La IA generativa está transformando la computación, allanando nuevas vías para que los humanos interactúen con las computadoras de forma natural e intuitiva. Para las empresas, la perspectiva de la IA generativa es enorme. Las empresas pueden aprovechar sus conjuntos de datos enriquecidos para agilizar las tareas que consumen mucho tiempo, desde el resumen y la traducción de textos hasta la predicción de información y la generación de contenido. Pero también deben sortear los desafíos de la adopción.
Por ejemplo, los servicios en la nube ejecutados por grandes modelos de lenguaje (LLM) de uso general simplifican la exploración. Sin embargo, es posible que estas características no siempre se alineen con las necesidades de la empresa, ya que los modelos se entrenan en conjuntos de datos amplios, en lugar de datos específicos del dominio.
Como tal, las organizaciones están creando soluciones personalizadas con innumerables herramientas de código abierto. Desde la validación de la compatibilidad hasta la prestación de su propio soporte técnico, esto puede alargar el tiempo para adoptar con éxito la IA generativa en las empresas.
Diseñado para el desarrollo empresarial, NVIDIA NeMo es una plataforma integral para crear aplicaciones personalizadas de IA generativa en cualquier lugar. Ofrece un conjunto de microservicios de última generación para permitir un workflow completo, desde la automatización del procesamiento de datos distribuidos hasta el entrenamiento de modelos a medida a gran escala mediante sofisticadas técnicas de paralelismo 3D, pasando por la conexión a sus datos privados mediante la generación aumentada de recuperación (RAG).
Los modelos personalizados de IA generativa creados con NeMo se pueden implementar en NVIDIA NIM, un conjunto de microservicios fáciles de usar diseñados para acelerar la implementación de IA generativa en cualquier lugar, en las instalaciones o en la nube.
Para las empresas que ejecutan su negocio en IA, NVIDIA AI Enterprise es la plataforma de software de extremo a extremo que proporciona el tiempo de ejecución más rápido y eficiente para los modelos básicos de IA generativa. Incluye NeMo y NIM para agilizar la adopción con seguridad, estabilidad, capacidad de gestión y soporte de clase empresarial.
Ahora, las organizaciones pueden integrar la IA en sus operaciones, agilizando los procesos, mejorando las capacidades de toma de decisiones e impulsando un mayor valor.
