Los grandes modelos de lenguaje (LLM) son algoritmos de deep learning que se entrenan en conjuntos de datos a escala de internet con cientos de miles de millones de parámetros. Los LLM pueden leer, escribir, codificar, dibujar y aumentar la creatividad humana para mejorar la productividad en todas las industrias y resolver los problemas más difíciles del mundo.
Los LLM se utilizan en una amplia gama de industrias, desde el comercio minorista hasta la área de la salud, y para una amplia gama de tareas. Aprenden el lenguaje de las secuencias de proteínas para generar compuestos nuevos y viables que pueden ayudar a los científicos a desarrollar vacunas innovadoras que salvan vidas. Ayudan a los programadores de software a generar código y corregir errores basados en descripciones en lenguaje natural. Y proporcionan copilotos de productividad para que los humanos puedan hacer lo que mejor saben hacer: crear, cuestionar y comprender.
Aprovechar eficazmente los LLM en aplicaciones y workflows empresariales requiere comprender temas clave como la selección, la personalización, la optimización y la implementación de modelos. Esta publicación explora los siguientes temas de LLM empresarial:
- Cómo las organizaciones utilizan los LLM
- ¿Usar, personalizar o crear un LLM?
- Comience con los modelos de base
- Creación de un modelo de lenguaje personalizado
- Conectar un LLM a datos externos
- Mantenga los LLM seguros y encaminados
- Optimice la inferencia de LLM en producción
- Introducción al uso de los LLM
Tanto si eres un científico de datos que busca crear modelos personalizados como si eres un director de datos que explora el potencial de los LLM para tu empresa, sigue leyendo para obtener información y orientación valiosas.
Cómo las Empresas Utilizan los LLM
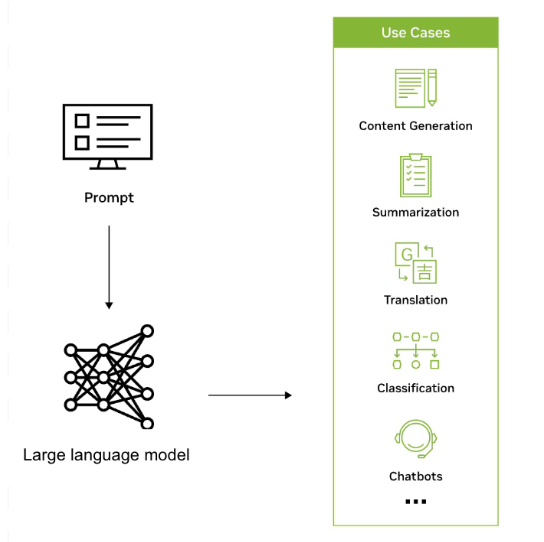
Los LLM se utilizan en una amplia variedad de aplicaciones en todas las industrias para reconocer, resumir, traducir, predecir y generar texto y otras formas de contenido de manera eficiente en función del conocimiento obtenido de conjuntos de datos masivos. Por ejemplo, las empresas están aprovechando los LLM para desarrollar interfaces similares a las de los chatbots que pueden ayudar a los usuarios con las consultas de los clientes, proporcionar recomendaciones personalizadas y ayudar con la gestión del conocimiento interno.
Los LLM también tienen el potencial de ampliar el alcance de la IA en todas las industrias y empresas y permitir una nueva ola de investigación, creatividad y productividad. Pueden ayudar a generar soluciones complejas a problemas desafiantes en campos como el área de la salud y la química. Los LLM también se utilizan para crear motores de búsqueda reinventados, chatbots de tutoría, herramientas de composición, materiales de marketing y más.
La colaboración entre ServiceNow y NVIDIA ayudará a impulsar nuevos niveles de automatización para impulsar la productividad y maximizar el impacto empresarial. Los casos de uso de IA generativa que se están explorando incluyen el desarrollo de asistentes virtuales y agentes inteligentes para ayudar a responder a las preguntas de los usuarios y resolver las solicitudes de soporte, y el uso de la IA generativa para la resolución automática de problemas, la generación de artículos de la base de conocimientos y el resumen de chats.
Un consorcio de Suecia está desarrollando un modelo de lenguaje de última generación con NVIDIA NeMo Megatron y lo pondrá a disposición de cualquier usuario de la región nórdica. El equipo tiene como objetivo entrenar un LLM con la friolera de 175 mil millones de parámetros que pueda manejar todo tipo de tareas lingüísticas en los idiomas nórdicos sueco, danés, noruego y, potencialmente, islandés.
