
Nota del editor: Este post forma parte de nuestra serie IA Decodificada, cuyo objetivo es desmitificar la IA haciendo que la tecnología sea más accesible, a la vez que mostramos nuevo hardware, software, herramientas y aceleraciones para usuarios de PC y estaciones de trabajo RTX.
Si la IA está teniendo su momento iPhone, entonces los chatbots son una de sus primeras aplicaciones populares.
Son posibles gracias a grandes modelos lingüísticos, algoritmos de aprendizaje profundo preentrenados en conjuntos de datos masivos tan amplios como el propio Internet que pueden reconocer, resumir, traducir, predecir y generar texto y otras formas de contenido.
Pueden ejecutarse localmente en PC y estaciones de trabajo equipados con GPUs NVIDIA GeForce y RTX.
Los LLM destacan por su capacidad para resumir grandes volúmenes de texto, clasificar y extraer datos en busca de información y generar nuevos textos con un estilo, tono o formato especificados por el usuario. Pueden facilitar la comunicación en cualquier idioma, incluso más allá de los que hablan los humanos, como el código informático o las secuencias proteínicas y genéticas.
Mientras que los primeros LLM trataban únicamente texto, las iteraciones posteriores se entrenaron con otros tipos de datos. Estos LLM multimodales pueden reconocer y generar imágenes, audio, videos y otras formas de contenido.
Chatbots como ChatGPT fueron de los primeros en acercar los LLM a los consumidores, con una interfaz familiar creada para conversar y responder a preguntas en lenguaje natural. Desde entonces, los LLM se han utilizado para ayudar a los desarrolladores a escribir códigos y a los científicos a impulsar el descubrimiento de fármacos y el desarrollo de vacunas.
Sin embargo, los modelos de IA que alimentan esas funciones requieren un gran esfuerzo computacional. La combinación de técnicas de optimización avanzadas y algoritmos como la cuantización con las GPUs RTX, diseñadas específicamente para la IA, ayuda a que los LLM sean lo bastante compactos y los PC lo bastante potentes para ejecutarse localmente (sin necesidad de conexión a Internet). Y una nueva generación de LLM ligeros como Mistral uno de los LLM que impulsa Chat con RTX sienta las bases para un rendimiento de vanguardia con menores demandas de energía y almacenamiento.
¿Por qué son importantes los LLM?
Los LLM pueden adaptarse a una amplia gama de casos de uso, sectores y flujos de trabajo. Esta versatilidad, combinada con su rendimiento de alta velocidad, ofrece mejoras de rendimiento y eficiencia en prácticamente todas las tareas basadas en el lenguaje.
DeepL, que se ejecuta en las GPUs NVIDIA en la nube, utiliza IA avanzada para proporcionar traducciones de texto precisas.
Los LLM se utilizan ampliamente en aplicaciones de traducción de idiomas como DeepL, que utiliza IA y aprendizaje automático para proporcionar resultados precisos.
Los investigadores médicos están formando a los LLM en libros de texto y otros datos médicos para mejorar la atención al paciente. Los minoristas aprovechan los chatbots con LLM para ofrecer experiencias de atención al cliente estelares. Los analistas financieros recurren a los LLM para transcribir y resumir las llamadas de negocios y otras reuniones importantes. Y esto es solo la punta del iceberg.
Los chatbots como ChatRTX y los asistentes de escritura creados a partir de LLM están dejando su huella en todas las facetas del trabajo del conocimiento, desde el marketing de contenidos y la redacción publicitaria hasta las operaciones jurídicas. Los asistentes de codificación fueron de las primeras aplicaciones impulsadas por LLM que apuntaron hacia el futuro del desarrollo de software asistido por IA. Ahora, proyectos como ChatDev combinan los LLM con agentes de IA (robots inteligentes que actúan de forma autónoma para ayudar a responder preguntas o realizar tareas digitales) para crear una empresa de software virtual bajo demanda. Basta con decirle al sistema qué tipo de aplicación se necesita y ver cómo se pone manos a la obra.
Más información sobre los agentes LLM en el blog para desarrolladores de NVIDIA.
Tan fácil como iniciar una conversación
El primer encuentro de muchas personas con la IA generativa se produjo a través de un chatbot como ChatGPT, que simplifica el uso de los LLM a través del lenguaje natural, haciendo que la acción del usuario sea tan sencilla como decirle al modelo lo que tiene que hacer.
Los chatbots con tecnología LLM pueden ayudar a generar un borrador de texto de marketing, ofrecer ideas para unas vacaciones, elaborar un correo electrónico para el servicio de atención al cliente e incluso crear poesía original.
Los avances en la generación de imágenes y los LLM multimodales han ampliado el ámbito del chatbot para incluir el análisis y la generación de imágenes, todo ello manteniendo la maravillosa sencillez de la experiencia del usuario. Basta con describir una imagen al bot o subir una foto y pedir al sistema que la analice. Es chatear, pero ahora con ayudas visuales.
Para obtener más información sobre el diseño de estos bots, consulta el seminario web bajo demanda en Building Intelligent AI Chatbots Using RAG.
