendimiento de las fábricas de IA.

A escala de bastidor, LPX ofrece:
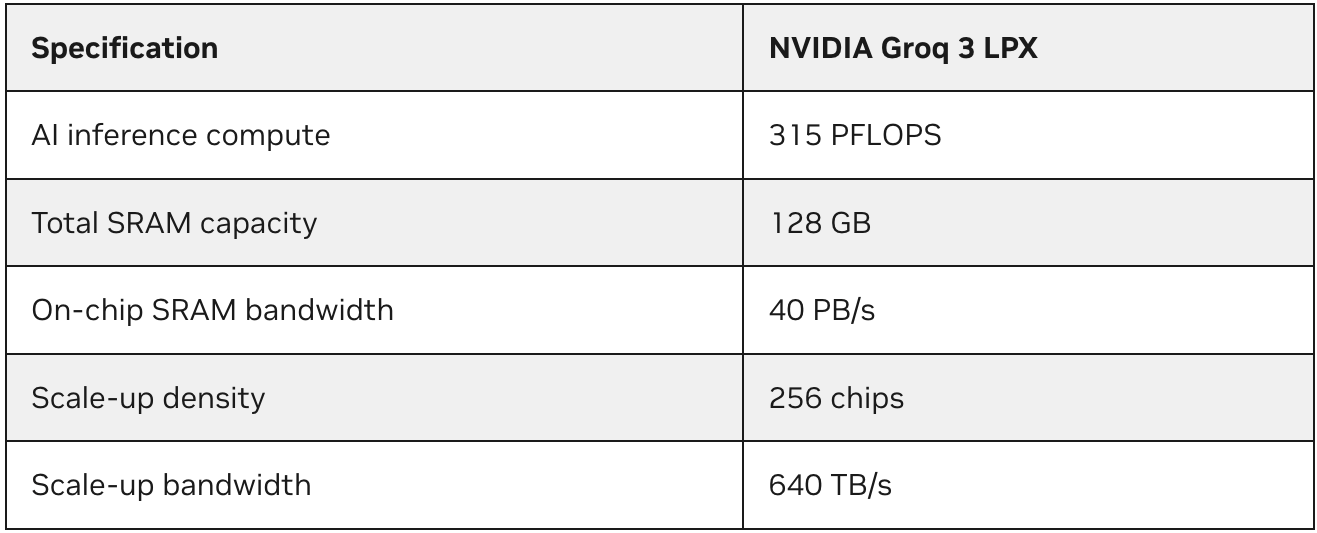
Vera Rubin NVL72 y LPX crean una arquitectura de inferencia más heterogénea para la fábrica de IA, una que pueda admitir una alta producción de tokens agregados y experiencias de IA interactivas con capacidad de respuesta.
Dentro de la bandeja de computación NVIDIA Groq 3 LPX
El acelerador a escala de bastidor LPX alberga 32 bandejas de computación de 1U refrigeradas por líquido, cada una diseñada para admitir la inferencia de baja latencia a escala. Cada bandeja integra ocho aceleradores de LPU, un procesador host y la lógica de expansión de estructura en un diseño sin cables que simplifica la implementación a escala de bastidor y acopla estrechamente la computación con la comunicación.
Los enlaces de LPU chip a chip (C2C) proporcionan comunicación directa dentro de la bandeja, entre las bandejas a través de la columna LPU C2C y entre los bastidores a medida que los sistemas escalan. La conectividad es importante porque la inferencia interactiva no es solo computación sin procesar. También depende de la eficiencia con la que el sistema pueda mover datos, coordinar el trabajo y evitar retrasos variables a medida que las solicitudes fluyen entre dispositivos.