IA Generativa Lista para la Producción con NVIDIA NeMo
NeMo simplifica el camino hacia la creación de modelos de IA generativa personalizados y de nivel empresarial al proporcionar capacidades de extremo a extremo como microservicios, así como recetas para varias arquitecturas de modelos (Figura 1).
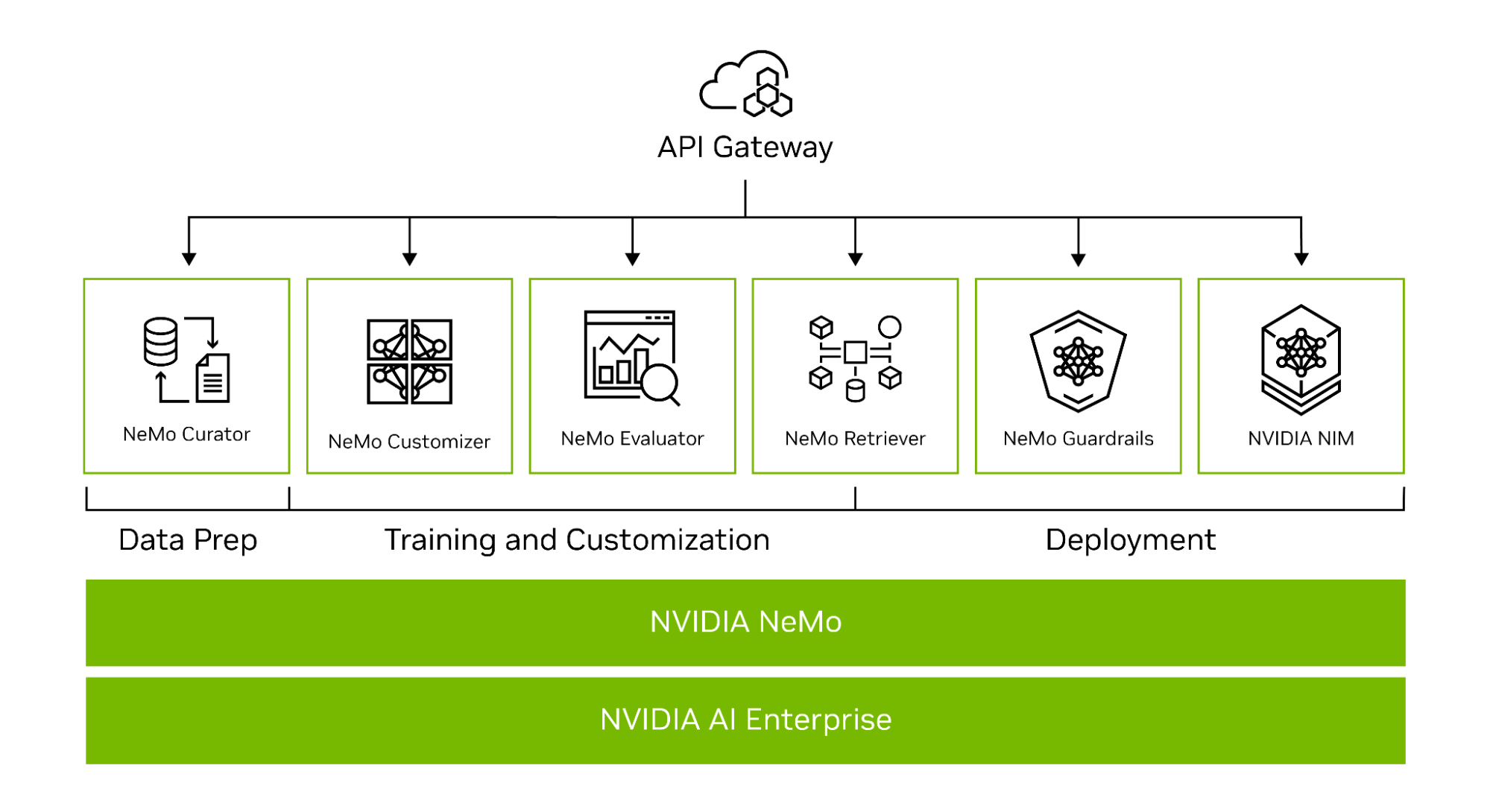
Para ayudarte a crear LLM personalizados, el marco NeMo proporciona potentes herramientas:
- NeMo Curator para la curación de datos acelerada por GU de conjuntos de datos de entrenamiento de alta calidad
- NeMo Customizer para simplificar el ajuste fino y la alineación de los LLM
- NeMo Evaluator para la evaluación automática de la precisión de los LLM
- NeMo Retriever para conectar modelos personalizados a datos empresariales patentados mediante RAG
- NeMo Guardrails para proteger las aplicaciones de IA generativa de una organización
NeMo Curator
La demanda de conjuntos de datos de alta calidad se ha convertido en un factor crítico en la creación de LLM funcionales.
NeMo agiliza el proceso, a menudo complejo, de la curación de datos con NVIDIA NeMo Curator, que aborda los desafíos de la selección de billones de tokens en conjuntos de datos multilingües. A través de su escalabilidad, esta herramienta le permite manejar sin esfuerzo tareas como la descarga de datos, la extracción de texto, la limpieza, el filtrado, la deduplicación exacta o difusa y la descontaminación de tareas posteriores multilingües. Para obtener más información, consulte Escalar y Conservar Conjuntos de Datos de Alta Calidad para la Capacitación de LLM con NeMo Curator.
Aprovechando el poder de tecnologías de vanguardia como Dask, RAPIDS cuDF, RAPIDS cuGraph y PyTorch, NeMo Curator puede escalar los procesos de curación de datos en miles de GPU en red, lo que reduce significativamente los esfuerzos manuales y acelera el workflow de desarrollo.
Uno de los avances más sorprendentes se encuentra en el proceso de deduplicación de datos, donde se ha demostrado que la aceleración de la GPU supera significativamente a los métodos tradicionales de la CPU. El uso de una GPU para la deduplicación es hasta 26 veces más rápido y 6,5 veces más barato que confiar en un enfoque basado en CPU. Esta notable mejora no solo reduce los costos, sino que también aumenta la eficiencia, lo que permite a los desarrolladores procesar datos a un ritmo sin precedentes.
