
Es importante tener en cuenta el rendimiento de la inferencia al implementar, integrar o comparar cualquier framework de grande modelo de lenguaje (LLM). Debe asegurarse de ajustar el framework elegido y sus características para que cumpla con las métricas de rendimiento que son importantes para su aplicación.
TensorRT-LLM, el motor de inferencia de IA de código abierto de NVIDIA, le permite implementar modelos con sus herramientas nativas de evaluación comparativa y servicio, y tiene una amplia gama de funciones con las que puede ajustarse. En esta publicación, proporcionaremos una guía práctica sobre cómo ajustar un modelo con trtllm-bench y luego implementarlo usando trtllm-serve.
Cómo Comparar con trtllm-bench
trtllm-bench es la utilidad basada en Python de TensorRT-LLM para realizar evaluaciones comparativas directas de modelos sin la sobrecarga de una implementación de inferencia completa. Simplifica la generación rápida de información sobre el rendimiento del modelo. trtllm-bench configura internamente el motor con configuraciones óptimas que generalmente proporcionan un buen rendimiento.
Configura Tu Entorno de GPU
La evaluación comparativa comienza con un entorno de GPU configurado correctamente. Para restaurar las GPU a su configuración predeterminada, ejecuta:

Para consultar el uso máximo de tu GPU:
![]()
Si quieres establecer un límite de potencia específico (o establecer un máximo), ejecuta:
![]()
Para obtener más detalles, consulte la documentación de trtllm-benchhttps://github.com/NVIDIA/TensorRT-LLM/blob/main/docs/source/performance/perf-benchmarking.md.
Preparación de un Conjunto de Datos
Puede preparar un conjunto de datos sintético utilizando prepare_dataset o crear un conjunto de datos propio utilizando el formato especificado en nuestra documentación. Para un conjunto de datos personalizado, puede dar formato a un archivo JSON Lines (jsonl) con una carga útil configurada en cada línea. A continuación se muestra un ejemplo de una sola entrada de conjunto de datos:
![]()
Para los fines de esta publicación, proporcionamos resultados de ejemplo basados en un conjunto de datos sintéticos con un ISL/OSL de 128/128.
Ejecutar Pruebas Comparativas
Para ejecutar pruebas comparativas mediante trtllm-bench, puede utilizar el subcomando trtllm-bench throughput. Al ejecutar un punto de referencia mediante el flujo de PyTorch, simplemente debe ejecutar el siguiente comando en un entorno con TensorRT-LLM instalado:

El comando de rendimiento extraerá automáticamente el punto de control de HuggingFace (si no se almacena en caché) y arrancará TRT-LLM con el flujo de PyTorch. Los resultados se guardarán en results.json e imprimirán en el terminal de la siguiente manera una vez que se complete la ejecución:
Nota: Esto es solo una muestra de la salida y no representa afirmaciones de rendimiento.
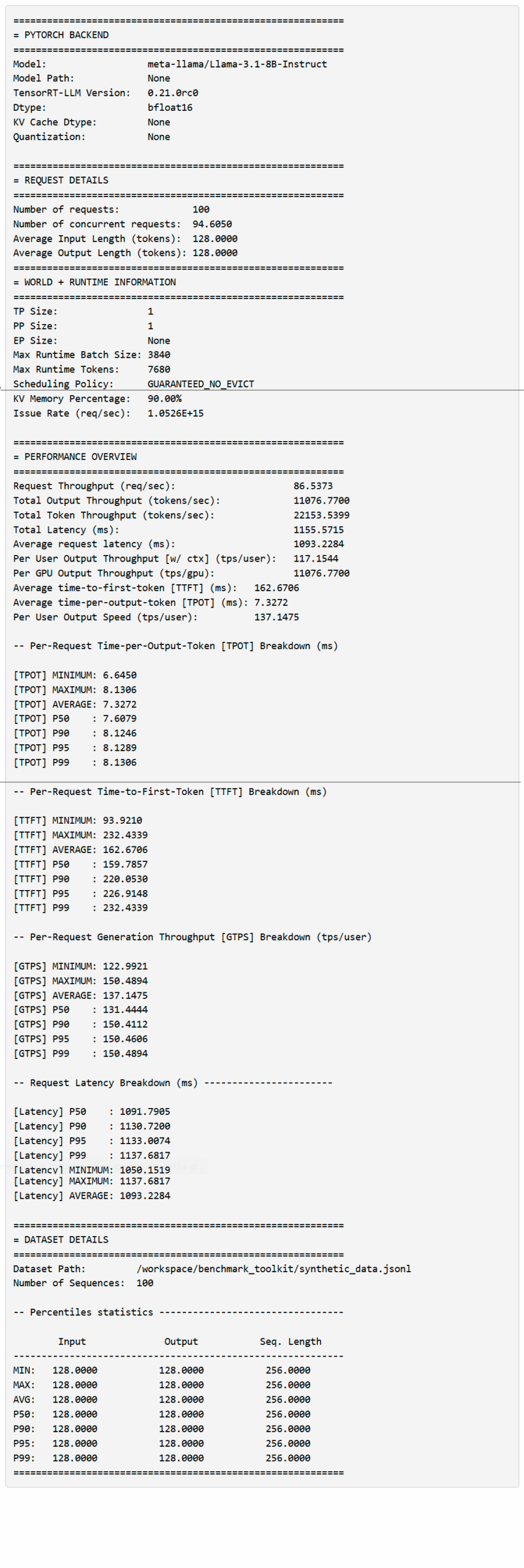
Analizar los Resultados de Rendimiento
