
Los modelos de IA más grandes pueden requerir meses para entrenarse en las plataformas de computación actuales. Eso es demasiado lento para las empresas.
La inteligencia artificial, la computación de alto rendimiento y el análisis de datos están creciendo en complejidad con algunos modelos, como los de lenguaje grande, que alcanzan billones de parámetros.
La arquitectura NVIDIA Hopper está construida desde cero para acelerar estas cargas de trabajo de IA de próxima generación con una potencia de computación masiva y una memoria rápida para manejar redes y conjuntos de datos en crecimiento.
Transformer Engine, parte de la nueva arquitectura Hopper, acelerará significativamente el rendimiento y las capacidades de la IA y ayudará a entrenar modelos grandes en días u horas.
Entrenamiento de Modelos de IA con Transformer Engine
Los modelos transformers son la columna vertebral de los modelos de lenguaje que se utilizan ampliamente en la actualidad, como BERT y GPT-3. Inicialmente desarrollado para casos de uso de procesamiento de lenguaje natural, su versatilidad se aplica cada vez más a la visión artificial, el descubrimiento de fármacos y más.
Sin embargo, el tamaño del modelo continúa aumentando exponencialmente y ahora alcanza billones de parámetros. Esto está causando que los tiempos de capacitación se extiendan a meses debido a la gran cantidad de computación, lo cual no es práctico para las necesidades comerciales.
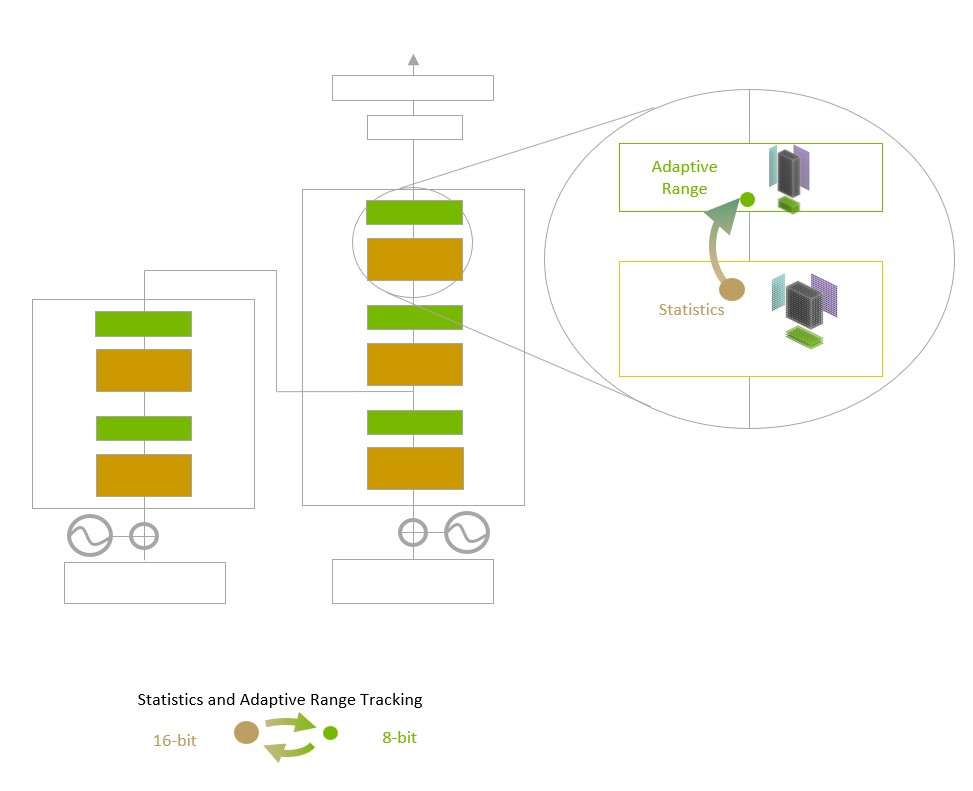
Transformer Engine utiliza una precisión de punto flotante de 16 bits y un formato de datos de punto flotante de 8 bits recientemente agregado combinado con algoritmos de software avanzados que acelerarán aún más el rendimiento y las capacidades de la IA.
