
En los últimos años, los roles de la IA y el machine learning (ML) en las empresas principales han cambiado. Lo que alguna vez fueron actividades de investigación o desarrollo avanzado, ahora brindan una base importante para los sistemas de producción.
A medida que más empresas buscan transformar sus negocios con IA y ML, más y más personas hablan de MLOps. Si ha estado escuchando estas conversaciones, es posible que haya descubierto que casi todos los involucrados están de acuerdo en que necesita una estrategia de MLOps para que ML entre en producción.
Esta publicación proporciona una breve descripción general de los MLOps empresariales. Para obtener más información, míreme en NVIDIA GTC 2023 en Enterprise MLOps 101, una introducción al panorama de MLOps para empresas. Presenté la sesión con mi colega, Michael Balint.
¿Por qué MLOps es confuso?
La conversación de MLOps es confusa por varias razones clave, que se detallan a continuación.
MLOps Es Amplio
MLOps es un término amplio que describe las tecnologías, los procesos y la cultura que permiten a las organizaciones diseñar, desarrollar y mantener sistemas de ML de producción. Casi cualquier herramienta o sistema que sea relevante para el desarrollo de software convencional, la gestión de datos o la inteligencia comercial podría ser relevante para un sistema de ML de producción.
Debido a que MLOps es un tema popular, muchas herramientas y sistemas que podrían ser relevantes para los sistemas de producción de ML han cambiado de nombre para enfatizar su conexión con MLOps.
MLOps Es Diverso
Los sistemas de machine learning son sistemas de software complejos. Diferentes organizaciones y profesionales adoptarán diversos enfoques para gestionar esta complejidad, tal como lo hacen con la gestión de la complejidad de construir y mantener sistemas de software convencionales.
Sin embargo, debido a que las organizaciones no han estado construyendo sistemas de ML de producción durante tanto tiempo como las organizaciones han estado construyendo software convencional, no se han establecido enfoques estandarizados. También falta la estandarización del lenguaje utilizado para describir estos sistemas y los criterios con los que evaluarlos.
Puede ser confuso cuando diferentes personas hablan de MLOps porque pueden estar describiendo diferentes partes del espacio del problema. Por ejemplo, las partes que son más importantes para su caso de uso, su industria o los procesos y herramientas de su organización.
MLOps Es Complejo
MLOps es legítimamente complejo. Sin embargo, debido a que los practicantes y las organizaciones con experiencia en MLOps se enfocan en los detalles de su enfoque y herramientas particulares, tienden a enfatizar su complejidad. Parte del problema es que, en un dominio en evolución como el machine learning de producción, puede ser difícil descifrar cómo separar la complejidad accidental de la complejidad esencial para presentar una vista simple de un problema complejo.
Superando la Confusión
Una mejor manera de comenzar a abordar MLOps es pensar en lo que su organización está haciendo hoy con el machine learning, lo que le gustaría hacer en el futuro y los desafíos que enfrentará con los sistemas de machine learning como resultado.
¿Qué Problemas Hay que Resolver?
Diferentes problemas de ML imponen diferentes tipos de requisitos en los sistemas de ML. Los problemas que involucran datos no estructurados, como la comprensión de video, audio o lenguaje natural, implican mucho más esfuerzo, incluido el esfuerzo humano manual, para etiquetar ejemplos de capacitación que los problemas que involucran datos comerciales tabulares, en los que el esfuerzo de etiquetado a menudo puede ser trivial o automatizado.
Algunos problemas se benefician de un modelo que solo necesita datos que están disponibles de inmediato desde una sola fuente, mientras que otros enfoques y problemas dependen de la federación de datos históricos y agregados de múltiples fuentes con una nueva observación para hacer una predicción. Las nuevas aplicaciones de ML pueden beneficiarse de un mejor soporte para el desarrollo experimental y exploratorio, mientras que los sistemas maduros pueden beneficiarse más de la automatización del proceso de desarrollo.
Finalmente, los sistemas que automatizan decisiones críticas que pueden afectar vidas humanas, controlar maquinaria peligrosa o administrar carteras financieras deben simularse en una variedad de condiciones, incluidos escenarios poco probables o contradictorios, para validar su idoneidad y seguridad. Si está trabajando con problemas que implican requisitos especiales, asegúrese de llegar a una solución MLOps que pueda ayudarlo a cumplir con esos requisitos.
¿Qué Factores Deben Ser Considerados?
De manera similar, algunas áreas de aplicación y requisitos comerciales imponen requisitos técnicos en los sistemas de machine learning. Las aplicaciones en industrias reguladas a menudo se benefician de poder reproducir y explicar resultados históricos, como explicar una discusión de suscripción financiera o mostrar que los datos personales de un usuario no se usaron para entrenar un modelo.