Cada bandeja proporciona:
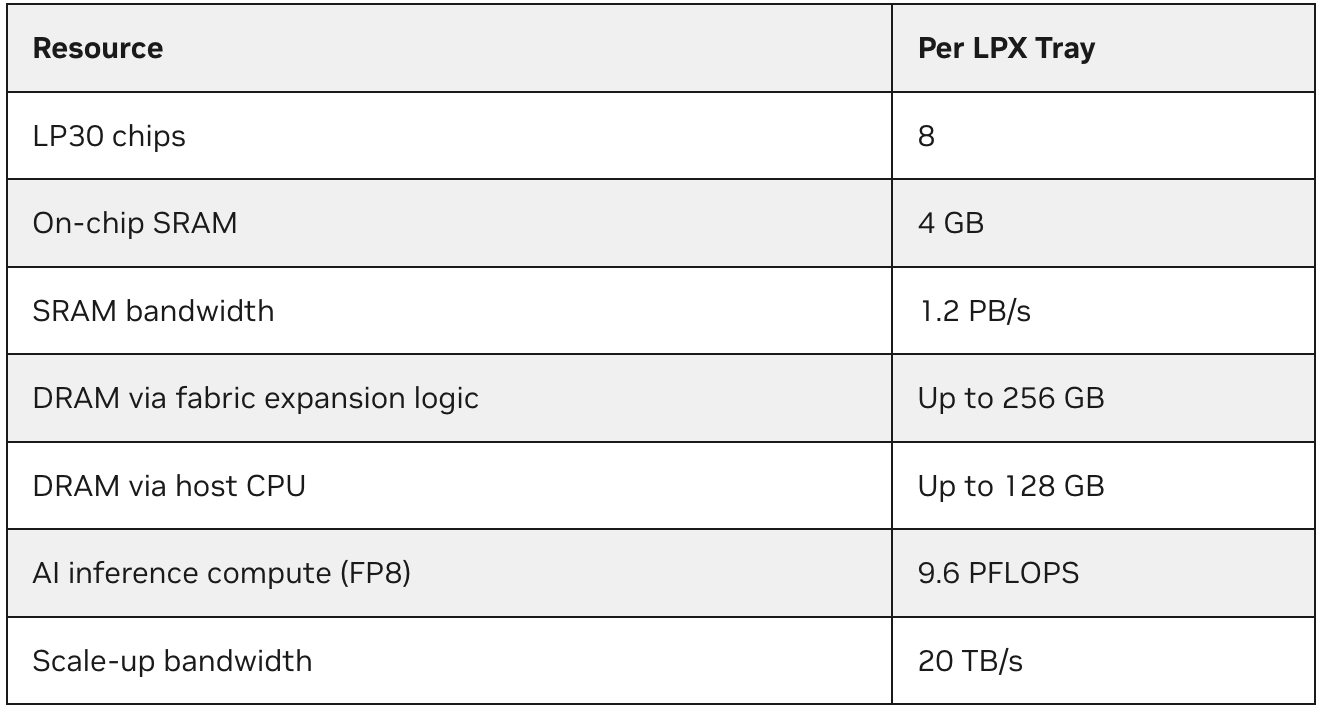
A nivel de sistema, LPX está desarrollado para regímenes de inferencia en los que la sobrecarga de coordinación y la fluctuación pueden volverse rápidamente visibles para los usuarios. Esto es especialmente relevante a medida que más aplicaciones de IA se alejan del servicio sin conexión u orientado al rendimiento y hacia la generación interactiva. Para ver cómo LPX está optimizado para ese régimen, resulta útil observar la arquitectura del procesador en el núcleo del sistema: la LPU NVIDIA Groq 3.
Un primer vistazo a la arquitectura de la LPU NVIDIA Groq 3: el séptimo chip de la plataforma Vera Rubin
En el corazón de LPX está la LPU NVIDIA Groq 3, diseñada para ofrecer una generación de tokens rápida y predecible mediante el acoplamiento estrecho de la computación, la memoria y la comunicación bajo el control del compilador. La arquitectura de la LPU está diseñada para ofrecer una generación de tokens rápida y predecible, acoplando estrechamente la computación, la memoria y la comunicación bajo el control del compilador. En lugar de optimizar solo para el rendimiento aritmético máximo, la LPU enfatiza la ejecución determinista, el alto ancho de banda de memoria en el chip y el movimiento de datos explícito. Estas capacidades son especialmente importantes para los regímenes de inferencia de decodificación dominante y sensibles a la latencia.

Computación con prioridad tensorial y movimiento explícito de datos
La computación y la comunicación en la LPU están organizadas en torno a vectores de 320 bytes como unidad de trabajo. Las operaciones aritméticas, el acceso a memoria y las transferencias entre dispositivos operan en estos vectores de tamaño fijo, lo que simplifica la programación y la sincronización.
