
La clave para convertirte en médico especialista, en cualquier disciplina, es la experiencia.
Saber cómo interpretar los síntomas, qué paso implementar a continuación en situaciones críticas y qué tratamiento proporcionar; todo se reduce al entrenamiento que has tenido y las oportunidades que has tenido para aplicarlo.
Para los algoritmos de IA, la experiencia toma la forma de conjuntos de datos grandes, variados y de alta calidad. Pero estos conjuntos de datos tradicionalmente han resultado difíciles de conseguir, especialmente en el área de la salud.
Las instituciones médicas han tenido que depender de sus propias fuentes de datos, que pueden estar sesgadas, por ejemplo, por la demografía de los pacientes, los instrumentos utilizados o las especializaciones clínicas. O han necesitado agrupar datos de otras instituciones para recopilar toda la información que necesitan.
El aprendizaje federado hace posible que los algoritmos de IA obtengan experiencia a partir de una amplia gama de datos ubicados en diferentes sitios.
El enfoque permite que varias organizaciones colaboren en el desarrollo de modelos, pero sin necesidad de compartir directamente datos clínicos confidenciales entre sí.
En el transcurso de varias iteraciones de capacitación, los modelos compartidos se exponen a una gama de datos significativamente más amplia que la que posee cualquier organización internamente.
Cómo Funciona el Aprendizaje Federado
En definitiva, los algoritmos de IA implementados en escenarios médicos deben alcanzar una precisión de grado clínico. En términos generales, esto significa que cumplen o superan el estándar de oro para la aplicación en la que se utilizan.
Para ser considerado un experto en un campo médico en particular, generalmente necesitas haber trabajado 15 años en el puesto. Un experto de este nivel probablemente haya leído alrededor de 15,000 casos en un año, lo que suma alrededor de 225,000 a lo largo de su carrera.
Cuando se consideran las enfermedades raras, que afectan a una de cada 2,000 personas, incluso un experto con tres décadas de experiencia solo habrá visto aproximadamente 100 casos de una afección en particular.
Para entrenar modelos que cumplan con el mismo grado que los expertos médicos, los algoritmos de IA deben alimentarse con una gran cantidad de casos. Y estos ejemplos deben representar suficientemente el entorno clínico en el que se utilizarán.
Pero, actualmente, el mayor conjunto de datos abiertos contiene 100,000 casos.
Y no es solo la cantidad de datos lo que cuenta. También debe ser muy diverso e incorporar muestras de pacientes de diferentes géneros, edades, datos demográficos y exposiciones ambientales.
Los institutos de salud individuales pueden tener archivos que contienen cientos de miles de registros e imágenes, pero estas fuentes de datos generalmente se mantienen aisladas. Esto se debe, en gran parte, a que los datos de salud son privados y no pueden utilizarse sin el consentimiento del paciente y la aprobación ética necesarios.
El aprendizaje federado descentraliza el deep learning, dado que elimina la necesidad de agrupar datos en una sola ubicación. En cambio, el modelo se entrena en múltiples iteraciones y en diferentes sitios.
Por ejemplo, digamos que tres hospitales deciden unirse y desarrollar un modelo para ayudar a analizar automáticamente las imágenes de tumores cerebrales.
Si optaban por trabajar con un enfoque federado cliente-servidor, un servidor centralizado mantendría la red neuronal profunda global y cada hospital participante recibiría una copia para entrenar en su propio conjunto de datos.
Una vez que el modelo había sido entrenado localmente para un par de iteraciones, los participantes enviarían su versión actualizada del modelo al servidor centralizado y mantendrían su conjunto de datos dentro de su propia infraestructura segura.
El servidor central luego agregarían las contribuciones de todos los participantes. Los parámetros actualizados luego se compartirían con los institutos participantes, para que puedan continuar con el entrenamiento local.
