
NVIDIA ofrece los mejores resultados en inferencia de IA utilizando CPU x86 o basadas en Arm, según las evaluaciones publicadas recientemente.
Es la tercera vez consecutiva que NVIDIA establece récords en rendimiento y eficiencia energética en evaluaciones de inferencia de MLCommons, un grupo de evaluación comparativa de la industria formado en mayo de 2018.
Y es la primera vez que las pruebas de categoría de data centers se ejecutan en un sistema basado en Arm, lo que brinda a los usuarios más opciones sobre cómo implementar la IA, la tecnología más transformadora de nuestro tiempo.
Historia de la Cinta
Las computadoras impulsadas por la plataforma de IA de NVIDIA encabezaron las siete pruebas de rendimiento de inferencia en la última ronda con sistemas de NVIDIA y nueve de nuestros socios del ecosistema, incluidos Alibaba, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Nettrix y Supermicro.
Y NVIDIA es la única compañía que informa los resultados de todas las pruebas de MLPerf en esta y en todas las rondas hasta la fecha.
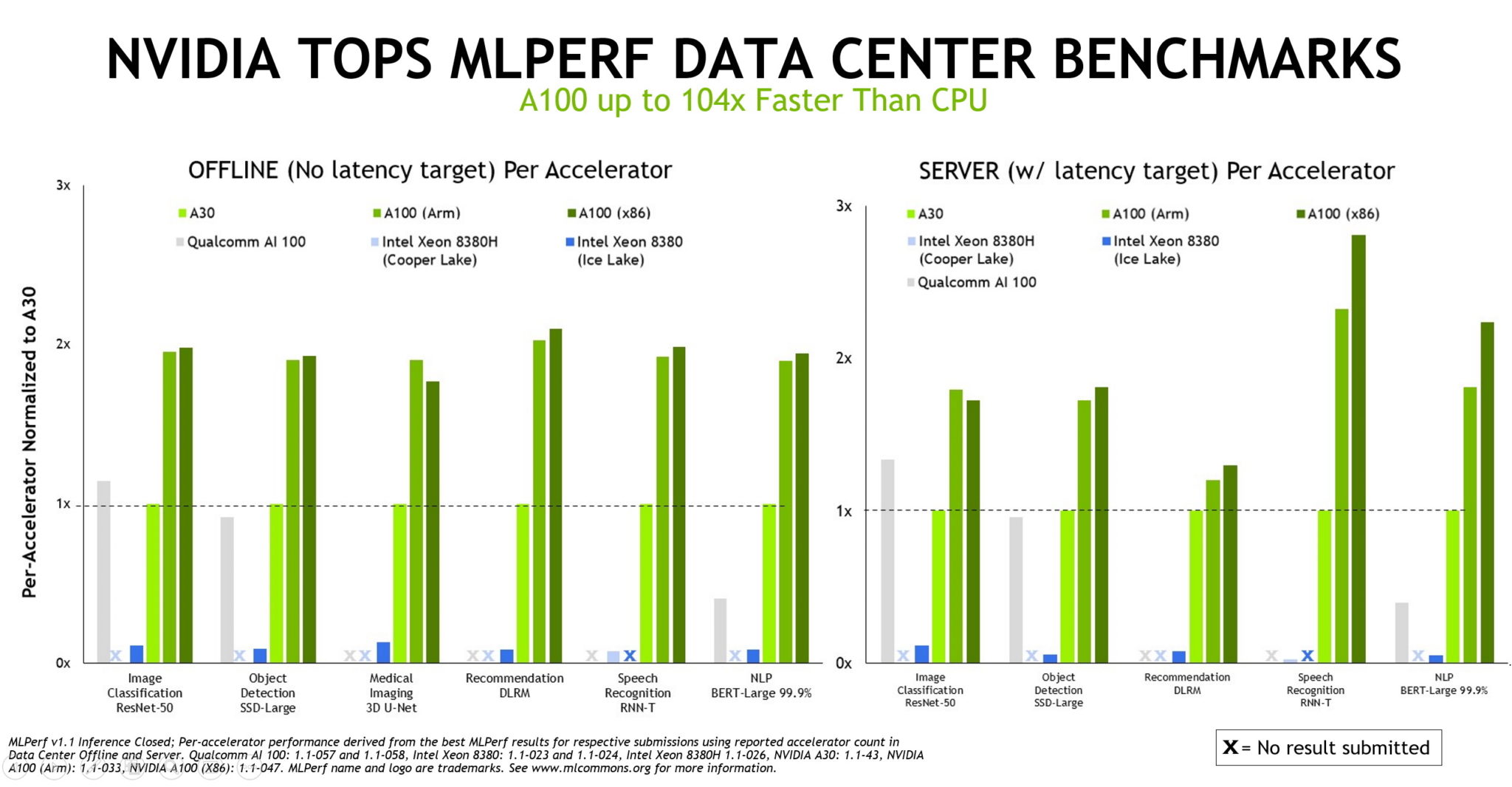
La inferencia es lo que sucede cuando una computadora ejecuta un software de IA para reconocer un objeto o hacer una predicción. Es un proceso que utiliza un modelo de deep learning para filtrar datos, y así encontrar resultados que ningún humano podría capturar.