Los módulos de ejecución especializados manejan diferentes clases de operaciones:
- Los módulos de ejecución de matrices (MXM) proporcionan una capacidad densa de multiplicación y acumulación para operaciones tensoriales, operando en tipos de datos fijos con un rendimiento predecible.
- Los módulos de ejecución vectorial (VXM) manejan aritmética puntual y conversiones de tipos y funciones de activación mediante una malla de unidades lógicas aritméticas (ALU) por carril.
- Los módulos de ejecución de switches (SXM) realizan movimiento de datos estructurados, incluida la permutación, la rotación, la distribución y la transposición de vectores.
Al hacer que el movimiento de datos sea explícito y programable, la LPU permite que el acceso a la memoria, la computación y la comunicación se superpongan, en lugar de depender de la heurística de hardware.
MEM permite un ancho de banda de memoria en el chip extremo
Un elemento central de la LPU es el bloque MEM: una arquitectura de memoria plana centrada en SRAM, en la que 500 MB de SRAM de alta velocidad en el chip sirven como el principal almacenamiento de trabajo para la inferencia. En lugar de depender de cachés administradas por hardware, el compilador y el tiempo de ejecución colocan el conjunto de trabajo activo, incluidos los pesos, las activaciones y el estado de KV, en la memoria en el chip y mueven los datos de forma explícita. Esto reduce los estancamientos impredecibles y ayuda a ofrecer una latencia baja y estable, al mantener los datos más sensibles a la latencia cerca de la computación.
Dado que la capacidad de SRAM en el chip es finita, los modelos más grandes se escalan en muchos aceleradores de LPU interconectados mediante estrategias de ejecución paralela, como la partición por capas, por lo que el sistema general presenta un conjunto de trabajo efectivo mucho mayor. En este diseño, el desempeño se rige menos por el rendimiento aritmético máximo y más por la consistencia con que el sistema pueda mantener la computación alimentada, razón por la cual LPX combina 150 TB/s de ancho de banda de memoria en el chip con comunicación de chip a chip (C2C) de alto ancho de banda por LPU.
Escalado de C2C con comunicación predecible
Para escalar la inferencia en múltiples dispositivos, la LPU incluye enlaces C2C de alto radix y alta velocidad diseñados para el intercambio de datos deterministas. Cada LPU se conecta a través de 96 enlaces C2C que se ejecutan a 112 Gbps cada uno, lo que permite una topología optimizada de escalabilidad de LPX con un alto ancho de banda bidireccional de E/S agregado de 2.5 TB/s y una sincronización de comunicación predecible. Esto es especialmente importante para los pipelines de inferencia distribuidos, donde la sobrecarga de comunicación puede convertirse en una fuente importante de latencia.
Ejecución determinista y orquestada por compiladores
La LPU se basa en el modelo de ejecución espacial de Groq, donde el compilador programa explícitamente la computación, el movimiento de datos y la sincronización. En lugar de depender de programadores de hardware dinámicos en el tiempo de ejecución, el compilador confía en el protocolo plesiosincrónico de chip a chip en hardware que cancela la deriva natural del reloj y alinea cientos de aceleradores de LPU para que actúen como un solo sistema coordinado. Con la llegada de datos predecible y la sincronización periódica de software, los desarrolladores pueden razonar más directamente sobre la sincronización, y el sistema puede coordinar el comportamiento de la computación y la red con un determinismo mucho mayor.
Este modelo de ejecución permite:
- Coordinación precisa entre memoria y computación.
- Control explícito sobre la sincronización de instrucciones.
- Fluctuación de ejecución reducida bajo cargas de trabajo variables
Para la inferencia en tiempo real, este determinismo ayuda a mantener estables el tiempo hasta el primer token y la latencia por token, incluso en tamaños de lotes pequeños.
El cambio hacia la inferencia interactiva
La inferencia de IA abarca un amplio espectro de desempeño. Por un lado, hay servicios optimizados en cuanto a rendimiento, como el procesamiento de documentos por lotes, la moderación, las incrustaciones y los pipelines de medios, donde el objetivo es maximizar los tokens por GPU, los tokens por vatio o la eficiencia de costos general. Estas cargas de trabajo a menudo admiten servicios compartidos a gran escala, incluidas las ofertas de IA de nivel gratuito y en segundo plano, donde la alta utilización importa más que la capacidad de respuesta por usuario.
