La plataforma NVIDIA Blackwell ha sido ampliamente adoptada por los principales proveedores de inferencia, como Baseten, DeepInfra, Fireworks IA y Together IA, para reducir el costo por token hasta en diez veces. Ahora, la plataforma NVIDIA Blackwell Ultra está llevando este impulso aún más allá para la IA agéntica.
Los agentes de IA y los asistentes de codificación están impulsando un crecimiento explosivo en las consultas de IA relacionadas con la programación de software: del 11 % a aproximadamente el 50 % el año pasado, según el informe sobre el Estado de la Inferencia de OpenRouter. Estas aplicaciones requieren una baja latencia para mantener la capacidad de respuesta en tiempo real en los flujos de trabajo de múltiples pasos y contexto largo al razonar en bases de código completas.
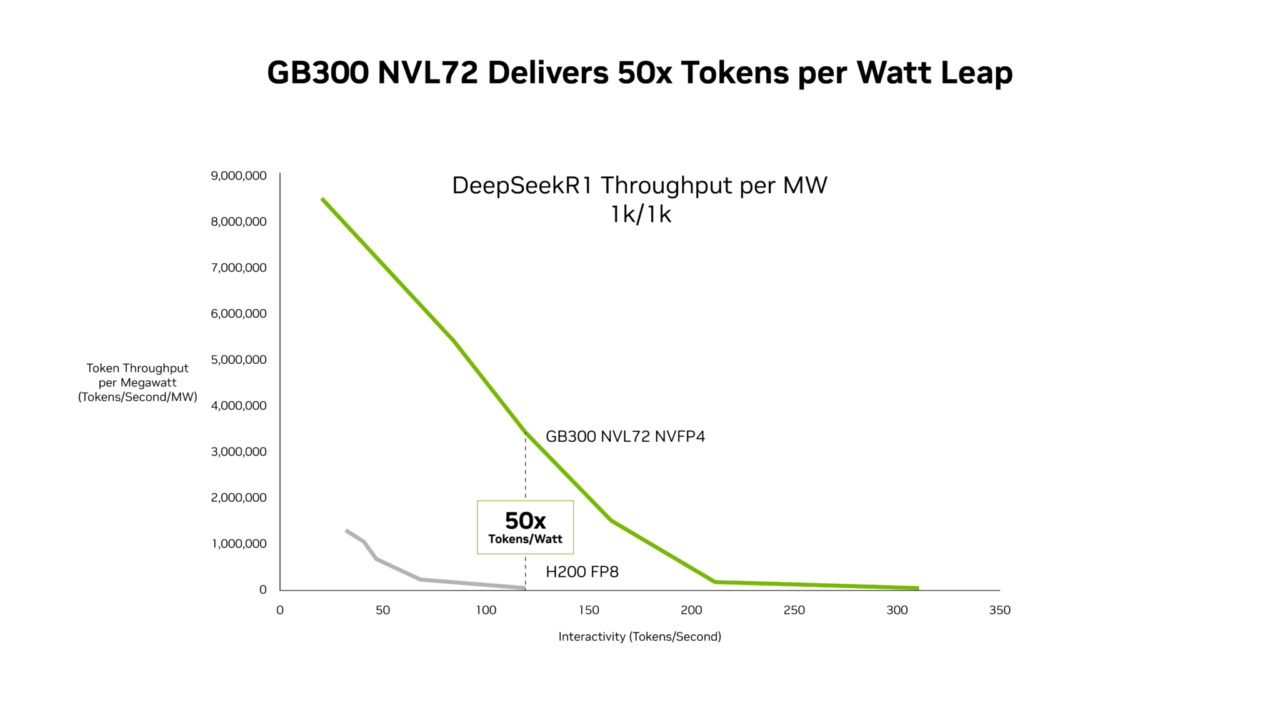
Los nuevos datos de desempeño de SemiAnalysis InferenceX muestran que la combinación de las optimizaciones de software de NVIDIA y la plataforma NVIDIA Blackwell Ultra de última generación ha ofrecido avances innovadores en ambos frentes. Los sistemas NVIDIA GB300 NVL72 ahora ofrecen un rendimiento por megavatio hasta 50 veces mayor, lo que resulta en un costo por token 35 veces menor en comparación con la plataforma NVIDIA Hopper.
Al innovar en los chips, la arquitectura de sistemas y el software, el diseño conjunto extremo de NVIDIA acelera el desempeño en todas las cargas de trabajo de IA, desde la codificación agéntica hasta los asistentes de codificación interactivos, a la vez que reduce los costos a escala.

