
Los datos son el nuevo petróleo en la era actual de la IA, pero solo unos pocos afortunados están sentados en un chorro. Por lo tanto, muchos están haciendo su propio combustible, uno que es barato y eficaz. Se llama datos sintéticos.
¿Qué Son los Datos Sintéticos?
Los datos sintéticos son información anotada que las simulaciones por computadora o los algoritmos generan como alternativa a los datos del mundo real.
Dicho de otra manera, los datos sintéticos se crean en mundos digitales en lugar de recopilarse o medirse en el mundo real.
Puede ser artificial, pero los datos sintéticos reflejan datos del mundo real, matemática o estadísticamente. La investigación demuestra que puede ser tan bueno o incluso mejor para entrenar un modelo de IA que los datos basados en objetos, eventos o personas reales.

Es por eso que los desarrolladores de redes neuronales profundas utilizan cada vez más datos sintéticos para entrenar sus modelos. De hecho, una investigación de 2019 sobre el terreno llama al uso de datos sintéticos «una de las técnicas generales más prometedoras en aumento en el deep learning moderno, especialmente la visión por computadora» que se basa en datos no estructurados como imágenes y video.
El informe de 156 páginas de Sergey I. Nikolenko del Instituto Steklov de Matemáticas en San Petersburgo, Rusia, cita 719 artículos sobre datos sintéticos. Nikolenko concluye que «los datos sintéticos son esenciales para un mayor desarrollo del deep learning… [y] aún quedan muchos más casos de uso potenciales» por descubrir.
El aumento de los datos sintéticos se produce cuando el pionero de la IA Andrew Ng está pidiendo un cambio amplio hacia un enfoque más centrado en los datos para el machine learning. Está reuniendo apoyo para un punto de referencia o competencia sobre la calidad de los datos que muchos afirman que representa el 80 por ciento del trabajo en IA.
«La mayoría de los puntos de referencia proporcionan un conjunto fijo de datos e invitan a los investigadores a iterar en el código… tal vez sea hora de mantener el código fijo e invitar a los investigadores a mejorar los datos», escribió en su boletín, The Batch.
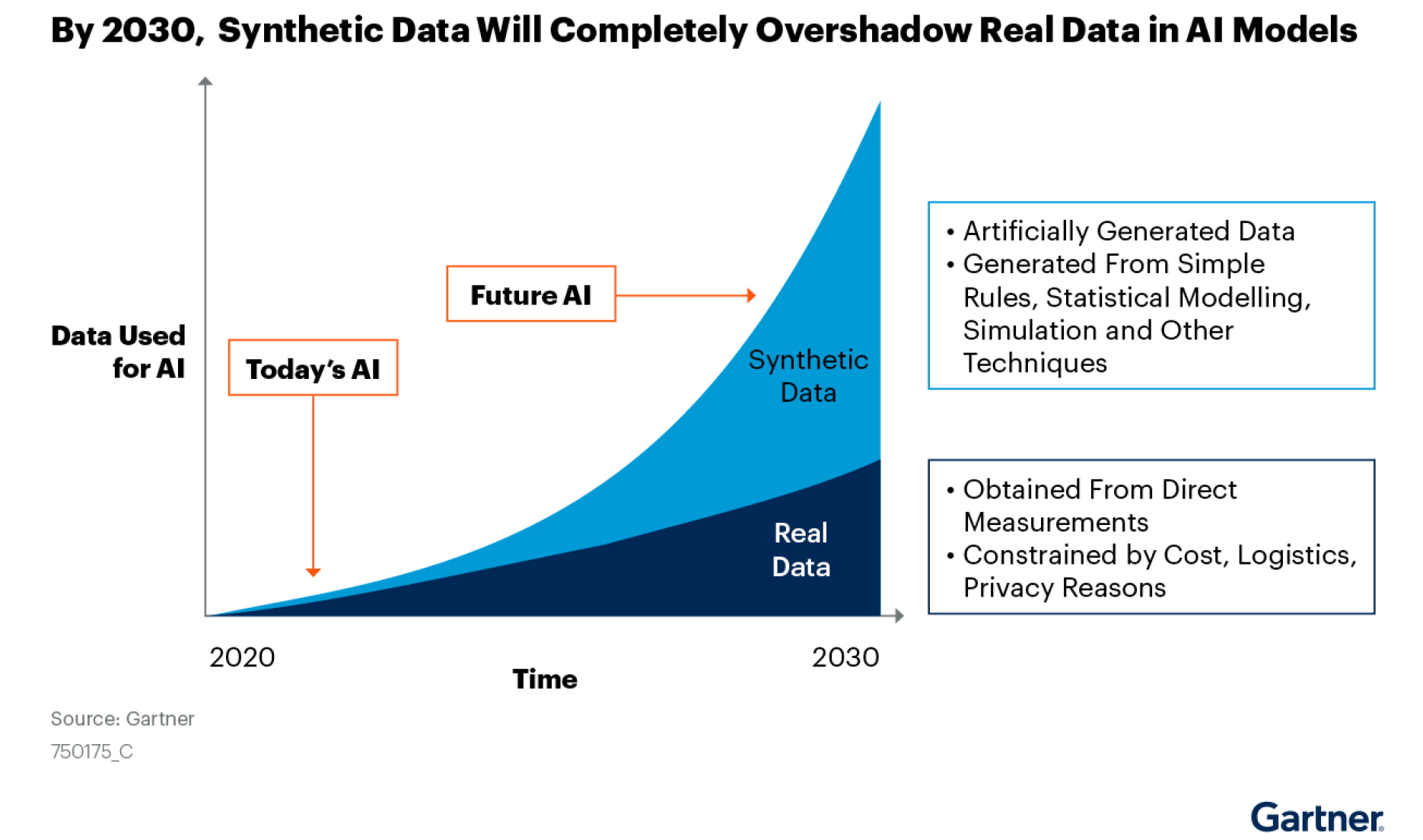
En un informe de junio de 2021 sobre datos sintéticos, Gartner predijo que para 2030 la mayoría de los datos utilizados en IA se generarán artificialmente mediante reglas, modelos estadísticos, simulaciones u otras técnicas.