En el otro extremo están los servicios optimizados para latencia, como asistentes de codificación, chatbots, asistentes de voz, copilotos y agentes interactivos, donde los retrasos son inmediatamente visibles para los usuarios. En estas cargas de trabajo, las métricas más importantes son el tiempo hasta el primer token, los tokens por segundo por usuario y la latencia de cola. Muchas plataformas de IA modernas deben admitir ambos regímenes simultáneamente, ejecutando backends de alto rendimiento para el procesamiento a gran escala, a la vez que ofrecen experiencias interactivas con capacidad de respuesta. Esta divergencia es una de las razones por las cuales las arquitecturas de inferencia heterogéneas se están volviendo cada vez más importantes.
Qué hace que la inferencia interactiva sea más difícil
Varias tendencias están haciendo que la inferencia interactiva de baja latencia sea más importante y más difícil de servir de manera eficiente, como se muestra en la Tabla 3. A medida que los modelos producen resultados más largos y crecen las ventanas contextuales, una parte mayor de la carga de trabajo cambia a la decodificación, donde los tokens se generan secuencialmente y la capacidad de respuesta se expone directamente al usuario.

Al mismo tiempo, los contextos más largos aumentan la presión sobre el ancho de banda de memoria y el movimiento de datos, mientras que el servicio a muchos usuarios simultáneos reduce la eficiencia de procesamiento por lotes de la que dependen los sistemas orientados al rendimiento. Como resultado, los sistemas optimizados para el máximo rendimiento agregado no siempre son la mejor opción para las cargas de trabajo que requieren una generación de tokens rápida y predecible para cada solicitud.
Este desafío se vuelve aún más pronunciado en la IA agéntica, donde los sistemas pasan repetidamente por ciclos de inferencia, recuperación, uso de herramientas y razonamiento. En estos bucles, la latencia se acumula en cada paso, lo que hace que el desempeño estable por token y el comportamiento sólido de latencia de cola sean críticos para experiencias de usuario con capacidad de respuesta.
La era de la inferencia agéntica requiere una nueva arquitectura
La inferencia no es una carga de trabajo única y uniforme. Dentro de una solicitud, el precargado y la decodificación generan diferentes demandas en el hardware, y esas demandas cambian con el tamaño del lote, la longitud del contexto y la estructura del modelo. Algunas fases, como la autoatención y el MoE disperso, pueden volverse altamente sensibles al ancho de banda de memoria y al movimiento de datos, mientras que otras, como la proyección densa y las capas de retroalimentación, escalan de manera eficiente en hardware optimizado para el rendimiento cuando hay suficiente paralelismo disponible. En la decodificación interactiva, muchas operaciones se ejecutan en tamaños de lotes muy pequeños, lo que hace que la latencia sea mucho más sensible a los estancamientos, la contención y la fluctuación.
La optimización de todo el pipeline para un solo régimen fuerza una solución de compromiso. El hardware ajustado para el rendimiento máximo en grandes lotes no es ideal para las rutas de ejecución más sensibles a la latencia, mientras que el hardware optimizado para la ejecución de baja latencia es menos eficiente para las fases con mayor uso intensivo de computación.
Como se muestra en la Figura 4, un sistema heterogéneo combina ambos enfoques, vinculando el desempeño interactivo de baja latencia con un alto rendimiento de las fábricas de IA. El resultado es una arquitectura de dos motores: las GPU ofrecen un alto rendimiento para el precargado con contexto intenso y ejecutan la atención de decodificación, mientras que las LPU aceleran los componentes de decodificación sensibles a la latencia, como la ejecución de FFN/MoE. Juntos mejoran la interactividad sin sacrificar el rendimiento de las fábricas de IA.

Vera Rubin NVL72 se une a LPX
La inferencia moderna es una carrera de relevos. El mismo hardware que ejecuta el tramo de contexto intenso no necesita asegurar el sprint hacia el siguiente token. Las GPU Rubin son los caballos de batalla flexibles y de propósito general para el entrenamiento y la inferencia. Ofrecen un alto rendimiento en muchos tamaños de modelos, regímenes de lotes y patrones de servicio, desde el precargado de contexto largo hasta la decodificación de la atención y la inferencia de alta concurrencia a escala.