El entrenamiento de IA se basa en números de coma flotante, que tienen componentes fraccionarios, como 3,14. Introducido con la arquitectura NVIDIA Ampere, el formato de punto flotante TensorFloat32 (TF32) es ahora el formato predeterminado de 32 bits en los frameworks TensorFlow y PyTorch.
La mayoría de las matemáticas de coma flotante de IA se realizan con precisión «media» de 16 bits (FP16), precisión «simple» de 32 bits (FP32) y, para operaciones especializadas, precisión «doble» de 64 bits (FP64). Al reducir las matemáticas a solo ocho bits, Transformer Engine hace posible entrenar redes más grandes más rápido.
Cuando se combina con otras características nuevas en la arquitectura Hopper, como el sistema NVLink Switch, que proporciona una interconexión directa de alta velocidad entre nodos, los clústeres de servidores acelerados por H100 podrán entrenar redes enormes que eran casi imposibles de entrenar a la velocidad necesaria. para empresas.
Profundizando en el Transformer Engine
Transformer Engine utiliza el software y la tecnología personalizada NVIDIA Hopper Tensor Core diseñada para acelerar el entrenamiento de los modelos creados a partir del componente básico del modelo de IA predominante, el transformer. Estos Tensor Cores pueden aplicar formatos mixtos FP8 y FP16 para acelerar significativamente los cálculos de IA para transformers. Las operaciones de Tensor Core en FP8 tienen el doble de rendimiento que las operaciones de 16 bits.
El desafío para los modelos es administrar de manera inteligente la precisión para mantener la precisión y obtener el rendimiento de formatos numéricos más pequeños y rápidos. Transformer Engine permite esto con heurísticas personalizadas y ajustadas por NVIDIA que eligen dinámicamente entre los cálculos FP8 y FP16 y manejan automáticamente la refundición y el escalado entre estas precisiones en cada capa.
La arquitectura NVIDIA Hopper también mejora los Tensor Cores de cuarta generación al triplicar las operaciones de punto flotante por segundo en comparación con las precisiones TF32, FP64, FP16 e INT8 de la generación anterior. Combinados con Transformer Engine y NVLink de cuarta generación, Hopper Tensor Cores permiten una aceleración de orden de magnitud para las cargas de trabajo de HPC e IA.
Acelerando el Transformer Engine
Gran parte del trabajo de vanguardia en IA gira en torno a grandes modelos de lenguaje como Megatron 530B. El siguiente gráfico muestra el crecimiento del tamaño del modelo en los últimos años, una tendencia que se espera que continúe. Muchos investigadores ya están trabajando en más de un billón de modelos de parámetros para la comprensión del lenguaje natural y otras aplicaciones, lo que demuestra un apetito implacable por el poder de cómputo de la IA.
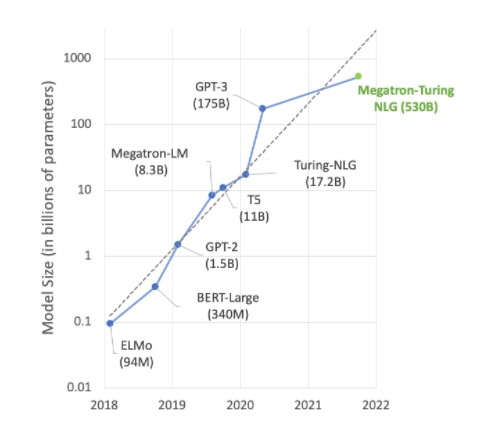
Satisfacer la demanda de estos modelos en crecimiento requiere una combinación de poder computacional y una tonelada de memoria de alta velocidad. La GPU NVIDIA H100 Tensor Core cumple en ambos frentes, con las aceleraciones posibles gracias a Transformer Engine para llevar el entrenamiento de IA al siguiente nivel.