GB300 NVL72 Ofrece un Desempeño Hasta 50 Veces Mejor para Cargas de Trabajo de Baja Latencia
Un análisis reciente de Signal65 muestra que NVIDIA GB200 NVL72 con un diseño conjunto extremo de hardware y software ofrece más de diez veces más tokens por vatio, lo que resulta en una décima parte del costo por token en comparación con la plataforma NVIDIA Hopper. Estas ganancias masivas de desempeño continúan expandiéndose a medida que mejora la pila subyacente.
Las optimizaciones continuas de los equipos de NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake y SGLang continúan aumentando significativamente el rendimiento de Blackwell NVL72 para la inferencia de mezcla de expertos (MoE) en todos los objetivos de latencia. Por ejemplo, las mejoras en la biblioteca NVIDIA TensorRT-LLM han ofrecido un desempeño hasta 5 veces mejor en GB200 para cargas de trabajo de baja latencia en comparación con lo que sucedía cuatro meses atrás.
- Los núcleos de GPU de mayor desempeño optimizados para la eficiencia y la baja latencia ayudan a aprovechar al máximo las inmensas capacidades de computación de Blackwell y a aumentar el rendimiento.
- La Memoria Simétrica NVLink de NVIDIA permite el acceso directo a la memoria de GPU a GPU para una comunicación más eficiente.
- El lanzamiento dependiente programático minimiza el tiempo de inactividad al lanzar la siguiente fase de configuración del kernel antes de que se complete la anterior.
Sobre la base de estos avances de software, GB300 NVL72, que cuenta con la GPU Blackwell Ultra, eleva la frontera del rendimiento por megavatio a 50 veces en comparación con la plataforma Hopper.
Esta ganancia de desempeño se traduce en una economía superior, ya que NVIDIA GB300 reduce los costos en comparación con la plataforma Hopper en todo el espectro de latencia. La reducción más drástica ocurre a baja latencia, donde operan las aplicaciones agénticas: un costo hasta 35 veces menor por millón de tokens en comparación con la plataforma Hopper.