La escalabilidad de la tecnología NVIDIA no tiene parangón, con la capacidad de utilizar miles de GPU. Esta escalabilidad es crucial para preparar grandes conjuntos de datos previos al entrenamiento dentro de frameworks de tiempo realistas, una tarea que se está volviendo cada vez más importante a medida que los modelos de IA crecen en complejidad y tamaño.
En lo que respecta al rendimiento, los LLM se benefician significativamente cuando se entrenan con tokens preparados por el NeMo Curator. Esta herramienta garantiza que los datos que se envían a los LLM sean de la más alta calidad, lo que conduce a modelos de mejor rendimiento.
En un futuro próximo, NeMo Curator también admitirá la curación de datos para la personalización del modelo, como el ajuste fino supervisado (SFT) y los enfoques de ajuste fino eficiente de parámetros (PEFT), incluidos LoRA y P-tuning.
Solicite acceso anticipado a los microservicios de NVIDIA NeMo para obtener el microservicio NeMo Curator más reciente. También viene empaquetado en el contenedor del framework NeMo, disponible a través del catálogo NVIDIA NGC.
Formación Distribuida a Gran Escala
Existen distintos desafíos de aceleración y escala cuando se entrenan LLM de mil millones de parámetros desde cero. La tarea requiere una amplia potencia de computación distribuida, clústeres de hardware y memoria basados en aceleración, frameworks de machine learning (ML) fiables y escalables y sistemas tolerantes a fallos.
En el núcleo del framework NeMo se encuentra la unificación del entrenamiento distribuido y el paralelismo avanzado. NeMo utiliza de forma experta los recursos de la GPU y la memoria en todos los nodos, lo que se traduce en un aumento de la eficiencia sin precedentes. Al dividir el modelo y los datos de entrenamiento, NeMo permite un entrenamiento sin problemas de múltiples nodos y múltiples GPU, lo que reduce significativamente el tiempo de entrenamiento y mejora la productividad general.
Técnicas de Paralelismo
Una característica notable de NeMo es la incorporación de varias técnicas de paralelismo:
- Paralelismo de Datos
- Paralelismo de Datos Totalmente Fragmentado (FSDP)
- Paralelismo Tensorial
- Paralelismo de Pipeline
- Paralelismo de Secuencia
- Paralelismo Experto
- Paralelismo de Contexto
Técnicas de Ahorro de Memoria
Además, NeMo admite varios enfoques de ahorro de memoria:
- Recálculo de Activación Selectiva (SAR)
- Descarga de CPU (activación, pesos)
- Atención Flash (FA), Atención de Consultas Agrupadas (GQA), Atención de Consultas Múltiples (MQA), Atención de Ventana Deslizante (SWA)
NeMo es la solución líder para respaldar la capacitación multimodal a escala. La plataforma es compatible con modelos lingüísticos y multimodales, como Llama 2, Falcon, CLIP, Stable Diffusion, LLaVA y varias arquitecturas de IA generativa basadas en texto, como GPT, T5, BERT, Mixture of Experts (MoE) y RETRO. Además de los LLM, NeMo es compatible con varios modelos preentrenados para visión por computadora, reconocimiento automático de voz, procesamiento de lenguaje natural y conversión de texto a voz.
El contenedor del framework NeMo disponible a través del catálogo de NGC proporciona todas las herramientas para que las organizaciones entrenen modelos por su cuenta.
Modelos de NVIDIA AI Foundation
Aunque algunas aplicaciones de IA generativa requieren entrenar un LLM desde cero, la mayoría de las organizaciones utilizan modelos preentrenados para crear sus LLM personalizados. Este enfoque pone en marcha el proceso, ahorrando tiempo y recursos.
Al omitir las fases de recopilación y limpieza de datos necesarias en el vasto conjunto de datos utilizado para entrenar un LLM desde cero, puede centrarse en ajustar el modelo utilizando un conjunto de datos mucho más pequeño que sea específico para sus necesidades. Esto acelera el tiempo hasta la solución final. Además, la carga de la configuración de la infraestructura y el entrenamiento del modelo se reduce considerablemente, ya que los modelos preentrenados vienen con conocimientos preexistentes, listos para ser personalizados.