Sus evaluaciones se basan en las cargas de trabajo y los escenarios de IA más populares de la actualidad, que abarcan la visión de computación, el procesamiento de imágenes médicas, los sistemas de recomendación, el aprendizaje por refuerzo y más.
Por lo tanto, independientemente de las aplicaciones de IA que implementen, los usuarios pueden establecer sus propios registros con NVIDIA.
Por Qué Importa el Rendimiento
Los modelos y conjuntos de datos de IA continúan creciendo a medida que los casos de uso de IA se expanden desde el data center hasta el edge y más allá. Es por eso que los usuarios necesitan un rendimiento que sea confiable y flexible de implementar.
MLPerf da a los usuarios la confianza para tomar decisiones de compra informadas. Además, están respaldadas por docenas de líderes de la industria, incluidos Alibaba, Arm, Baidu, Google, Intel y NVIDIA, por lo que las pruebas son transparentes y objetivas.
Arm Flexible para IA Empresarial
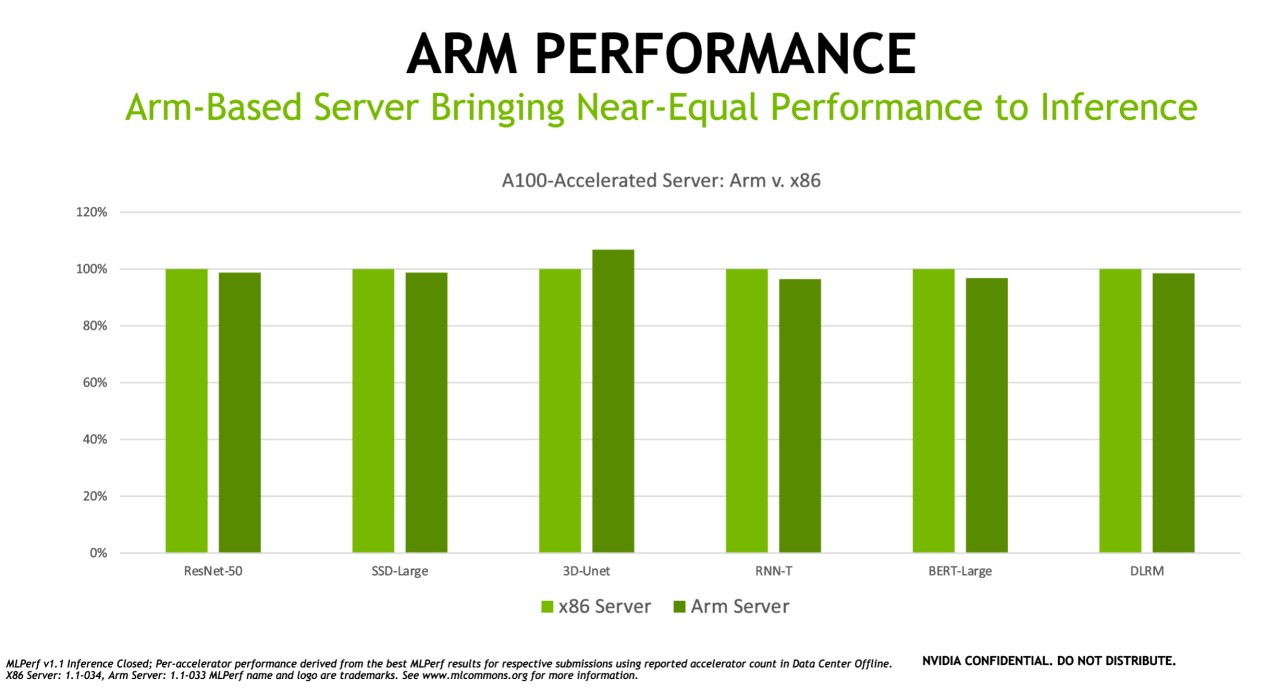
La arquitectura de Arm está avanzando en los data centers de todo el mundo, en parte gracias a su eficiencia energética, aumentos de rendimiento y ecosistema de software en expansión.
