La generación de ideas, no el hardware o el software, debe ser el obstáculo para el avance de la IA, dijo Bryan Catanzaro, vicepresidente de investigación de deep learning aplicado de NVIDIA, esta semana en la Cumbre de Hardware de IA.
“Queremos que los inventores, los investigadores y los ingenieros que están ideando la IA del futuro estén limitados solo por sus propios pensamientos”, dijo Catanzaro a la audiencia.
Catanzaro lidera un equipo de investigadores que trabajan para aplicar el poder del deep learning a todos los aspectos, desde los videojuegos hasta el diseño de chips. En el evento anual celebrado en Silicon Valley, describió el trabajo que NVIDIA está haciendo para permitir los avances en IA, con un enfoque en los modelo grandes de idiomas.
CUDA es para los Soñadores
Entrenar e implementar grandes redes neuronales es un problema computacional difícil, por lo que el hardware que es increíblemente rápido y altamente eficiente es una necesidad, según Catanzaro.
Pero, explicó, el software que acompaña a ese hardware podría ser aún más importante para desbloquear nuevos avances en IA.
“El núcleo del trabajo que hacemos implica optimizar el hardware y el software juntos, desde chips hasta sistemas, software, frameworks, bibliotecas, compiladores, algoritmos y aplicaciones”, dijo. “Optimizamos todas estas cosas para dar capacidades de transformación a científicos, investigadores e ingenieros de todo el mundo”.
Este enfoque integral logra un rendimiento que encabeza los gráficos en las evaluaciones estándar de la industria, como MLPerf. También garantiza que los desarrolladores no estén limitados por la plataforma, ya que su objetivo es avanzar en la IA.
“CUDA es para los soñadores, CUDA es para las personas que están pensando nuevos pensamientos”, dijo Catanzaro. “¿Cómo piensan esos pensamientos y los prueban de manera eficiente? Necesitan algo general y flexible, y es por eso que construimos lo que construimos”.
Los Grandes Modelos de Idiomas Están Cambiando el Mundo
Una de las áreas más emocionantes de la IA es el modelado de idiomas, que permite aplicaciones innovadoras en la comprensión de idiomas naturales y la IA conversacional.
La complejidad de los modelos grandes de idiomas está creciendo a un ritmo increíble, con recuentos de parámetros que se duplican cada dos meses.
Un ejemplo bien conocido de un modelo de idioma grande y poderoso es GPT-3, desarrollado por OpenAI. Con 175,000 millones de parámetros, requirió 314 zettaflops (1021 operaciones de coma flotante) para entrenarse.
“Es una cantidad asombrosa de computación”, dijo Catanzaro. “Y eso significa que el modelado de idiomas ahora está siendo limitado por la economía”.
Las estimaciones sugieren que el entrenamiento de GPT-3 costaría alrededor de 12 millones de dólares y, observó Catanzaro, el rápido crecimiento en la complejidad del modelo significa que, a pesar del trabajo incansable de NVIDIA para avanzar en el rendimiento y la eficiencia de su hardware y software, el costo de entrenar estos modelos crecerá.
Y, según Catanzaro, esta tendencia sugiere que podría no pasar mucho tiempo antes de que un solo modelo requiera más de mil millones de dólares en tiempo de computadora para entrenar.
“¿Cómo sería construir un modelo que tomara mil millones de dólares para entrenar un solo modelo? Bueno, tendría que reinventar toda una empresa, y tendrías que ser capaz de usarlo en muchos contextos diferentes”, explicó Catanzaro.
Catanzaro espera que estos modelos desbloqueen una increíble cantidad de valor e inspiren la innovación continua. Durante su charla, Catanzaro mostró un ejemplo de las sorprendentes capacidades de los grandes modelos de idiomas para resolver nuevas tareas sin estar explícitamente entrenado para ello.
Después de poner solo algunos ejemplos en un modelo grande de idioma (cuatro oraciones, con dos escritas en inglés y sus correspondientes traducciones al español), ingresó una oración en inglés, que el modelo luego tradujo al español correctamente.
El modelo fue capaz de hacer esto a pesar de que nunca fue entrenado para hacer traducción. En cambio, fue entrenado para predecir la siguiente palabra que debería seguir a una secuencia dada de texto, utilizando, como describió Catanzaro, “una enorme cantidad de datos de Internet”.
Para realizar esa tarea tan genérica, el modelo necesitaba llegar a representaciones de alto nivel de conceptos, como la existencia de idiomas en general, vocabularios y gramática en inglés y español, y el concepto de una tarea de traducción, para comprender la consulta y responder adecuadamente.
“Estos modelos de idiomas son los primeros pasos hacia la inteligencia artificial generalizada con pocas etapas de aprendizaje, y eso es enormemente valioso y muy emocionante”, explicó Catanzaro.
Un Enfoque de Pila Completa para el Modelado de Idiomas
Catanzaro luego pasó a describir NVIDIA Megatron, un framework creado por NVIDIA utilizando PyTorch “para entrenar eficientemente los modelos de idiomas basados en transformadores más grandes del mundo”.