Las aplicaciones sensibles a la latencia, como la búsqueda, las recomendaciones de medios y la orientación de anuncios, pueden beneficiarse de la infraestructura de servicio que admita la predicción de baja latencia y el resultado de un conjunto de modelos más y menos complejos para mejorar el tiempo de respuesta en el peor de los casos. Muchos problemas de percepción se beneficiarán de la infraestructura para transferir el aprendizaje y servir frameworks que puedan manejar y optimizar modelos grandes y complejos.
¿Cómo Son Los Equipos de Datos y ML Hoy en Día?
Así como el panorama general de ML continúa evolucionando, los roles y las personas de los equipos de datos continúan evolucionando. A principios de la década de 2010, un «científico de datos» era un rol completo que tenía responsabilidades sustanciales de ingeniería de datos y desarrollo de software, así como cierta sofisticación estadística. Hoy en día, los científicos de datos están mucho más especializados. Los equipos ahora incluyen comúnmente los siguientes roles:
Los científicos de datos se enfocan en diseñar y ejecutar experimentos para identificar y explotar patrones en los datos, utilizando herramientas como resúmenes básicos y agregación, estadísticas aplicadas y machine learning.
Los ingenieros de datos hacen que los datos, ya sean estructurados o no estructurados, en reposo o en movimiento, estén disponibles a escala y también abordan las preocupaciones de catalogación, gobierno y control de acceso.
Los analistas comerciales utilizan el procesamiento de consultas en conjuntos de datos estructurados y federados para comprender las características de un problema comercial.
Los desarrolladores de aplicaciones construyen sistemas de producción mediante el desarrollo de servicios sólidos y maduros basados en experimentos de científicos de datos, la integración con servicios de datos mantenidos por ingenieros de datos y el desarrollo de componentes de aplicaciones convencionales e integraciones con middleware empresarial.
Los ingenieros de machine learning tienen responsabilidades que abarcan múltiples roles, pero con un enfoque particular en el desarrollo, mantenimiento y optimización de la infraestructura de producción.
Pensar en quién está involucrado actualmente en sus equipos de datos, y quién le gustaría involucrar en el futuro, es un aspecto importante de la evaluación de las herramientas, los sistemas y las soluciones de MLOps. Esta evaluación le dice qué es importante para su equipo y quién es la audiencia para una solución dada.
Evalúe el Panorama y Diseñe una Solución para su Equipo
Después de considerar los problemas que intenta resolver y la composición de su equipo de datos, está preparado para evaluar y comprender el panorama de MLOps en términos de la solución que usted y su organización necesitan. Su objetivo es respaldar sus propias iniciativas de machine learning, en lugar de tratar de dar sentido al panorama de MLOps en función de lo que dicen los proveedores y las personas influyentes sobre MLOps.
Un Enfoque Centrado en el Flujo de Trabajo
Debido a que el ecosistema de MLOps está evolucionando rápidamente, muchas categorías de productos no se excluyen mutuamente y tienen límites borrosos. Esto significa que no necesariamente desea pensar en una solución MLOps como una lista de verificación de características o una combinación de productos complementarios que encajan como bloques de construcción. Ese enfoque lo comprometerá con un punto de vista particular de un paisaje cambiante.
En cambio, piense en cómo las personas trabajan juntas para construir sistemas de machine learning y cómo los diferentes tipos de herramientas y sistemas pueden respaldarlos.
La Figura 1 muestra un flujo de trabajo de descubrimiento de machine learning característico. Este flujo de trabajo presenta siete procesos humanos, cada uno de los cuales informa al siguiente. Se anotan las personas involucradas en cada etapa: las personas de científicos de datos y analistas comerciales generalmente no se preocupan por los detalles de la infraestructura de computación, mientras que los ingenieros y desarrolladores de aplicaciones interactúan con la infraestructura directamente como parte de su trabajo.
