
Nota del editor: Este post forma parte de la serie IA Decodificada, que desmitifica la IA haciendo la tecnología más accesible, y que muestra nuevo hardware, software, herramientas y aceleraciones para usuarios de PC RTX.
A medida que la IA generativa avanza y se generaliza en todos los sectores de la industria, crece la importancia de ejecutar aplicaciones de IA generativa en PCs y workstations locales. La inferencia local ofrece a los consumidores una latencia reducida, elimina su dependencia de la red y permite un mayor control sobre sus datos.
Las GPUs NVIDIA GeForce y NVIDIA RTX incorporan Nucleos Tensor, aceleradores de hardware dedicados a la IA que proporcionan la potencia necesaria para ejecutar IA generativa de forma local.
Ahora, Stable Video Diffusion está optimizado para el kit de desarrollo de software NVIDIA TensorRT, que proporciona la IA generativa de mayor rendimiento en los más de 100 millones de PCs y workstations Windows equipados con GPUs RTX.
Ahora, la extensión TensorRT para la popular WebUI Stable Diffusion de Automatic1111 añade soporte para ControlNets, herramientas que dan a los usuarios más control para refinar los resultados generativos añadiendo otras imágenes como guía.
La aceleración TensorRT puede ponerse a prueba en la nueva prueba de rendimiento UL Procyon AI Image Generation, que, según pruebas internas, reproduce con exactitud el rendimiento en el mundo real. En una GPU GeForce RTX 4080 SUPER, ha proporcionado un 50% más de velocidad que la implementación más rápida sin TensorRT.
IA Más Eficiente y Precisa
TensorRT permite a los desarrolladores acceder al hardware que proporciona experiencias de IA totalmente optimizadas. El rendimiento de la IA suele duplicarse en comparación con la ejecución de la aplicación en otros marcos.
También acelera los modelos de IA generativa más populares, como Stable Diffusion y SDXL. Stable Video Diffusion, el modelo de IA generativa de imagen a video de Stability AI, experimenta una aceleración del 40% con TensorRT.
El modelo optimizado Stable Video Diffusion 1.1 Image-to-Video puede descargarse en Hugging Face.
Además, la extensión TensorRT para Stable Diffusion WebUI aumenta el rendimiento hasta 2 veces, lo que agiliza significativamente los flujos de trabajo de Stable Diffusion.
Con la última actualización de la extensión, las optimizaciones de TensorRT se extienden a ControlNets, un conjunto de modelos de IA que ayudan a guiar la salida de un modelo de difusión añadiendo condiciones adicionales. Con TensorRT, los ControlNets son un 40% más rápidos.
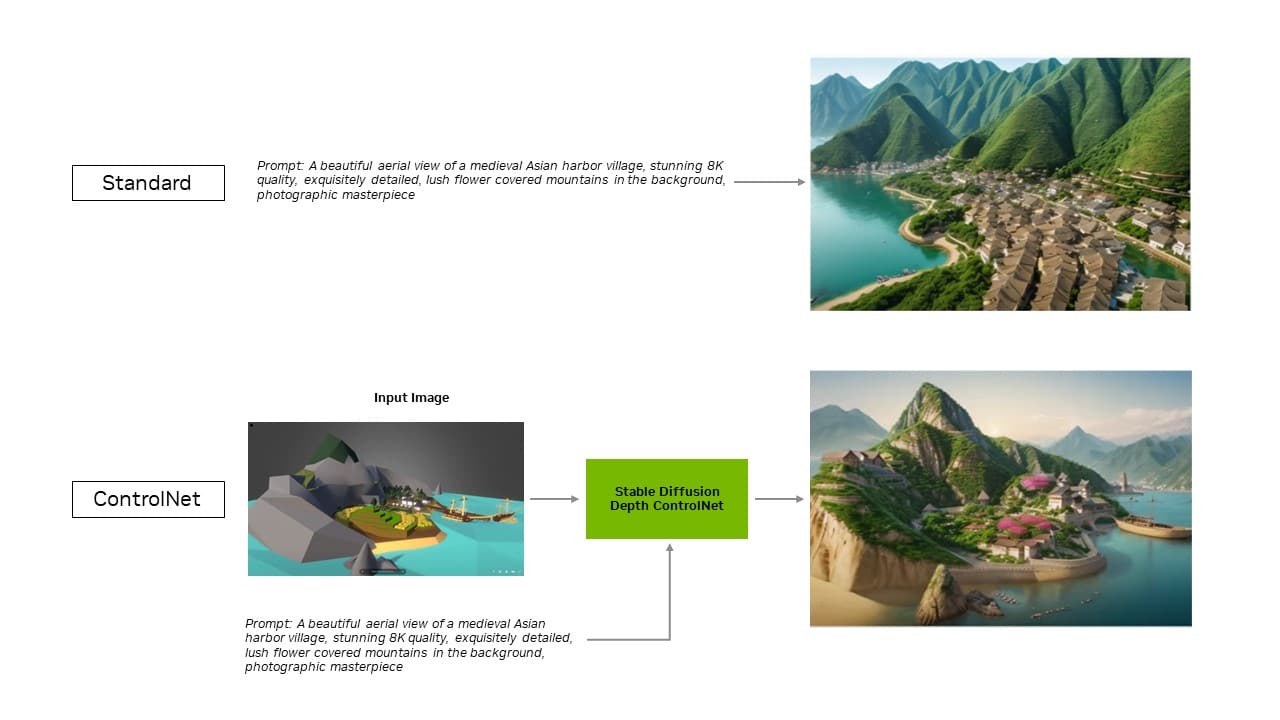
Los usuarios pueden guiar aspectos de la salida para que coincida con una imagen de entrada, lo que les da más control sobre la imagen final. También pueden utilizar varias ControlNets juntas para un control aún mayor. Una ControlNet puede ser un mapa de profundidad, un mapa de bordes, un mapa de normales o un modelo de detección de puntos clave, entre otros.