El proyecto se considera un activo estratégico, una piedra angular de la soberanía digital en un mundo que habla miles de idiomas en casi 200 países. Para obtener más información, consulte El Sueco del Rey: a IA Reescribe las Reglas en Escandinavia.
El operador móvil líder en Corea del Sur, KT, ha desarrollado un LLM de mil millones de parámetros utilizando la plataforma NVIDIA DGX SuperPOD y el framework NVIDIA NeMo. NeMo es un framework empresarial nativo de la nube de extremo a extremo que proporciona componentes prediseñados para crear, capacitar y ejecutar LLM personalizados.
El LLM de KT se ha utilizado para mejorar la comprensión del altavoz impulsado por IA de la compañía, GiGA Genie, que puede controlar televisores, ofrecer actualizaciones de tráfico en tiempo real y completar otras tareas de asistencia en el hogar basadas en comandos de voz. Para obtener más información, consulte Que No Se Corte la Llamada en Hangul: KT Capacita Altavoces Inteligentes y Centros de Llamadas de Clientes con la IA de NVIDIA.
¿Usar, Personalizar o Crear un LLM?
Las empresas pueden optar por usar un LLM existente, personalizar un LLM previamente entrenado o crear un LLM personalizado desde cero. El uso de un LLM existente proporciona una solución rápida y rentable, mientras que la personalización de un LLM previamente entrenado permite a las empresas ajustar el modelo para tareas específicas e incorporar conocimientos propios. Crear un LLM desde cero ofrece la mayor flexibilidad, pero requiere una gran experiencia y recursos.
NeMo ofrece una selección de varias técnicas de personalización y está optimizado para la inferencia a escala de modelos para aplicaciones de lenguaje e imágenes, con configuraciones de múltiples GPU y nodos. Para obtener más información, consulte Unlocking the Power of Enterprise-Ready LLMs with NVIDIA NeMo.
NeMo hace que el desarrollo de modelos de IA generativa sea fácil, rentable y rápido para las empresas. Está disponible en todas las nubes principales, incluida Google Cloud, como parte de sus instancias A3 con tecnología de GPU NVIDIA H100 Tensor Core para crear, personalizar e implementar LLM a escala. Para obtener más información, consulta Streamline Generative AI Development with NVIDIA NeMo on GPU-Accelerated Google Cloud.
Para probar rápidamente modelos de IA generativa como Llama 2 directamente desde tu navegador con una interfaz fácil de usar, visita NVIDIA AI Playground.
Comience con los Modelos de Base
Los modelos de base son grandes modelos de IA entrenados con enormes cantidades de datos sin etiquetar a través del aprendizaje autosupervisado. Algunos ejemplos son Llama 2, GPT-3 y Stable Diffusion.
Los modelos pueden manejar una amplia variedad de tareas, como la clasificación de imágenes, el procesamiento del lenguaje natural y la respuesta a preguntas, con una precisión notable.
Estos modelos de base son el punto de partida para construir modelos personalizados más especializados y sofisticados. Las empresas pueden personalizar los modelos de base utilizando datos etiquetados específicos del dominio para crear modelos más precisos y sensibles al contexto para casos de uso específicos.
Los modelos de base generan un enorme número de respuestas únicas a partir de un único mensaje generando una distribución de probabilidad sobre todos los elementos que podrían seguir a la entrada y, a continuación, eligiendo la siguiente salida al azar de esa distribución. La aleatorización se amplifica por el uso del contexto en el modelo. Cada vez que el modelo genera una distribución de probabilidad, tiene en cuenta el último elemento generado, lo que significa que cada predicción afecta a todas las predicciones que siguen.
NeMo es compatible con los modelos de base entrenados por NVIDIA, así como con los modelos de la comunidad, como Llama 2, Falcon LLM y MPT. Puedes experimentar una variedad de modelos optimizados de la comunidad y de la base creados por NVIDIA directamente desde tu navegador de forma gratuita en NVIDIA AI Playground. A continuación, puede personalizar el modelo de base utilizando sus datos empresariales patentados. Esto da como resultado un modelo que es experto en su negocio y dominio.