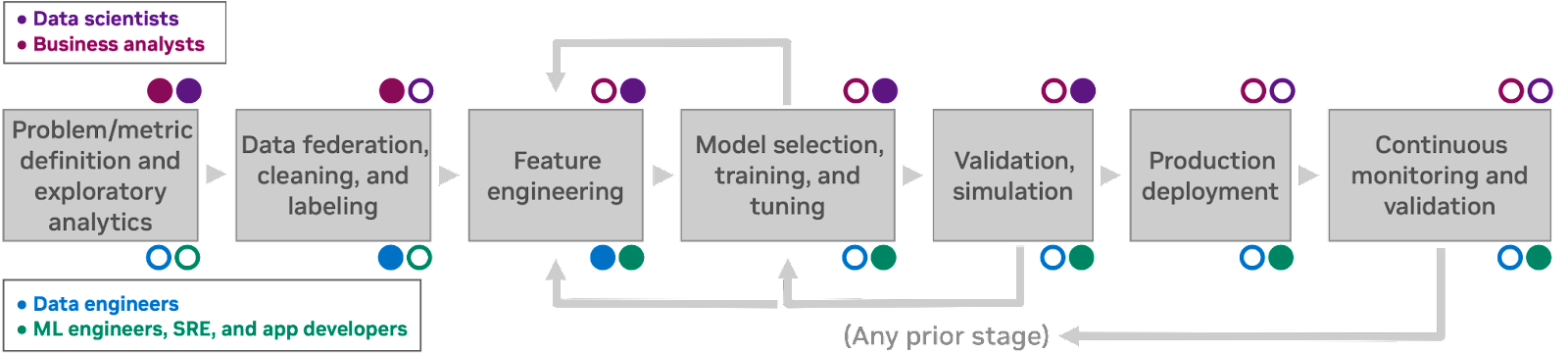
Debido a que los humanos siempre tienen información incompleta (y, a menudo, cometen errores), es posible volver a una fase anterior del flujo de trabajo en cualquier momento y revisar decisiones anteriores a la luz de nuevos conocimientos. La forma en que su organización habla sobre los flujos de trabajo de ML puede implicar términos ligeramente diferentes o una cantidad diferente de etapas, pero debería ser posible seguirlos, en cualquier caso
Apoyando a Su Equipo en Todo el Flujo de Trabajo de ML
¿Cómo pueden las herramientas de MLOps respaldar el flujo de trabajo de ML? La Figura 2 muestra varias categorías de productos superpuestas y cómo admiten aspectos del flujo de trabajo de ML. Las personas y las categorías de oferta que son indiferentes o están aisladas de la infraestructura de computación subyacente se representan sobre el flujo de trabajo, mientras que las personas y los productos que dependen de la interacción directa con la infraestructura informática subyacente se representan debajo del flujo de trabajo.
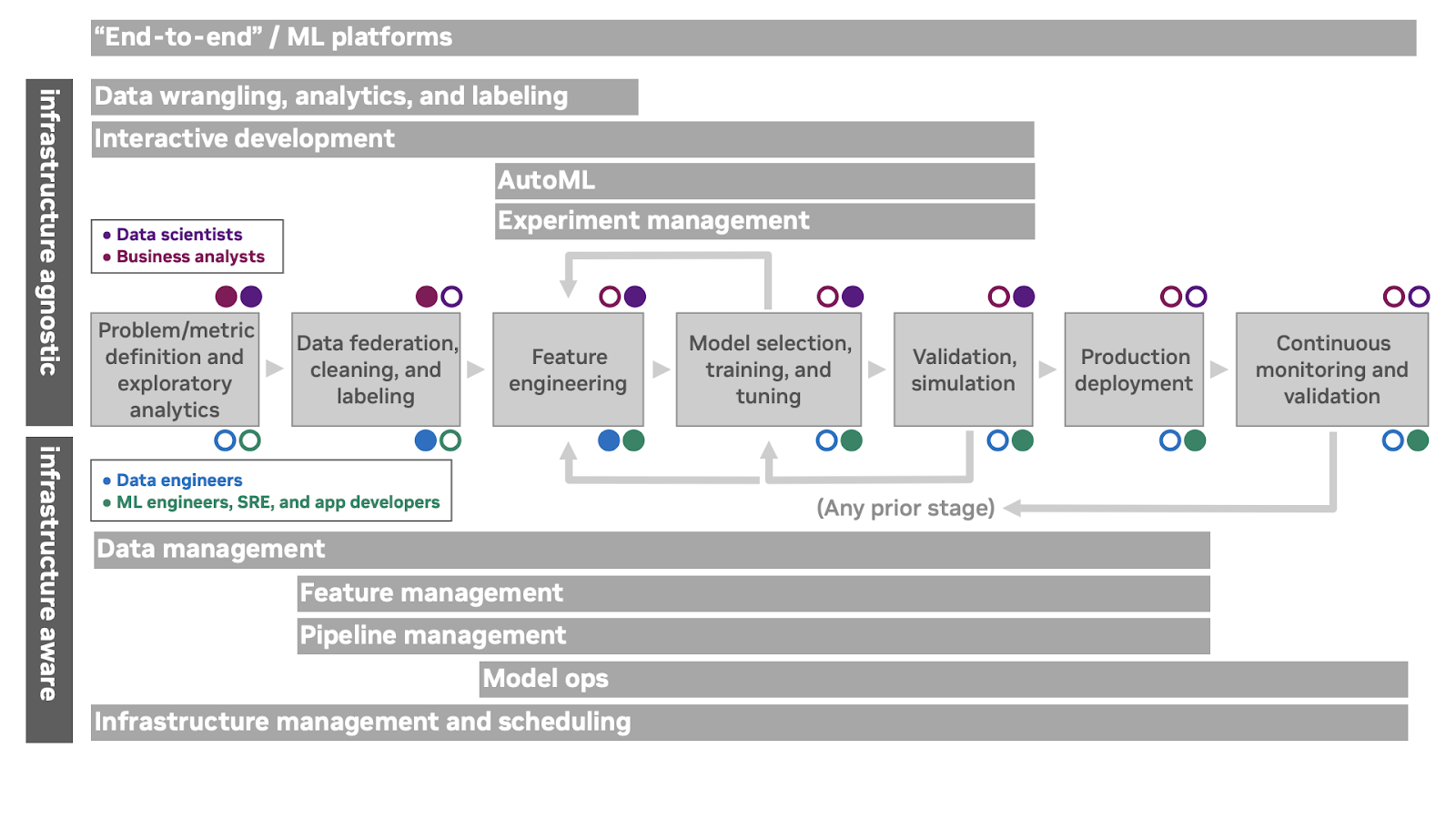
La categoría superior en la Figura 2, de extremo a extremo, incluye ofertas de plataforma ML que incorporan un plano de control y soporte para varias fases del ciclo de vida. Es importante tener en cuenta que el término «extremo a extremo» no es un juicio de valor o una declaración de integridad. La membresía en esta categoría simplemente indica que una oferta en particular cubre una amplia porción del ciclo de vida y está diseñada para ser operada por sí misma.
La segunda categoría en la Figura 2 combina ofertas de disputa de datos, que incluyen exploración de datos, visualización y capacidades de federación de alto nivel, ofertas convencionales de análisis e inteligencia de negocios y ofertas de etiquetado para datos no estructurados. Los tipos de problemas que está resolviendo indicarán cuáles de estos tipos de ofertas son más relevantes para sus flujos de trabajo.
Las ofertas de desarrollo interactivo proporcionan un plano de control para brindar a los profesionales de la ciencia de datos y el machine learning acceso a los recursos de computación bajo demanda. Estos a menudo brindan una instalación para administrar entornos de desarrollo y se integran con sistemas de control de versiones externos, IDE de escritorio y otras herramientas de desarrollo independientes. Proporcionan una vista unificada de la infraestructura de nube pública y local, y facilitan que los equipos colaboren en proyectos.