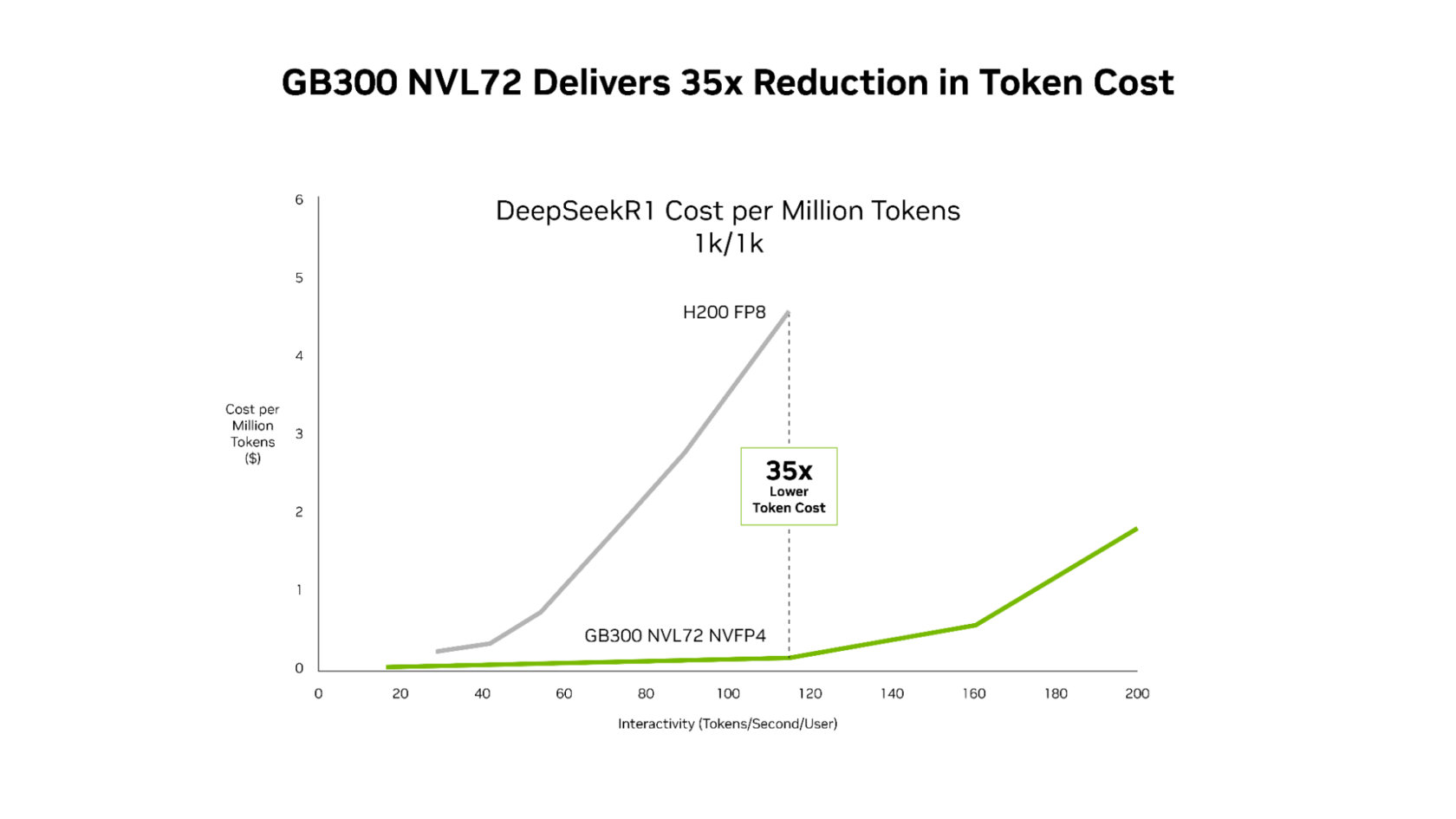
NVIDIA GB300 NVL72 y la pila de software diseñada conjuntamente, que incluyen NVIDIA Dynamo y TensorRT-LLM, ofrecen un costo por token 35 veces menor en comparación con la plataforma NVIDIA Hopper.
Para las cargas de trabajo de codificación agéntica y asistentes interactivos, donde cada milisegundo se compone en flujos de trabajo de múltiples pasos, esta combinación de optimización de software incesante y hardware de última generación permite a las plataformas de IA escalar experiencias interactivas en tiempo real a un número significativamente mayor de usuarios.
GB300 NVL72 Ofrece una Economía Superior para Cargas de Trabajo de Contexto Largo
Si bien GB200 NVL72 y GB300 NVL72 ofrecen de manera eficiente una latencia ultrabaja, las distintas ventajas de GB300 NVL72 se vuelven más evidentes en escenarios de contexto largo. Para las cargas de trabajo con entradas de 128,000 tokens y resultados de 8,000 tokens, como el razonamiento de los asistentes de codificación de IA en todas las bases de código, GB300 NVL72 ofrece un costo por token hasta 1.5 veces menor en comparación con GB200 NVL72.
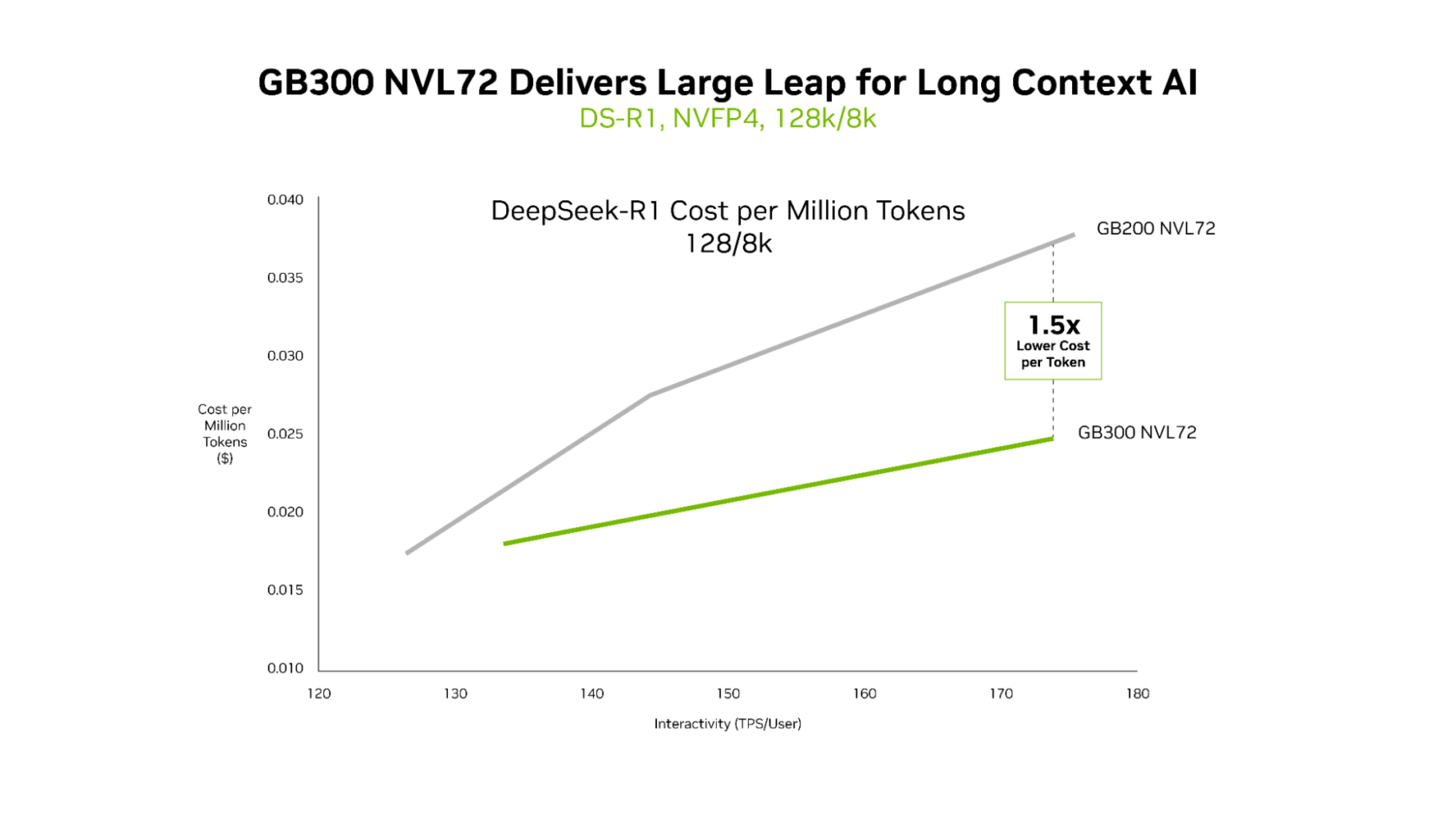
NVIDIA GB300 NVL72 es ideal para cargas de trabajo de baja latencia y contexto largo.
El contexto crece a medida que el agente lee una parte mayor del código. Esto le permite comprender mejor la base de código, pero también requiere mucha más computación. Blackwell Ultra tiene un desempeño de computación NVFP4 1.5 veces mayor y un procesamiento de atención dos veces más rápido, lo que permite al agente comprender de manera eficiente bases de código completas.
Infraestructura para IA Basada en Agentes