La precisión es una de las medidas más comunes que se usan para evaluar modelos previamente entrenados, pero también hay otras consideraciones que incluyen el tamaño del modelo, el costo de ajuste, la latencia, el rendimiento y las opciones de licencias comerciales.
NVIDIA facilita a los desarrolladores lograr el mejor rendimiento en una infraestructura acelerada y agiliza la transición a la IA de producción con los modelos NVIDIA AI Foundation.
Los modelos de NVIDIA AI Foundation incluyen modelos líderes de la comunidad optimizados para el rendimiento y modelos NVIDIA de nivel empresarial creados a partir de datos de fuentes responsables.
NVIDIA TensorRT-LLM optimiza los modelos de NVIDIA AI Foundation para la latencia y el rendimiento para ofrecer el máximo rendimiento. La formación se realiza con datos de fuentes responsables. Estos modelos ofrecen resultados similares a los modelos más grandes, lo que los hace ideales para aplicaciones empresariales.
Estos modelos están formateados para aprovechar las técnicas de personalización y paralelismo de NeMo y ajustarse más rápido con datos propietarios.
Con el catálogo de API de NVIDIA recientemente lanzado, los desarrolladores pueden experimentar los modelos directamente desde un navegador o prototipo con puntos de conexión de API alojados en NVIDIA para estos modelos. Y cuando estén listos para la implementación automática, los modelos básicos se pueden descargar y ejecutar en cualquier centro de datos, nube o workstation acelerados por GPU.
NeMo Customizer
Las empresas de diversos sectores requieren capacidades únicas, y la personalización de modelos de IA generativa está evolucionando para adaptarse a sus necesidades. NeMo ofrece una variedad de técnicas de personalización de LLM para refinar los LLM genéricos y preentrenados para casos de uso especializados. NVIDAI NeMo Customizer es un nuevo microservicio escalable y de alto rendimiento que ayuda a los desarrolladores a simplificar el ajuste y la alineación de los LLM.
NeMo Customizer aporta un conjunto de capacidades avanzadas a la vanguardia del desarrollo de modelos de machine learning. Una de sus características más destacadas es la compatibilidad con técnicas de ajuste fino y alineación de última generación, lo que permite a los usuarios lograr un rendimiento superior del modelo ajustando con precisión los modelos a necesidades específicas.
NeMo Customizer aprovecha técnicas avanzadas de paralelismo, que no solo mejoran el rendimiento del entrenamiento, sino que también reducen considerablemente el tiempo necesario para entrenar modelos complejos. Este aspecto es particularmente beneficioso en los entornos de desarrollo acelerados de hoy en día, donde la velocidad y la eficiencia son primordiales.
Diseñado para admitir el ajuste fino de modelos más grandes mediante el escalado a través de múltiples GPU y múltiples nodos, NeMo Customizer aborda uno de los desafíos importantes en el campo del deep learning.
Esta escalabilidad garantiza que incluso los modelos más exigentes se puedan entrenar de manera efectiva, lo que convierte al NeMo Customizer en una herramienta invaluable para investigadores y profesionales que buscan ampliar los límites de lo que es posible con la IA. Para obtener más información, consulte Ajuste y Alineación de LLM Fácilmente con NVIDIA NeMo Customizer.
Las organizaciones pueden solicitar acceso anticipado a los microservicios de NVIDIA NeMo para comenzar a utilizar el microservicio NeMo Customizer. Los desarrolladores pueden comenzar a personalizar los modelos de inmediato utilizando el contenedor de framework NeMo disponible a través del catálogo NGC.
NeMo Evaluator
A medida que las organizaciones adaptan cada vez más los LLM para satisfacer sus necesidades operativas únicas, surge la necesidad crítica de evaluar y optimizar continuamente estos modelos para garantizar que ofrezcan el más alto nivel de precisión y capacidad de respuesta.
Este proceso de evaluación continua es vital no solo para mantener el rendimiento de los modelos en las tareas para las que fueron entrenados originalmente, sino también para garantizar que se adapten de manera efectiva a los nuevos requisitos específicos de la aplicación.