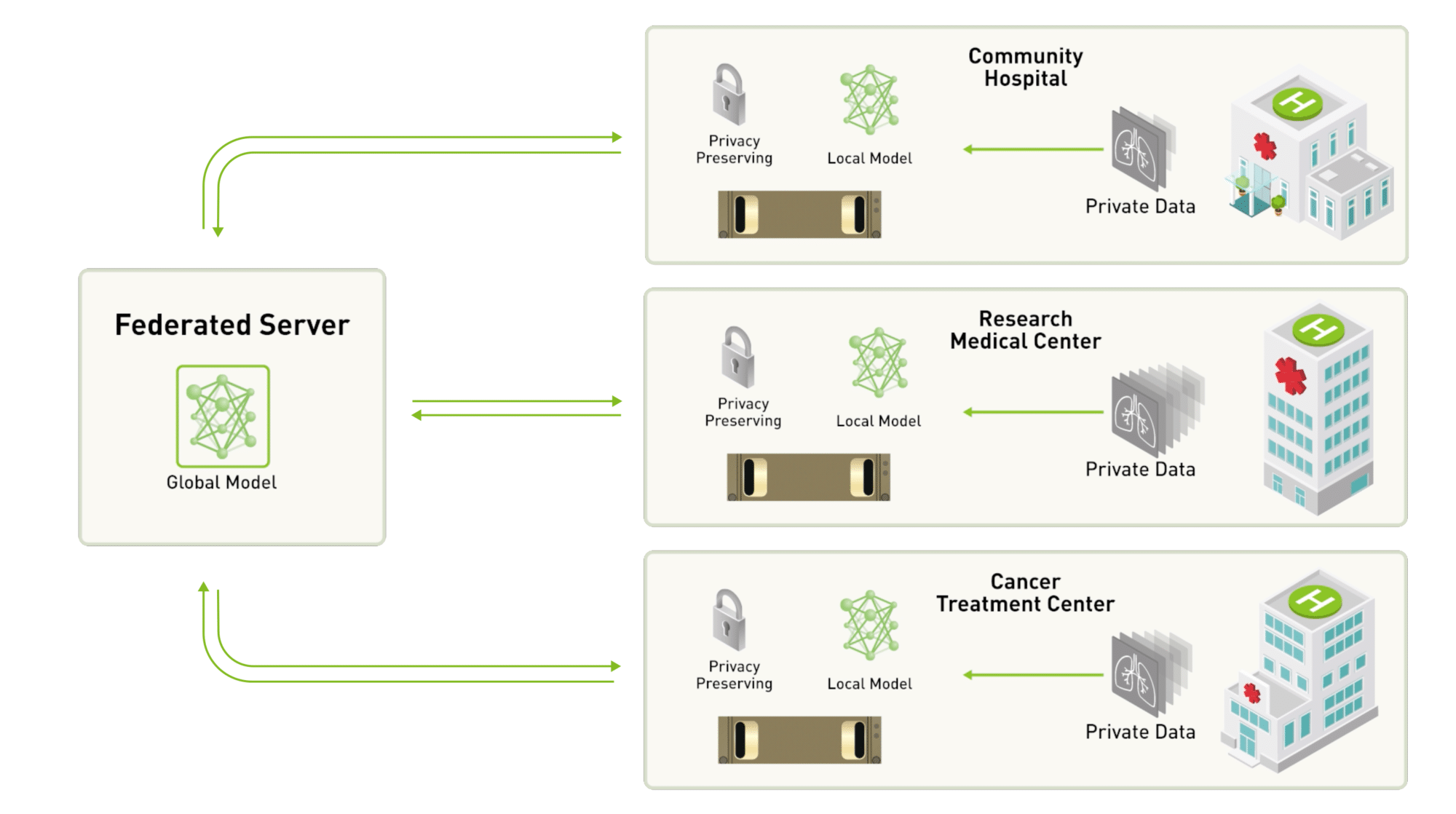
Si uno de los hospitales decidiera que quería dejar el equipo de entrenamiento, esto no detendría el entrenamiento del modelo, ya que no depende de ningún dato específico. Del mismo modo, un nuevo hospital podría optar por unirse a la iniciativa en cualquier momento.