Los avances futuros ayudarán a los LLM a ampliar su capacidad de lógica, razonamiento, matemáticas y mucho más, dándoles la posibilidad de dividir peticiones complejas en subtareas más pequeñas.
También se está avanzando en los agentes de IA, aplicaciones capaces de tomar una tarea compleja, dividirla en otras más pequeñas y colaborar de forma autónoma con LLM y otros sistemas de IA para completarlas. ChatDev es un ejemplo de estructura de agentes de IA, pero los agentes no se limitan a tareas técnicas.
Por ejemplo, los usuarios pueden pedir a un agente de viajes personal con IA que reserve unas vacaciones familiares en el extranjero. El agente dividiría esa tarea en subtareas planificación del itinerario, reserva de viaje y alojamiento, creación de listas de equipaje, búsqueda de un paseador de perros y las ejecutaría por orden de forma independiente.
Desbloquear datos personales con RAG
Por muy potentes que sean los LLM y los chatbots para uso general, pueden resultar aún más útiles cuando se combinan con los datos de un usuario individual. De este modo, pueden ayudar a analizar las bandejas de entrada de correo electrónico para descubrir tendencias, revisar densos manuales de usuario para encontrar la respuesta a una pregunta técnica sobre algún hardware o resumir años de estados bancarios y de tarjetas de crédito.
La generación aumentada por recuperación(RAG, por sus siglas en inglés) es una de las formas más sencillas y eficaces de perfeccionar los LLM para un conjunto de datos en particular.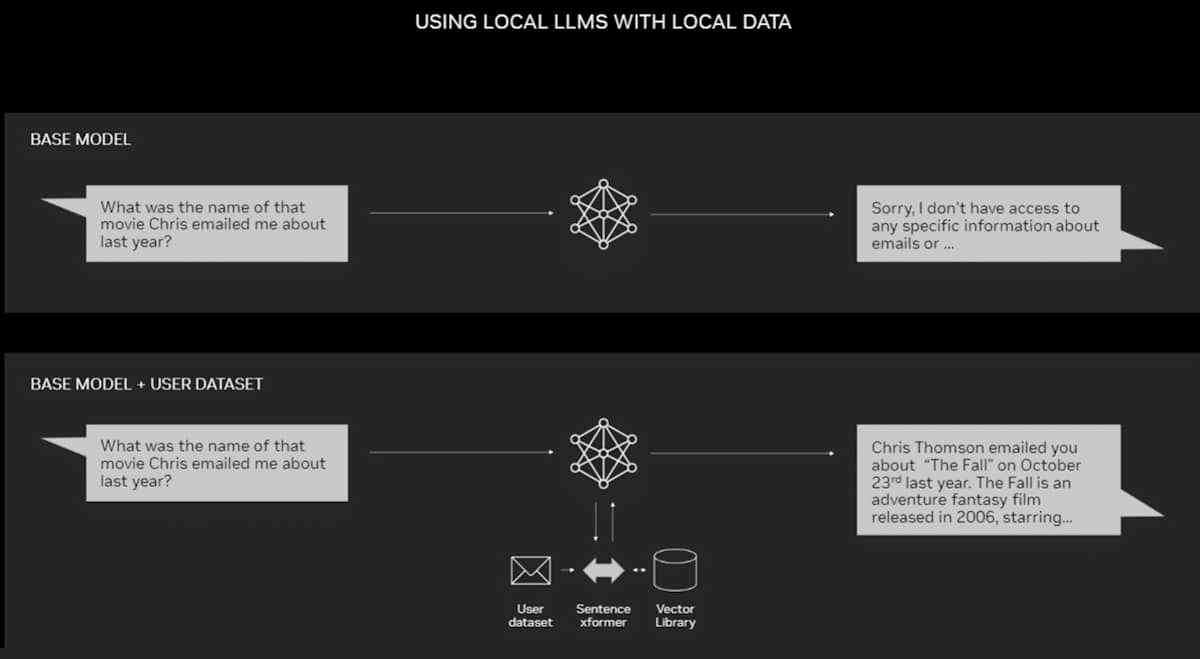
Por ejemplo, un LLM estándar tendrá conocimientos generales sobre las mejores prácticas de estrategia de contenidos, tácticas de marketing y conocimientos básicos sobre un sector o una base de clientes concretos. Pero conectarlo a través de RAG a los activos de marketing que apoyan el lanzamiento de un producto le permitiría analizar el contenido y ayudar a planificar una estrategia a la medida.
RAG funciona con cualquier LLM, siempre que la aplicación lo admita. La demostración técnica ChatRTX de NVIDIA es un ejemplo de cómo RAG conecta un LLM a un conjunto de datos personal. Se ejecuta localmente en sistemas con una GPU profesional GeForce RTX o NVIDIA RTX.