Descarga hoy mismo la extensión TensorRT para Stable Diffusion Web UI en GitHub.
Otras Apps Populares Aceleradas por TensorRT
Blackmagic Design adoptó la aceleración NVIDIA TensorRT en la actualización 18.6 de DaVinci Resolve. Sus herramientas de IA, como Magic Mask, Speed Warp y Super Scale, se ejecutan más de un 50% más rápido y hasta 2.3 veces más rápido en las GPUs RTX en comparación con los Mac.
Además, con la integración de TensorRT, Topaz Labs experimentó un aumento del rendimiento de hasta el 60% en sus aplicaciones de IA fotográfica y de IA de vídeo, como la eliminación de ruido en fotos, la nitidez, la superresolución fotográfica, la cámara lenta de video, la superresolución de video, la estabilización de video, etc., todas ellas ejecutadas en RTX.
La combinación de Núcleos Tensor con el software TensorRT aporta un rendimiento de IA generativa inigualable a las PCs y workstations locales. Y al ejecutarse localmente, se desbloquean varias ventajas:
- Rendimiento: Los usuarios experimentan una menor latencia, ya que ésta se vuelve independiente de la calidad de la red cuando todo el modelo se ejecuta localmente. Esto puede ser importante para casos de uso en tiempo real como los juegos o las videoconferencias. NVIDIA RTX ofrece los aceleradores de IA más rápidos, con más de 1300 billones de operaciones de IA por segundo (TOPS).
- Costo: Los usuarios no tienen que pagar por servicios en la nube, interfaces de programación de aplicaciones alojadas en la nube ni costos de infraestructura para la inferencia de grandes modelos lingüísticos.
- Siempre conectado: Los usuarios pueden acceder a las capacidades de LLM dondequiera que vayan, sin depender de una conectividad de red de gran ancho de banda.
- Privacidad de datos: Los datos privados y de propiedad pueden permanecer siempre en el dispositivo del usuario.
Optimizado para LLMs
Lo que TensorRT aporta al aprendizaje profundo, NVIDIA TensorRT-LLM lo aporta a los últimos LLMs..
TensorRT-LLM, una librería de código abierto que acelera y optimiza la inferencia LLM, incluye soporte inmediato para los modelos más populares de la comunidad, incluidos Phi-2, Llama2, Gemma, Mistral y Code Llama. Cualquier persona, desde desarrolladores y creadores hasta empleados de empresas y usuarios ocasionales, puede experimentar con modelos optimizados para TensorRT-LLM en los modelos de la NVIDIA AI Foundation. Además, con la demo tecnológica NVIDIA ChatRTX, los usuarios pueden ver el rendimiento de varios modelos ejecutándose localmente en un PC con Windows. ChatRTX se basa en TensorRT-LLM para optimizar el rendimiento en las GPUs RTX.
NVIDIA está colaborando con la comunidad de código abierto para desarrollar conectores nativos de TensorRT-LLM con los marcos de aplicaciones más populares, incluidos LlamaIndex y LangChain.
Estas innovaciones facilitan a los desarrolladores el uso de TensorRT-LLM con sus aplicaciones y experimentan el mejor rendimiento LLM con RTX.
Reciba actualizaciones semanales directamente en su bandeja de entrada suscribiéndose al boletín IA Decodificada.