LPX agrega una ruta especializada optimizada para la generación de tokens rápida y sensible a la latencia. Juntos, permiten un diseño de inferencia heterogéneo que mejora la capacidad de respuesta interactiva sin renunciar a la eficiencia a escala de sistema.

Fase de decodificación: Un bucle de múltiples motores repetido
La fase de precargado está dominada por la ingesta de grandes entradas y el desarrollo de la caché de KV, una carga de trabajo que se beneficia de la computación paralela densa y la gran capacidad de memoria. Vera Rubin NVL72 maneja esta fase de manera eficiente, especialmente para cargas de trabajo de contexto largo y modelos MoE, donde el contexto puede ser grande y altamente variable.
La fase de decodificación es diferente. La decodificación es un bucle por token repetido, y diferentes partes de ese bucle enfatizan diferentes cuellos de botella. En la arquitectura de la plataforma Vera Rubin con LPX, la decodificación se considera mejor como un bucle de dos motores. Las GPU manejan el trabajo de decodificación que más se beneficia del rendimiento y la gran capacidad de memoria, como la atención contextual completa sobre la caché de KV acumulada. LPX acelera la ejecución sensible a la latencia dentro del decodificador, como las redes neuronales de alimentación directa (FFN) de MoE dispersas y otras operaciones puntuales. Esta división, a menudo descrita como desagregación de fase de decodificación o desagregación de FFN de atención (AFD), separa la atención de la FFN dentro de la decodificación e intercambia activaciones intermedias para cada token, por lo que cada motor ejecuta la parte del bucle para la cual está mejor adaptado. Este bucle de AFD expande la región operativa de mayor valor de la frontera de Pareto.

A escala de bastidor y más allá, el LPX está diseñado para operar como una unidad de computación estrechamente coordinada, lo que minimiza la sobrecarga de coordinación y reduce la fluctuación. Esto es valioso en flujos de trabajo agénticos con uso intensivo de decodificación, donde los pequeños retrasos se combinan en muchas llamadas de modelos y bucles de verificación.
NVIDIA Dynamo hace operativa la decodificación heterogénea
Hacer que la decodificación heterogénea sea práctica requiere software que pueda clasificar solicitudes, enrutar el trabajo por objetivos de latencia, mover activaciones intermedias con baja sobrecarga y mantener estable la latencia de cola bajo un tráfico variable y en ráfagas. NVIDIA Dynamo proporciona esa capa de orquestación mediante la coordinación del servicio desagregado y la decodificación desagregada en backends heterogéneos.
En la práctica, Dynamo enruta el precargado previo a los trabajadores de GPU para procesar el contexto y desarrollar la caché de KV. Durante la decodificación, Dynamo orquesta el bucle de AFD en el que las GPU dirigen la atención sobre la caché de KV acumulada, las activaciones intermedias se transfieren a las LPU para la ejecución de FFN/MoE y los resultados vuelven a las GPU para continuar la generación de tokens. El resultado es una sola ruta de servicio coherente con una latencia de cola más predecible, a la vez que se mantiene un alto rendimiento de las fábricas de IA.

Con el enrutamiento sensible a KV, las transferencias de baja sobrecarga y la programación basada en objetivos de latencia, Dynamo ayuda a mantener las sesiones interactivas fuera de largas colas, reduce la fluctuación entre usuarios y mantiene una latencia de cola estable a medida que varían la simultaneidad y las formas de solicitud. El resultado es un modelo de servicio heterogéneo listo para la producción que ofrece experiencias de usuario con capacidad de respuesta, a la vez que mantiene un alto rendimiento de las fábricas de IA a escala.
Aceleración de la decodificación especulativa con LPX
La decodificación especulativa es una técnica cada vez más importante para reducir la latencia en la inferencia de LLM. El enfoque usa un modelo borrador más pequeño para generar múltiples tokens candidatos con anticipación, mientras que un modelo objetivo más grande verifica y acepta esos tokens en paralelo. Cuando las predicciones coinciden, se pueden confirmar múltiples tokens a la vez, lo que aumenta significativamente los tokens efectivos por segundo y reduce la latencia de respuesta.