Al ejecutar el comando anterior, las estadísticas principales se muestran en la sección PERFORMANCE OVERVIEW. Antes de entrar en detalles, aquí hay una terminología útil:
- Output en el contexto de la descripción general significa todos los tokens de salida https://blogs.nvidia.com/blog/ai-tokens-explained/ generados (incluidos los tokens de contexto)
- Total Token significa la longitud total de la secuencia generada (ISL+OSL)
- Per user, TTFT y TPOT toman la perspectiva de que cada solicitud es un «usuario»; estas estadísticas se utilizan para formar una distribución.
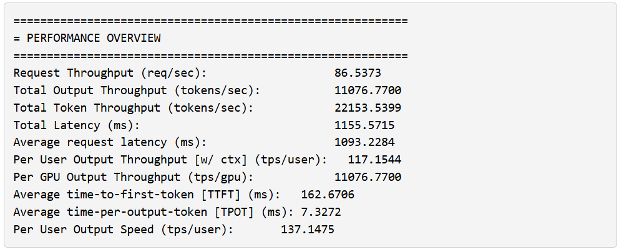
También observará que trtllm-bench informa del número máximo de tokens y el tamaño del lote.
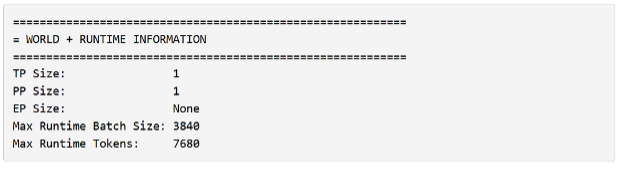
Estos tienen un significado particular en el contexto de TensorRT-LLM:
- El número máximo de tokens hace referencia al número máximo de tokens que el propio motor puede controlar en una iteración por lotes. Este límite incluye la suma de todos los tokens de entrada para todas las solicitudes de contexto y un solo token para la suma de todas las solicitudes de generación en el lote.
- El tamaño máximo del lote es el número máximo de solicitudes permitidas en un lote. Supongamos que la iteración contiene una solicitud con contexto de longitud 128, cuatro solicitudes de generación (total de 132 tokens) y ha establecido el máximo de tokens en 512 con un tamaño máximo de lote de cinco solicitudes. En este caso, su motor limitará el tamaño del lote aunque no haya satisfecho los tokens máximos.
Al analizar los resultados, es útil conocer sus prioridades. Algunas preguntas comunes:
- ¿Apunta a un alto rendimiento de tokens por usuario?
- ¿Está procesando grandes cantidades de texto y necesita el mayor rendimiento posible?
- ¿Quieres que el primer token regrese rápidamente?
El ajuste que establezca depende en gran medida del escenario que desee priorizar. Para esta publicación, centrémonos en optimizar la experiencia por usuario. Queremos priorizar la métrica Per User Output Speed o la velocidad a la que se devuelven los tokens al usuario después de que se haya completado la fase de contexto. Con trtllm-bench, puede especificar el número máximo de solicitudes pendientes mediante –concurrency, lo que le permite reducir el número de usuarios que puede admitir el sistema.
Esta opción es útil para producir varias curvas diferentes, que son cruciales al buscar objetivos de latencia y rendimiento. Aquí hay un conjunto de curvas basadas en Llama-3.1 8B FP8 de NVIDIA y Llama-3.1 8B FP16 de Meta generadas para un escenario 128/128 ISL/OSL. Digamos que queremos utilizar el sistema tanto como sea posible, pero aún queremos que un usuario experimente alrededor de 50 tokens/segundo de velocidad de salida (aproximadamente 20 ms entre tokens). Para evaluar la compensación entre el rendimiento de la GPU y la experiencia del usuario, puede trazar el rendimiento de salida por GPU frente a la velocidad de salida por usuario.