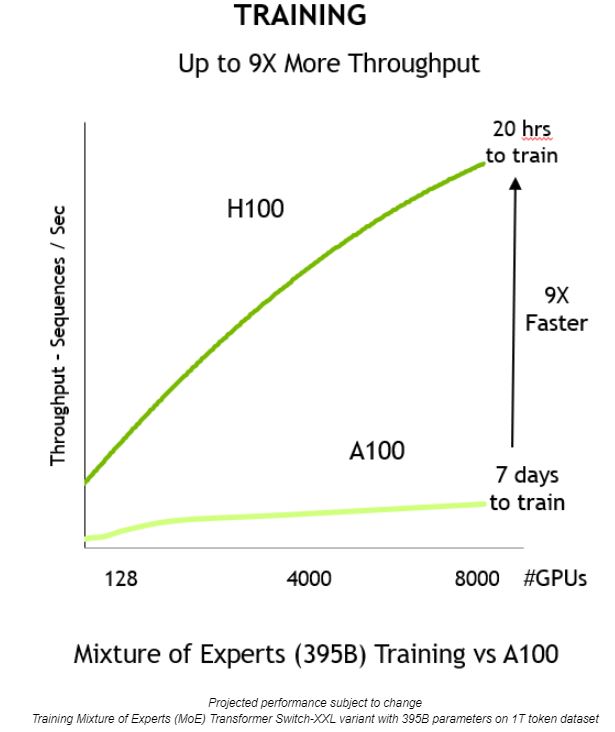
Cuando se combinan, estas innovaciones ofrecen un mayor rendimiento y una reducción de 9 veces en el tiempo de capacitación, de siete días a solo 20 horas:
Transformer Engine también se puede utilizar para la inferencia sin ninguna conversión de formato de datos. Anteriormente, INT8 era la precisión de referencia para un rendimiento de inferencia óptimo. Sin embargo, requiere que las redes entrenadas se conviertan a INT8 como parte del proceso de optimización, algo que el optimizador de inferencia NVIDIA TensorRT facilita.
El uso de modelos entrenados con FP8 permitirá a los desarrolladores omitir este paso de conversión por completo y realizar operaciones de inferencia con la misma precisión. Y al igual que las redes con formato INT8, las implementaciones que utilizan Transformer Engine pueden ejecutarse en un espacio de memoria mucho menor.
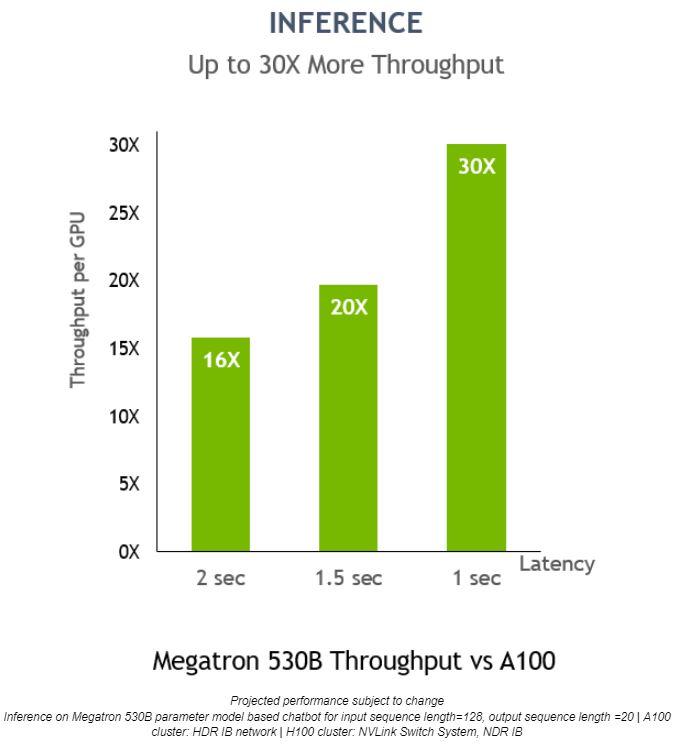
En Megatron 530B, el rendimiento de inferencia por GPU de NVIDIA H100 es hasta 30 veces mayor que el de NVIDIA A100, con una latencia de respuesta de 1 segundo, lo que la muestra como la plataforma óptima para implementaciones de IA:
Para obtener más información sobre la GPU NVIDIA H100 y la arquitectura Hopper, vea el discurso de apertura de GTC 2022 de Jensen Huang. Regístrese para GTC 2022 de forma gratuita para asistir a sesiones con NVIDIA y líderes de la industria.