LPX es muy adecuado para actuar como el motor de generación de borradores en esta arquitectura. El modelo de ejecución determinista y el ancho de banda SRAM en el chip extremadamente alto de la LPU permiten una generación de tokens muy rápida, lo que permite al modelo borrador ejecutarse antes que el verificador. Al mismo tiempo, las GPU como Rubin siguen siendo altamente eficientes para tareas de ejecución de grandes modelos, como el precargado, el procesamiento de atención y la verificación de tokens.
Al emparejar los dos, el sistema combina los puntos fuertes de ambos procesadores:
- LPX genera tokens borrador rápidamente mediante su arquitectura de baja latencia.
- Las GPU Rubin verifican y finalizan tokens de manera eficiente mediante la computación de alto rendimiento y la gran capacidad de memoria.
Esta separación permite ejecutar la decodificación especulativa en procesadores heterogéneos, en lugar de ejecutar tanto el modelo de borrador como el de verificación en el mismo hardware. El resultado es un sistema que puede ofrecer una generación de borradores más rápida sin sacrificar la eficiencia de la verificación basada en GPU.

Habilitación de enjambres de agentes inteligentes
A medida que los casos de uso de la IA evolucionan de simples chats e inferencia por lotes a flujos de trabajo de agentes de múltiples pasos, la capacidad de respuesta se convierte en un requisito. La inferencia fuera de línea y los asistentes básicos a menudo pueden priorizar el rendimiento agregado, pero las aplicaciones interactivas, la investigación profunda y los pipelines de agentes combinan un alto volumen de tokens con bucles de retroalimentación estrechos, donde la latencia se compone en muchas llamadas de modelos e interacciones de herramientas.
En este régimen, la inferencia heterogénea es importante. El emparejamiento de un motor de alto rendimiento para el procesamiento en contexto largo con un motor de baja latencia para FFN de decodificación permite aumentar la interactividad del usuario sin sacrificar la producción de las fábricas de IA.

Habilitación de una nueva categoría de experiencias de IA en la frontera de Pareto
Una forma práctica de visualizar esta compensación entre desempeño y costo es la frontera de Pareto, trazando la interactividad del usuario, medida en tokens por segundo por usuario (TPS por usuario), en el eje horizontal, frente al rendimiento de las fábricas de IA, medido en tokens por segundo por megavatio (TPS por MW), en el eje vertical.
Como se muestra en la Figura 10, diferentes servicios de IA operan en puntos muy diferentes en esta curva. Los servicios centrados en el rendimiento, incluidas muchas cargas de trabajo de nivel gratuito y en segundo plano, normalmente priorizan la máxima eficiencia y la alta utilización, y a menudo usan modelos más pequeños con ventanas contextuales más cortas. Los servicios de IA premium, por el contrario, exigen una mayor capacidad de modelos y un desempeño visible para el usuario con mucha más capacidad de respuesta, especialmente para el razonamiento de contexto largo y los flujos de trabajo agénticos. En la Figura 10, esa capa premium está representada por un modelo MoE de 2 billones de parámetros con una ventana contextual de entrada de 400,000 tokens que opera a aproximadamente 400 TPS por usuario y más.

El hecho de alcanzar estos puntos operativos premium con una sola plataforma homogénea obliga a una compensación entre la capacidad de respuesta y el rendimiento general de las fábricas de IA, porque la carga de trabajo mezcla regímenes de desempeño fundamentalmente diferentes dentro del mismo pipeline de servicio. Una arquitectura heterogénea expande la región a la cual se puede llegar al combinar rutas de ejecución complementarias, lo que permite al sistema mantener una alta producción de fábrica, a la vez que ofrece experiencias interactivas altamente receptivas y de baja latencia. Como se ilustra en la Figura 10, la combinación de Vera Rubin NVL72 y LPX ofrece un TPS por megavatio hasta 35 veces mayor a 400 TPS por usuario, en comparación con NVIDIA GB200 NVL72, lo que crea efectivamente una nueva capa de desempeño premium para los servicios de IA interactivos.