Creación de un Modelo Personalizado de Lenguaje
Las empresas a menudo necesitarán modelos personalizados para adaptar las capacidades de procesamiento del lenguaje a sus casos de uso específicos y conocimiento del dominio. Los LLM personalizados permiten a una empresa generar y comprender texto de manera más eficiente y precisa dentro de un determinado contexto empresarial o de la industria. Permiten a las empresas crear soluciones personalizadas que se alinean con la voz de su marca, optimizan los workflows, proporcionan información más precisa y ofrecen experiencias de usuario mejoradas, lo que en última instancia impulsa una ventaja competitiva en el mercado.
NVIDIA NeMo es un potente framework que proporciona componentes para crear y entrenar LLM personalizados en las instalaciones, en todos los principales proveedores de servicios en la nube o en NVIDIA DGX Cloud. Incluye un conjunto de técnicas de personalización, desde el aprendizaje rápido hasta el ajuste fino eficiente de parámetros, pasando por el aprendizaje por refuerzo a través de la retroalimentación humana (RLHF). NVIDIA también lanzó una nueva técnica de personalización abierta llamada SteerLM que permite el ajuste durante la inferencia.
Al entrenar un LLM, siempre existe el riesgo de que se convierta en «basura que entra, basura que sale». Un gran porcentaje del esfuerzo consiste en adquirir y conservar los datos que se utilizarán para entrenar o personalizar el LLM.
NeMo Data Curator es una herramienta escalable de curación de datos que le permite seleccionar conjuntos de datos multilingües de billones de tokens para el entrenamiento previo de LLM. La herramienta le permite preprocesar y deduplicar conjuntos de datos con deduplicación exacta o difusa, por lo que puede asegurarse de que los modelos se entrenan en documentos únicos, lo que puede reducir considerablemente los costos de entrenamiento.
Conectar un LLM a Datos Externos
La conexión de un LLM a fuentes de datos empresariales externas mejora sus capacidades. Esto permite al LLM realizar tareas más complejas y aprovechar los datos que se han creado desde la última vez que se entrenó.
Retrieval Augmented Generation (RAG) es una arquitectura que proporciona a un LLM la capacidad de utilizar fuentes de datos actuales, seleccionadas y específicas del dominio que son fáciles de agregar, eliminar y actualizar. Con RAG, las fuentes de datos externas se procesan en vectores (utilizando un modelo de incrustación) y se colocan en una base de datos de vectores para una recuperación rápida en el momento de la inferencia.
Además de reducir los costos computacionales y financieros, RAG aumenta la precisión y permite aplicaciones impulsadas por IA más confiables y confiables. La aceleración de la búsqueda vectorial es uno de los temas más candentes en el panorama de la IA debido a sus aplicaciones en los LLM y la IA generativa.
Mantenga los LLM Seguros y en el Buen Camino
Para garantizar que el comportamiento de un LLM se alinee con los resultados deseados, es importante establecer pautas, supervisar su rendimiento y personalizarlo según sea necesario. Esto implica definir límites éticos, abordar los sesgos en los datos de entrenamiento y evaluar regularmente los resultados del modelo con respecto a métricas predefinidas, a menudo junto con una capacidad de barandillas. Para obtener más información, consulte NVIDIA Enables Trustworthy, Safe, and Secure Large Language Model Conversational Systems.
Para abordar esta necesidad, NVIDIA ha desarrollado NeMo Guardrails, un conjunto de herramientas de código abierto que ayuda a los desarrolladores a garantizar que sus aplicaciones de IA generativa sean precisas, apropiadas y seguras. Proporciona un framework que funciona con todos los LLM, incluido ChatGPT de OpenAI, para facilitar a los desarrolladores la creación de sistemas conversacionales de LLM seguros y confiables que aprovechen los modelos básicos.
Mantener la seguridad de los LLM es de suma importancia para las aplicaciones impulsadas por IA generativa. NVIDIA también ha introducido la Computación Confidencial acelerada, una función de seguridad innovadora que mitiga las amenazas al tiempo que proporciona acceso a la aceleración sin precedentes de las GPU NVIDIA H100 Tensor Core para cargas de trabajo de IA. Esta función garantiza que los datos confidenciales permanezcan seguros y protegidos, incluso durante el procesamiento.