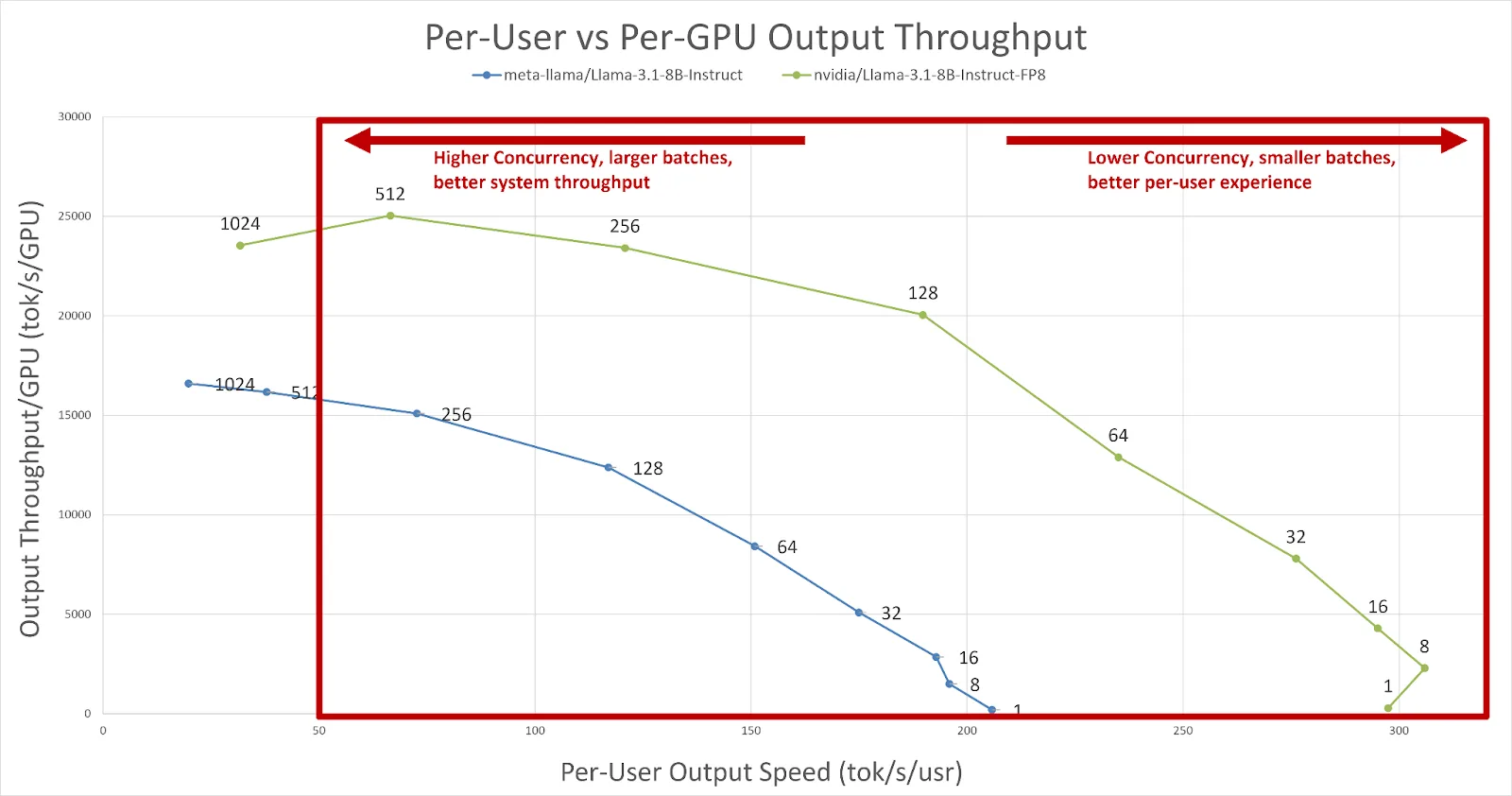
Figura 1. Una comparación de la velocidad de salida por usuario y el rendimiento de salida por gpu. Según nuestros criterios, podemos ver que el rendimiento por GPU mejora a medida que aumenta la simultaneidad (mejor utilización del sistema); sin embargo, a medida que el sistema se vuelve menos saturado, la velocidad de salida por usuario aumenta (mejor experiencia).