Este cambio tiene un impacto económico directo. Una mayor capacidad de respuesta expande el conjunto de experiencias premium que una fábrica de IA puede ofrecer y aumenta el valor por unidad de infraestructura. Con la plataforma Vera Rubin, las fábricas de IA pueden generar hasta 5 veces más ingresos por megavatio en comparación con GB200 NVL72, y hasta diez veces más mediante el emparejamiento de Vera Rubin NVL72 con LPX para las cargas de trabajo interactivas de alto valor y más sensibles a la latencia, como la codificación agéntica y los sistemas de múltiples agentes.

Lo que NVIDIA Groq 3 LPX posibilita para los desarrolladores
Los desarrolladores están creando cada vez más sistemas que requieren tres cosas a la vez:
- Capacidad de respuesta: Latencia baja y predecible para experiencias interactivas y bucles de agentes.
- Capacidad: Calidad sólida de modelos, profundidad de razonamiento y comprensión de contexto largo.
- Escala: Alto rendimiento y eficiencia de costos para servir a muchos usuarios o agentes simultáneos.
LPX amplía el conjunto de cargas de trabajo a las que una fábrica de IA puede servir de manera eficiente. Use la ruta de baja latencia donde la generación predecible de tokens mejora la experiencia, como los asistentes de codificación, los flujos de trabajo de agentes con bucles estrechos de llamada de herramientas, las interacciones de voz y la traducción en tiempo real. Conserve las cargas de trabajo centradas en el rendimiento en las GPU Rubin, como el servicio por lotes, las ejecuciones de rendimiento en contexto largo, donde la alta concurrencia y el procesamiento por lotes mantienen las GPU constantemente ocupadas y rentables. El cambio operativo es la mentalidad requerida. Deje de optimizar para una métrica principal y comience a optimizar para una gama de puntos operativos del mundo real.
Más Información
Profundice en la arquitectura detrás de NVIDIA Groq 3 LPX y Vera Rubin, comenzando con las páginas de productos de NVIDIA y los blogs técnicos que cubren la plataforma Vera Rubin, LPX, AFD y Dynamo. Explore la investigación subyacente sobre los procesadores de streaming tensoriales y el diseño de silicio definido por software para la IA. Juntos, estos recursos ofrecen una mirada más profunda sobre el hardware, la arquitectura de sistemas y el software de orquestación detrás de la inferencia heterogénea y de baja latencia a escala. A continuación, únase a un hilo del Foro de Desarrolladores de NVIDIA centrado en la inferencia y la implementación para comparar notas con otros equipos que desarrollan sistemas de servicio de baja latencia.
Recursos
- Página de NVIDIA LPX
- Comunicado de Prensa: NVIDIA Vera Rubin Abre la Frontera de la IA Agéntica
- Blog de Tecnología: Dentro de la Plataforma NVIDIA Rubin: Seis Chips Nuevos, Una Supercomputadora de IA
- Blog de Tecnología: NVIDIA Vera Rubin POD: Siete Chips, Cinco Sistemas a Escala de Bastidor, Una Supercomputadora de IA
- Blog Tecnológico: Anunciamos NVIDIA Dynamo 1.0: Escalado de la Inferencia de Múltiples Nodos en la Producción
- Video: El Futuro de la Inferencia de IA – Explicación sobre la AFD de Desagregación de Atención-FFN (a partir de las 18:00)
- Blog Tecnológico: La CPU NVIDIA Vera Ofrece Alto Desempeño, Ancho de Banda y Eficiencia para las Fábricas de IA
- Documento de Investigación: Piense Rápido: Un Procesador de Streaming Tensorial (TSP) para Acelerar las Cargas de Trabajo de Aprendizaje Profundo
- Documento de Investigación: Un Multiprocesador de Streaming Tensorial Definido por Software para el Aprendizaje Automático a Gran Escala
- Video: Habilitación de las Mil Operaciones de PyTorch para el Diseño de Silicio Centrado en el Software
Agradecimientos
Gracias a Amr Elmeleegy, Andrew Bitar, Andrew Ling, Graham Steele, Itay Neeman, Jamie Li, Omar Kilani, Santosh Raghavan y Stuart Pitts, junto con muchos otros líderes de productos, ingenieros y arquitectos de NVIDIA que contribuyeron a esta