Optimice la Inferencia de LLM en Producción
La optimización de la inferencia de LLM implica técnicas como la cuantificación de modelos, la aceleración de hardware y estrategias de implementación eficientes. La cuantificación del modelo reduce la huella de memoria del modelo, mientras que la aceleración de hardware aprovecha el hardware especializado, como las GPU, para una inferencia más rápida. Las estrategias de implementación eficientes garantizan la escalabilidad y la confiabilidad en los entornos de producción.
NVIDIA TensorRT-LLM es una biblioteca de software de código abierto que potencia la inferencia de LLM de gran tamaño en la computación acelerada de NVIDIA. Permite a los usuarios convertir los pesos de sus modelos a un nuevo formato FP8 y compilar sus modelos para aprovechar los kernels FP8 optimizados con las GPU NVIDIA H100. TensorRT-LLM puede acelerar el rendimiento de inferencia en 4,6 veces en comparación con las GPU NVIDIA A100. Proporciona una forma más rápida y eficiente de ejecutar LLM, haciéndolos más accesibles y rentables.
Estos procesos personalizados de IA generativa implican la unión de modelos, frameworks, kits de herramientas y mucho más. Muchas de estas herramientas son de código abierto, lo que requiere tiempo y energía para mantener los proyectos de desarrollo. El proceso puede llegar a ser increíblemente complejo y llevar mucho tiempo, especialmente cuando se trata de colaborar e implementar en múltiples entornos y plataformas.
NVIDIA AI Workbench ayuda a simplificar este proceso al proporcionar una plataforma única para administrar datos, modelos, recursos y necesidades de computación. Esto permite una colaboración e implementación fluidas para que los desarrolladores creen rápidamente modelos de IA generativa rentables y escalables.
NVIDIA y VMware están trabajando juntos para transformar el data center moderno basado en VMware Cloud Foundation y llevar la IA a todas las empresas. Con la suite NVIDIA AI Enterprise y las GPU y unidades de procesamiento de datos (DPU) más avanzadas de NVIDIA, los clientes de VMware pueden ejecutar de forma segura cargas de trabajo modernas y aceleradas junto con las aplicaciones empresariales existentes en Sistemas Certificados por NVIDIA.
Introducción al Uso de los LLM
Comenzar con los LLM requiere sopesar factores como el costo, el esfuerzo, la disponibilidad de datos de capacitación y los objetivos comerciales. En la mayoría de los casos, las empresas deben evaluar las ventajas y desventajas entre el uso de modelos existentes y su personalización con conocimientos específicos del dominio frente a la creación de modelos personalizados desde cero. Es importante elegir herramientas y frameworks que se alineen con casos de uso específicos y requisitos técnicos, incluidos los que se enumeran a continuación.
El Laboratorio de Chatbot de la Base de Conocimientos de IA Generativa le muestra cómo adaptar un modelo fundamental de IA existente para generar respuestas precisas para su caso de uso específico. Este laboratorio gratuito proporciona experiencia práctica en la personalización de un modelo mediante el aprendizaje rápido, la ingesta de datos en una base de datos vectorial y el encadenamiento de todos los componentes para crear un chatbot.
NVIDIA AI Enterprise, disponible en las principales plataformas de nube y data centers, es un conjunto de software de análisis de datos e IA nativo de la nube que proporciona más de 50 frameworks, incluido el framework NeMo, modelos preentrenados y herramientas de desarrollo optimizadas para infraestructuras de GPU aceleradas. Puede probar este paquete de software de extremo a extremo listo para la empresa con una prueba gratuita de 90 días.
NeMo es un framework empresarial nativo de la nube de extremo a extremo para que los desarrolladores construyan, personalicen e implementen modelos de IA generativa con miles de millones de parámetros. Está optimizado para la inferencia a escala de modelos con configuraciones de varias GPU y varios nodos. El marco hace que el desarrollo de modelos de IA generativa sea fácil, rentable y rápido para las empresas. Explora los tutoriales de NeMo para empezar.
NVIDIA Training ayuda a las empresas a capacitar a su fuerza laboral en la última tecnología y cerrar la brecha de habilidades al ofrecer talleres y cursos prácticos técnicos integrales. La ruta de aprendizaje de LLM desarrollada por expertos en la materia de NVIDIA abarca temas fundamentales y avanzados que son relevantes para los equipos de ingeniería de software y operaciones de TI. Los asesores de formación de NVIDIA están disponibles para ayudar a desarrollar planes de formación personalizados y ofrecer precios para equipos.