NeMo Evaluator simplifica esta compleja tarea a través de capacidades de evaluación comparativa automatizadas, lo que permite la evaluación integral de LLM preentrenados y ajustados. Esta herramienta es compatible con una amplia gama de modelos, incluidos modelos de base, modelos alineados y LLM específicos de tareas, entre otros, lo que ofrece versatilidad en la evaluación para diversas aplicaciones.
El microservicio proporciona un diseño abierto y extensible, lo que permite la evaluación de modelos con respecto a muchos puntos de referencia académicos populares y conjuntos de datos personalizados. NeMo Evaluator está diseñado para garantizar la eficiencia y la flexibilidad de los LLM que se ejecutan localmente, en cualquier nube o data center. Para obtener más información, consulte Optimizar la Evaluación de LLM para Mejorar la Precisión con NVIDIA NeMo Evaluator.
NeMo Evaluator amplía las capacidades de NeMo Curator y NeMo Customizer para ofrecer un conjunto completo de herramientas para ayudar a las organizaciones a crear modelos de IA generativa personalizados. Solicita acceso anticipado a los microservicios de NVIDIA NeMo.
NeMo Retriever
NeMo Retriever es una colección de microservicios que permite la búsqueda semántica acelerada de datos empresariales para ofrecer respuestas altamente precisas a través del aumento de la recuperación. Para obtener más información, consulte Convertir los Datos de Su Empresa en Información Procesable con NVIDIA NeMo Retriever.
Estos microservicios están diseñados para controlar tareas específicas, entre las que se incluyen:
- Ingesta de grandes volúmenes de documentos en forma de archivos PDF, documentos de Office y otros archivos de texto enriquecido.
- Codificación y almacenamiento de estos documentos para la búsqueda semántica.
- Interactuar con bases de datos relacionales existentes.
- Búsqueda de información relevante para responder preguntas.
Con NeMo Retriever, las organizaciones pueden acceder a capacidades de recuperación de información de clase mundial con la latencia más baja, el rendimiento más alto y la máxima privacidad de datos, lo que permite un mejor uso de los datos patentados para generar información comercial en tiempo real.
Comience hoy mismo con los microservicios de NeMo Retriever en el catálogo de API de NVIDIA. Para obtener más información, consulte los ejemplos de IA Generativa de NVIDIA y ejemplos de código.
NeMo Guardrails
En el panorama de rápida evolución de la IA generativa, no se puede exagerar la importancia de implementar medidas de seguridad sólidas. A medida que estas aplicaciones de IA se integran cada vez más en una amplia gama de industrias, es primordial garantizar su funcionamiento seguro.
Los guardrails sirven como un mecanismo crucial en este sentido, actuando como restricciones o reglas programables que regulan la interacción entre los usuarios y los LLM. De manera similar a la forma en que los guardrails físicos en las autopistas evitan que los vehículos se desvíen de su curso, estos guardrails digitales están diseñados para monitorear, influir y controlar las interacciones de un usuario con los sistemas de IA.
Ayudan a mantener el enfoque de las interacciones de IA dentro de límites predeterminados, evitando la generación de contenido alucinante, tóxico o engañoso y bloqueando comandos maliciosos o acceso no autorizado a aplicaciones de terceros. Este sistema de controles y equilibrios es esencial para preservar la integridad y la seguridad de las aplicaciones de IA generativa en varios dominios.
NeMo Guardrails aborda estos desafíos al ofrecer un sofisticado sistema de gestión de diálogos que prioriza la precisión, la idoneidad y la seguridad en las aplicaciones impulsadas por LLM. Proporciona a las organizaciones las herramientas necesarias para hacer cumplir los protocolos de seguridad y protección de manera efectiva, asegurando que sus sistemas de IA funcionen dentro de los parámetros deseados.
NeMo Guardrails facilita la programación e implementación de estas medidas de seguridad, ofreciendo guardrails programables difusos que permiten interacciones flexibles pero controladas con el usuario. Sus capacidades de integración con soluciones listas para la empresa, incluidas Langchain y otras aplicaciones de terceros, refuerzan la seguridad de los sistemas LLM contra posibles amenazas.