Una característica clave de NVIDIA Megatron, que Catanzaro señala que ya ha sido utilizada por varias compañías y organizaciones para entrenar grandes modelos basados en transformadores, es el paralelismo de modelos.
Megatron admite tanto el paralelismo entre capas (proceso), que permite procesar diferentes capas de un modelo en diferentes dispositivos, como el paralelismo intracapa (tensor), que permite que una sola capa sea procesada por múltiples dispositivos diferentes.
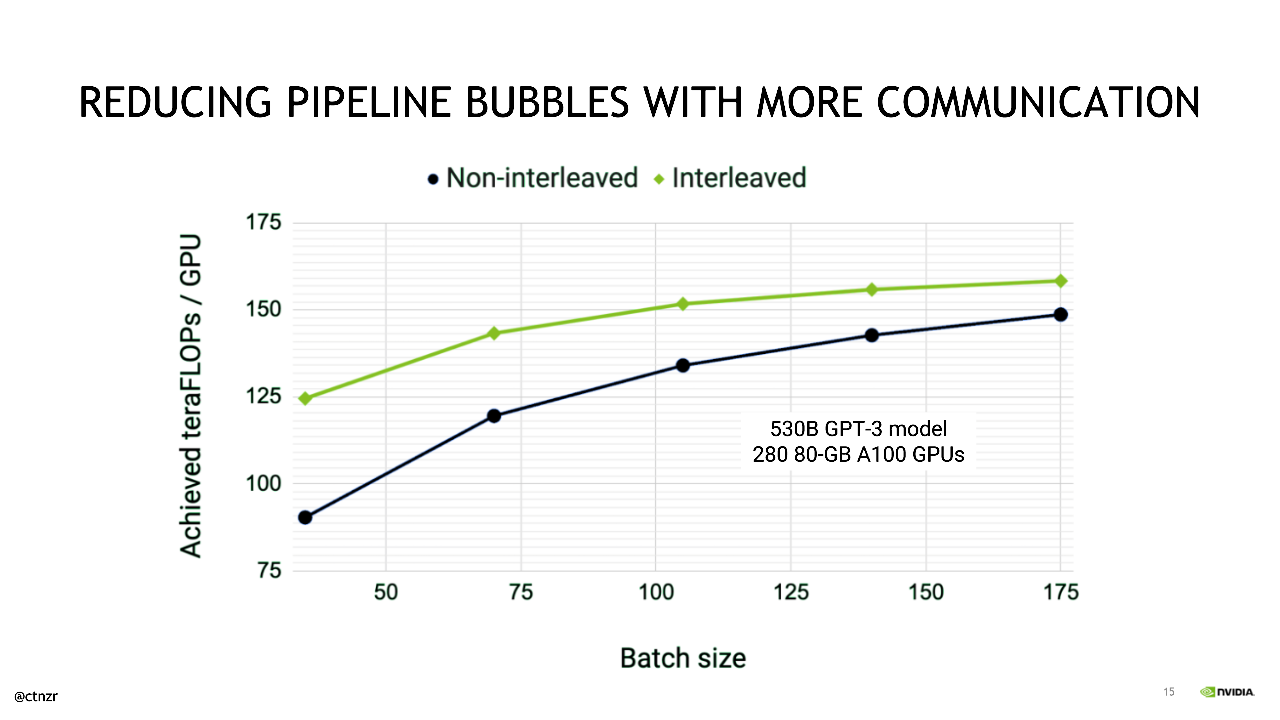
Catanzaro describió además algunas de las optimizaciones que NVIDIA aplica para maximizar la eficiencia del paralelismo del proceso y minimizar las llamadas “burbujas de procesos”, durante las cuales una GPU no está realizando un trabajo útil.
Un lote se divide en microlotes, cuyo ejecución se proceso. Esto aumenta la utilización de los recursos de la GPU en un sistema durante el entrenamiento. Con más optimizaciones, las burbujas de procesos se pueden reducir aún más.
Catanzaro describió una optimización, recientemente publicada, que implica “repetir cada etapa (de proceso) en múltiples GPU para que podamos reducir aún más la cantidad de sobrecarga de burbujas de proceso en este cronograma”.
Aunque esta optimización implica una carga adicional en el tejido de comunicación dentro del sistema, Catanzaro demostró que, al aprovechar el conjunto completo de tecnologías de interconexión de alto ancho de banda y baja latencia de NVIDIA, esta optimización puede ofrecer aceleraciones considerables cuando se entrenan modelos de estilo GPT-3.
Luego, Catanzaro destacó la impresionante escala de rendimiento de Megatron en NVIDIA DGX SuperPOD, logrando 502 petaflops sostenidos en 3,072 GPU, lo que representa un asombroso 52 por ciento del pico de Tensor Core a escala.
«Esto representa un logro de todos NVIDIA y nuestros socios en la industria: para poder ofrecer ese nivel de rendimiento de extremo a extremo se requiere optimizar toda la pila de computación, desde los algoritmos hasta las interconexiones, desde los frameworks hasta los procesadores», dijo Catanzaro.