Este es solo uno de los muchos enfoques para el aprendizaje federado. El denominador común de todos los enfoques es que cada participante obtiene conocimiento global a partir de datos locales: todos ganan.
¿Por qué el Aprendizaje Federado?
El aprendizaje federado aún requiere una implementación cuidadosa para garantizar que los datos del paciente se mantengan seguros. Sin embargo, tiene el potencial de abordar algunos de los desafíos que enfrentan los enfoques que requieren la combinación de datos clínicos confidenciales.
Para el aprendizaje federado, los datos clínicos no necesitan tomarse fuera de las propias medidas de seguridad de una institución. Cada participante mantiene el control de sus propios datos clínicos.
Como esto dificulta la extracción de información confidencial del paciente, el aprendizaje federado permite que los equipos desarrollen conjuntos de datos más grandes y diversos para entrenar sus algoritmos de IA.
La implementación de un enfoque de aprendizaje federado también alienta a diferentes hospitales, instituciones de salud y centros de investigación a colaborar en la construcción de un modelo que pueda beneficiarlos a todos.
Cómo el Aprendizaje Federado Puede Transformar la Atención de la Salud
El aprendizaje federado podría revolucionar la forma en que se entrenan los modelos de IA. Además, los beneficios también llegarán al ecosistema de atención de la salud más amplio.
Las redes hospitalarias más grandes podrían trabajar mejor juntas y beneficiarse del acceso a datos seguros e interinstitucionales. Al mismo tiempo, los hospitales rurales y comunitarios más pequeños disfrutarían de acceso a algoritmos de IA de nivel experto.
Podría llevar la IA al punto de atención, lo que permite que grandes volúmenes de datos diversos de diferentes organizaciones se incluyan en el desarrollo del modelo, al tiempo que cumple con la gobernanza local de los datos clínicos.
Los médicos tendrían acceso a algoritmos de IA más robustos, basados en datos que representan un grupo demográfico más amplio de pacientes para un área clínica en particular o de casos raros con los que no se habrían encontrado localmente. También podrían contribuir al entrenamiento continuo de estos algoritmos siempre que no estuvieran de acuerdo con los resultados.
Las nuevas empresas de atención de la salud podrían lanzar innovaciones de vanguardia al mercado más rápido, gracias a un enfoque seguro para aprender de algoritmos más diversos.
Mientras tanto, las instituciones de investigación podrían orientar su trabajo hacia las necesidades clínicas reales, basándose en una amplia variedad de datos del mundo real, en lugar del suministro limitado de conjuntos de datos abiertos.
Desarrollado por la Atención de la Salud para la Atención de la Salud
Ahora, se están llevando a cabo proyectos de aprendizaje federado a gran escala, destinados a mejorar el descubrimiento de fármacos y llevar los beneficios de la IA al punto de atención.
MELLODDY, un consorcio de descubrimiento de fármacos con sede en el Reino Unido, está trabajando para demostrar cómo las técnicas de aprendizaje federado podrían brindar a los socios farmacéuticos lo mejor de ambos mundos: la capacidad de aprovechar el conjunto de datos de compuestos de fármacos colaborativos más grande del mundo para realizar el entrenamiento de IA sin sacrificar la privacidad de los datos.
El King’s College de Londres espera que su trabajo con el aprendizaje federado, como parte del proyecto de Atención de la Salud Basada en el Valor del Centro de Inteligencia Artificial e Imágenes Médicas de Londres, pueda lograr avances en la clasificación de accidentes cerebrovasculares y deficiencias neurológicas, determinar las causas subyacentes de los cánceres y recomendar el mejor tratamiento para los pacientes.
Obtén más información sobre el aprendizaje federado. Obtén más información sobre la ciencia detrás de este enfoque en este documento.