Para conocer más sobre la RAG y su comparación con el ajuste de un LLM, lee el blog técnico, RAG 101: Respuestas a las preguntas sobre generación mejorada de recuperación
Experimenta la velocidad y privacidad del ChatRTX
ChatRTX es una demo de chatbot local y personalizada, fácil de usar y de descarga gratuita. Está construido con funcionalidad RAG y aceleración TensorRT-LLM y RTX. Es compatible con múltiples LLM de código abierto, incluyendo Llama 2 de Meta y Mistral de Mistral. El soporte para Gemma de Google llegará en una futura actualización.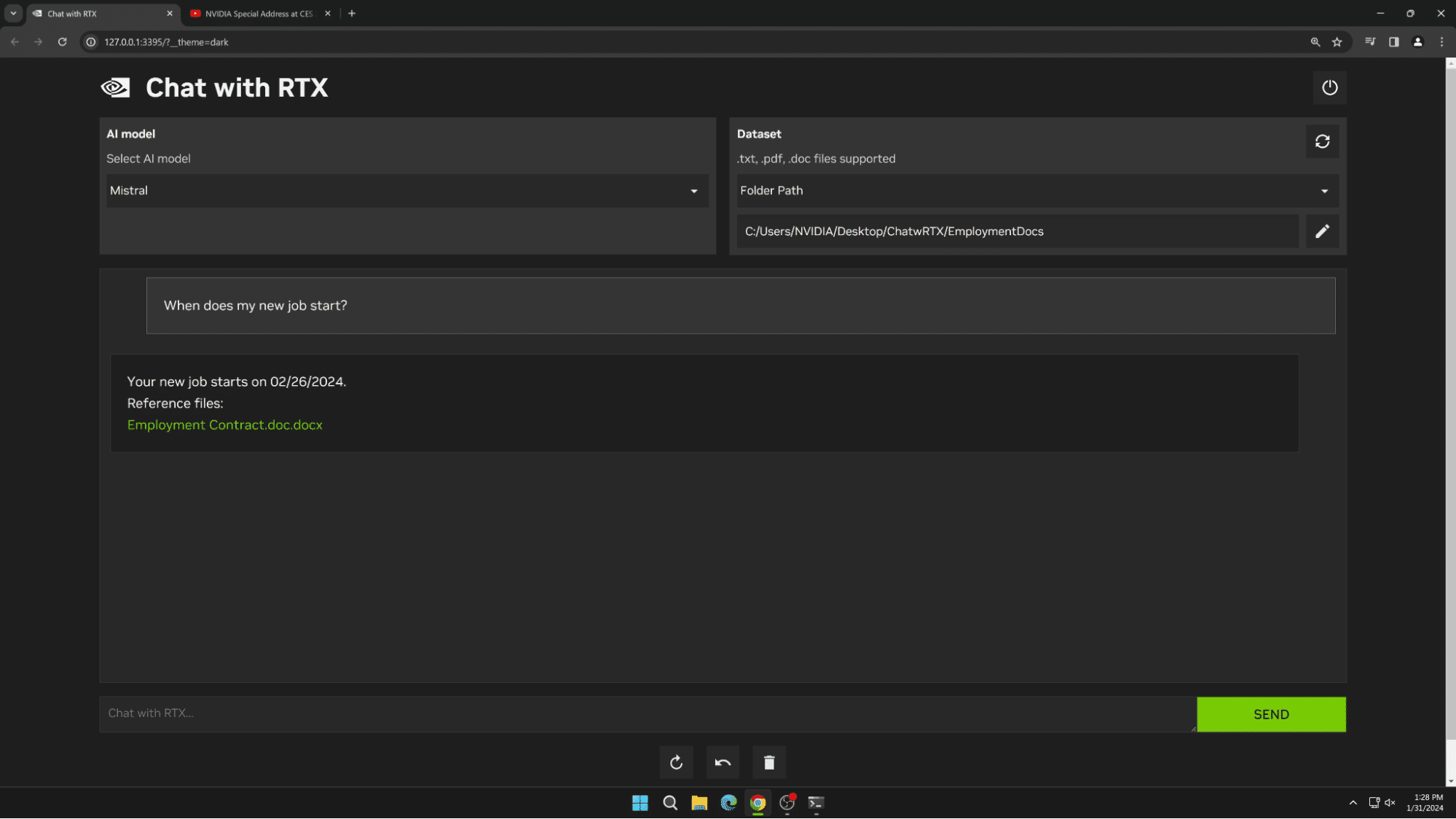
ChatRTX conecta a los usuarios con sus datos personales a través de RAG.Los usuarios pueden conectar fácilmente los archivos locales de un PC a un LLM compatible simplemente colocando los archivos en una carpeta y apuntando la demo a esa ubicación. De este modo, puede responder a las consultas con respuestas rápidas y contextualmente relevantes.
Como ChatRTX se ejecuta localmente en Windows con una PC GeForce RTX y estaciones de trabajo NVIDIA RTX, los resultados son rápidos y los datos del usuario permanecen en el dispositivo. En lugar de depender de servicios basados en la nube, ChatRTX permite a los usuarios procesar datos confidenciales en una PC local sin necesidad de compartirlos con terceros o disponer de conexión a Internet.