Al integrarse profundamente con el ecosistema LLM más amplio y admitir frameworks populares, NeMo Guardrails garantiza que las aplicaciones de IA generativa permanezcan seguras y alineadas con los valores, políticas y objetivos de la organización. Para obtener más información, consulte NVIDIA Habilita Sistemas Conversacionales de Grandes Modelos de Lenguaje Confiables, Seguros y Protegidos.
NeMo Guardrails es un kit de herramientas de código abierto para desarrollar fácilmente sistemas conversacionales LLM seguros y confiables que funcionan con todos los LLM, incluidos ChatGPT de OpenAI y NVIDIA NeMo. Para comenzar, visite NVIDIA/NeMo-Guardrails en GitHub.
NVIDIA NIM
Para admitir la inferencia de IA en entornos de producción, la infraestructura y los sistemas de soporte deben ser sólidos, escalables y eficientes para facilitar la transición. Las organizaciones están reconociendo la necesidad de invertir y desarrollar este tipo de infraestructuras para seguir siendo competitivas y aprovechar todo el potencial de la IA generativa.
Los microservicios de inferencia NIM de NVIDIA simplifican el camino para implementar modelos de IA generativa optimizados en entornos empresariales. NIM es compatible con un amplio espectro de modelos de IA, desde modelos comunitarios de código abierto hasta modelos de NVIDIA AI Foundation, así como modelos de IA personalizados. Para obtener más información, consulte NVIDIA NIM Ofrece Microservicios de Inferencia Optimizados para Implementar Modelos de IA a Escala.
Al aprovechar las API estándar de la industria, los desarrolladores pueden crear rápidamente aplicaciones de IA de nivel empresarial con solo unas pocas líneas de código. Construido sobre bases sólidas que incluyen motores de inferencia de código abierto como el Servidor de Inferencia NVIDIA Triton, NVIDIA TensorRT-LLM y PyTorch, NIM facilita la inferencia de IA a escala, lo que garantiza que las aplicaciones de IA se puedan implementar a escala con confianza en producción.
Para comenzar con NIM, explora los modelos optimizados en el catálogo de API de NVIDIA.
Lograr Una IA Generativa de Nivel Empresarial Sin Fisuras
Como parte de NVIDIA AI Enterprise, NeMo ofrece compatibilidad con múltiples plataformas, incluidas nubes, data centers y, ahora, workstations y PC con tecnología NVIDIA RTX. Esto permite una verdadera experiencia de desarrollo una vez e implementación en cualquier lugar, elimina las complejidades de la integración y maximiza la eficiencia operativa.
Adoptantes de IA de la Industria
NeMo ya ha ganado una tracción significativa entre las organizaciones con visión de futuro que buscan crear LLM personalizados. ServiceNow, Amdocs, Dropbox, Writer y Korea Telecom han adoptado NeMo, aprovechando sus capacidades para impulsar sus iniciativas impulsadas por IA.
Gracias a su incomparable flexibilidad y soporte, NeMo abre un mundo de posibilidades. Las empresas pueden diseñar, capacitar e implementar sofisticadas soluciones de LLM adaptadas a necesidades específicas y verticales de la industria. Al aprovechar NVIDIA AI Enterprise e integrar NeMo en tus workflows, tu organización puede desbloquear nuevas vías de crecimiento, obtener información valiosa y ofrecer aplicaciones de vanguardia impulsadas por IA a clientes y empleados por igual.
Primeros Pasos con NVIDIA NeMo
NVIDIA NeMo, una solución revolucionaria, está cerrando la brecha entre el vasto potencial de la IA generativa y las realidades prácticas a las que se enfrentan las empresas. Como plataforma integral para el desarrollo y la implementación de LLM, NeMo ayuda a las empresas a adoptar la tecnología de IA de manera eficiente y rentable.
Con las potentes capacidades de NVIDIA NeMo, las empresas pueden integrar la IA en las operaciones, agilizar los procesos, mejorar las capacidades de toma de decisiones y desbloquear nuevas vías de crecimiento y éxito.
Comienza a usar NVIDIA NeMo para crear IA generativa lista para la producción para tu empresa. Para acceder a los microservicios de NVIDIA NeMo, solicite ahora el acceso anticipado. También puede obtener paquetes en el contenedor del framework NeMo, disponible a través del catálogo de NVIDIA NGC.