Las última evaluaciones muestran que, como plataforma acelerada por GPU, los servidores basados en Arm que utilizan la CPU Ampere Altra ofrecen un rendimiento casi igual al de los servidores basados en x86 configurados de manera similar para trabajos de inferencia de IA. De hecho, en una de las pruebas, el servidor basado en Arm superó a un sistema x86 similar.
NVIDIA tiene una larga tradición en admitir todas las arquitecturas de CPU, por lo que estamos orgullosos de ver que Arm demuestra su destreza en IA en una evaluación de la industria con revisión de pares.
“Arm, como miembro fundador de MLCommons, está comprometido con el proceso de creación de estándares y evaluaciones para abordar mejor los desafíos e inspirar la innovación en la industria de la computación acelerada”, dijo David Lecomber, director senior de HPC y herramientas en Arm.
“Los últimos resultados de inferencia demuestran la preparación de los sistemas basados en Arm impulsados por las CPU basadas en Arm y las GPU de NVIDIA para abordar una amplia gama de cargas de trabajo de IA en el data center”, agregó.
Los Socios Muestran sus Poderes de IA
La tecnología de IA de NVIDIA está respaldada por un ecosistema grande y en crecimiento.
Siete OEM presentaron un total de 22 plataformas aceleradas por GPU en las últimas evaluaciones.
La mayoría de estos modelos de servidor están certificados por NVIDIA y validados para ejecutar una amplia gama de cargas de trabajo aceleradas. Además, muchos de ellos son compatibles con NVIDIA AI Enterprise, el software que se lanzó oficialmente el mes pasado.
Nuestros socios que participaron en esta ronda son Dell Technologies, Fujitsu, Hewlett Packard Enterprise, Inspur, Lenovo, Nettrix y Supermicro, así como el proveedor de servicios de cloud Alibaba.
El Poder del Software
Un ingrediente clave del éxito de la IA de NVIDIA en todos los casos de uso es nuestra pila de software completa.
Para la inferencia, eso incluye modelos de IA previamente entrenados para una amplia variedad de casos de uso. El Kit de Herramientas NVIDIA TAO personaliza esos modelos para aplicaciones específicas mediante el aprendizaje por transferencia.
Nuestro software NVIDIA TensorRT optimiza los modelos de IA para que aprovechen al máximo la memoria y se ejecuten más rápido. Lo usamos rutinariamente para las pruebas de MLPerf, y está disponible tanto para los sistemas x86 como los sistemas basados en Arm.
También empleamos nuestro software para el Servidor de Inferencia NVIDIA Triton y la capacidad de GPU de Múltiples Instancias (MIG) en estas evaluaciones. Ofrecen a todos los desarrolladores el tipo de rendimiento que generalmente requiere codificadores expertos.
Gracias a las continuas mejoras en esta pila de software, NVIDIA logró ganancias de hasta el 20 por ciento en rendimiento y el 15 por ciento en eficiencia energética con respecto a las evaluaciones MLPerf de inferencia anteriores de hace solo cuatro meses.
Todo el software que utilizamos para las últimas pruebas está disponible en el repositorio de MLPerf, por lo que cualquiera puede reproducir nuestros resultados de las evaluaciones. Continuamente agregamos este código a nuestros frameworks de deep learning y contenedores disponibles en NGC, nuestro centro de software para aplicaciones de GPU.
Es parte de una oferta de IA de pila completa, compatible con todas las principales arquitecturas de procesadores, probada en las evaluaciones más recientes de la industria y disponible para abordar trabajos reales de IA en la actualidad.
Para obtener más información sobre la plataforma de inferencia de NVIDIA, consulta nuestra Descripción General de la Tecnología de Inferencia de NVIDIA.