Las ofertas de gestión de experimentos proporcionan una forma de realizar un seguimiento de los resultados de varias configuraciones de modelos (junto con el código y los datos versionados) para comprender el rendimiento del modelado a lo largo del tiempo. Los sistemas AutoML se basan en la gestión de experimentos para buscar automáticamente el espacio de posibles técnicas e hiperparámetros para una técnica determinada a fin de producir un modelo entrenado con una participación mínima del profesional.
Las ofertas de administración de datos admiten almacenamiento de datos, versiones de datos, ingesta y control de acceso. Desde la perspectiva de los sistemas ML, el control de versiones de los datos suele ser la pieza fundamental: el trabajo reproducible depende de poder identificar los datos en los que se entrenó un modelo.
Las ofertas de gestión de funciones incorporan tiendas de funciones para realizar un seguimiento de las funciones derivadas, agregadas o costosas de calcular para el desarrollo y la producción. Estos también pueden respaldar la colaboración en torno a los enfoques de ingeniería de funciones en algunas organizaciones.
Las ofertas de administración de pipelines brindan una manera de orquestar y monitorear los múltiples componentes de software involucrados en los flujos de trabajo de exploración y producción, por ejemplo, preprocesamiento, capacitación e inferencia.
Las ofertas de ModelOps abordan las preocupaciones de publicar modelos como servicios implementables, implementar estos servicios de predicción, administrar y enrutar a conjuntos de servicios de predicción, explicar las predicciones después del hecho, rastrear los comentarios de las predicciones y monitorear las entradas y salidas del modelo para la deriva del concepto.
La gestión de la infraestructura proporciona una interfaz para programar trabajos y servicios de computación en hardware subyacente o recursos en la nube. Las ofertas en este espacio suelen ser interesantes desde la perspectiva de los sistemas de machine learning si brindan soporte especial para hardware acelerado, programación grupal y otras preocupaciones específicas de ML.