En la Figura 1, podemos ver que Llama-3.1 8B FP16 solo puede manejar alrededor de 256 usuarios simultáneos con aproximadamente 72 tokens/seg/usuario antes de violar nuestra restricción de 50 tokens/seg/usuario. Sin embargo, si observamos el punto de control optimizado Llama-3.1 8B FP8, vemos que TensorRT-LLM puede manejar 512 usuarios simultáneos a aproximadamente 66 tokens/seg/usuario. Podemos concluir que el modelo cuantificado puede servir a más usuarios dentro del mismo presupuesto simplemente barriendo ambos modelos con trtllm-bench.
Con estos datos, puede considerar lo siguiente:
- Si desea forzar el motor a 512 entradas, puede establecer el tamaño máximo del lote en 512; sin embargo, esto corre el riesgo de aumentar el tiempo hasta el primer token (TTFT) si el tráfico a esta instancia supera 512 (cualquier solicitud más allá de 512 se pone en cola).
- Puede evaluar escenarios y modelos de calidad de servicio con otros conjuntos de datos mediante trtllm-bench y trazar una variedad de métricas. La herramienta le permite realizar evaluaciones de valor basadas en sus prioridades ajustando la línea de comandos de una manera fácil de usar.
Nota: En este escenario, solo exploramos un único modelo de GPU: si tienes un modelo que requiere varias GPU, puedes configurar trtllm-bench mediante las opciones –tp, –pp y –ep para encontrar la mejor configuración de partición/datos paralelos. Además, si es un desarrollador y necesita funciones avanzadas, puede usar el argumento –extra_llm_api_options.
Cómo Servir un Grande Modelo de Lenguaje con trtllm-serve
TensorRT-LLM ofrece la capacidad de poner en marcha fácilmente un punto final compatible con OpenAI mediante el comando trtllm-serve. Puede usar la afinación de trtllm-bench anterior para hacer girar un servidor sintonizado. A diferencia del punto de referencia, trtllm-serve no hace suposiciones sobre la configuración, aparte de la configuración general. Para ajustar el servidor en función de nuestros resultados de rendimiento máximo anteriores, deberá proporcionar el siguiente comando en función de la salida anterior:
trtllm-serve serve nvidia/Llama-3.1-8B-Instruct-FP8 –backend pytorch –max_num_tokens 7680 –max_batch_size 3840 –tp_size 1 –extra_llm_api_options llm_api_options.yml
El –extra_llm_api_options proporciona un mecanismo para cambiar directamente la configuración en el nivel de API de LLM. Para hacer coincidir la configuración del punto de referencia, necesitará lo siguiente en su llm_api_options.yml:

Una vez configurado y ejecutado, debería ver una actualización de estado que indica que el servidor está ejecutando:

Con el servidor en ejecución, ahora puede comparar el modelo usando GenAI-Perf, o puede usar nuestra versión portada de benchmark_serving.py. Estos pueden ayudarle a comprobar el rendimiento de la configuración del servidor ajustado. En futuras versiones, planeamos aumentar trtllm-bench para poder poner en marcha un servidor optimizado para la evaluación comparativa.
Introducción a la Evaluación Comparativa y al Ajuste del Rendimiento de los LLM
Con trtllm-bench, TensorRT-LLM proporciona una manera fácil de comparar una variedad de configuraciones, ajustes, simultaneidad y características. La configuración de trtllm-bench se puede traducir directamente a la solución de servicio nativa de TensorRT-LLM, trtllm-serve. Le permite portar sin problemas su ajuste de rendimiento a una implementación compatible con OpenAI.
Para obtener información más detallada sobre el rendimiento, el ajuste específico del modelo y el ajuste o la evaluación comparativa de TensorRT-LLM, consulta los siguientes recursos:
- Para obtener una comprensión más detallada de las opciones de rendimiento disponibles, consulte la Guía de Ajuste del Rendimiento.
- Para obtener documentación de trtllm-bench, consulte nuestra página de Evaluación Comparativa del Rendimiento.
- Para ver cómo generar perfiles de TensorRT-LLM, el Análisis de Rendimiento cubre el uso de Nsight System para generar perfiles de ejecución de modelos.
- Para profundizar en el ajuste del rendimiento de DeepSeek-R1, consulta la Guía de ajuste del rendimiento de TensorRT-LLM para DeepSeek-R1.
Consulte los siguientes recursos:
- Para obtener más información sobre cómo la arquitectura de la plataforma puede afectar el TCO más allá de los FLOPS, puede leer la publicación del blog «NVIDIA DGX Cloud Introduces Ready-To-Use Templates to Benchmark AI Platform Performance«. Consulte también la colección de recetas de evaluación comparativa de rendimiento (plantillas listas para usar) disponibles para descargar en NGC aquí.
- Aprenda a reducir el costo por token y maximizar los modelos de IA con la Guía del Líder de TI para la Inferencia y el Rendimiento de la IA.