Los principales proveedores de nube y los innovadores de IA ya han implementado NVIDIA GB200 NVL72 a escala y también están implementando GB300 NVL72 en la producción. Microsoft, CoreWeave y OCI están implementando GB300 NVL72 para casos de uso de baja latencia y contexto largo, como la codificación agéntica y los asistentes de codificación. Al reducir los costos de tokens, GB300 NVL72 permite una nueva clase de aplicaciones que pueden razonar en bases de código masivas en tiempo real.
«A medida que la inferencia se mueve al centro de la producción de IA, el desempeño en contexto largo y la eficiencia de tokens se vuelven críticos», dijo Chen Goldberg, vicepresidente sénior de ingeniería de CoreWeave. “Grace Blackwell NVL72 aborda ese desafío directamente, y la nube de IA de CoreWeave, incluidos CKS y SUNK, está diseñada para traducir las ganancias de los sistemas GB300, sobre la base del éxito de GB200, en un desempeño predecible y una eficiencia de costos.” El resultado es una mejor economía de tokens y una inferencia más utilizable para los clientes que ejecutan cargas de trabajo a escala».
NVIDIA Vera Rubin NVL72 para Aportar Desempeño de Última Generación
Con los sistemas NVIDIA Blackwell implementados a escala, las optimizaciones continuas de software seguirán posibilitando mejoras adicionales en el desempeño y los costos en toda la base instalada.
De cara al futuro, la plataforma NVIDIA Rubin, que combina seis chips nuevos para crear una supercomputadora de IA, ofrecerá otra ronda de saltos masivos en el desempeño. Para la inferencia de MoE, ofrece un rendimiento por megavatio hasta 10 veces mayor en comparación con Blackwell, lo que se traduce en una décima parte del costo por millón de tokens. Y para la próxima ola de modelos de IA de vanguardia, Rubin puede entrenar grandes modelos MoE usando solo una cuarta parte del número de GPU en comparación con Blackwell.
Más Información sobre la plataforma NVIDIA Rubin y el sistema Vera Rubin NVL72.