«El hecho es que no podrá construir modelos de inteligencia artificial de alta calidad y alto valor sin datos sintéticos», dice el informe.
Datos Aumentados y Anonimizados Frente a Datos Sintéticos
La mayoría de los desarrolladores ya están familiarizados con el aumento de datos, una técnica que implica agregar nuevos datos a un conjunto de datos del mundo real existente. Por ejemplo, podrían rotar o iluminar una imagen existente para crear una nueva.
Dadas las preocupaciones y las políticas gubernamentales sobre la privacidad, eliminar información personal de un conjunto de datos es una práctica cada vez más común. Esto se llama anonimización de datos, y es especialmente popular para el texto, un tipo de datos estructurados utilizados en industrias como las finanzas y la area de la salud.
Los datos aumentados y anonimizados no suelen considerarse datos sintéticos. Sin embargo, es posible crear datos sintéticos mediante estas técnicas. Por ejemplo, los desarrolladores podrían combinar dos imágenes de coches del mundo real para crear una nueva imagen sintética con dos coches.
¿Por Qué Son Tan Importantes los Datos Sintéticos?
Los desarrolladores necesitan conjuntos de datos grandes y cuidadosamente etiquetados para entrenar redes neuronales. Los datos de entrenamiento más diversos generalmente hacen que los modelos de IA sean más precisos.
El problema es que la recopilación y el etiquetado de conjuntos de datos que pueden contener entre unos pocos miles y decenas de millones de elementos consume mucho tiempo y, a menudo, es prohibitivamente caro.
Introduzca datos sintéticos. Una sola imagen que podría costar 6 dólares de un servicio de etiquetado se puede generar artificialmente por seis centavos, estima Paul Walborsky, quien cofundó uno de los primeros servicios de datos sintéticos dedicados, la AI.Reverie.
El ahorro de costes es solo el comienzo. «Los datos sintéticos son clave para lidiar con los problemas de privacidad y reducir el sesgo al garantizar que tenga la diversidad de datos para representar el mundo real», agregó Walborsky.
Dado que los conjuntos de datos sintéticos se etiquetan automáticamente y pueden incluir deliberadamente casos de esquina raros pero cruciales, a veces es mejor que los datos del mundo real.
¿Cuál es el Historial de los Datos Sintéticos?
Los datos sintéticos han existido de una forma u otra durante décadas. Está en juegos de ordenador como simuladores de vuelo y simulaciones científicas de todo, desde átomos hasta galaxias.
Donald B. Rubin, un profesor de estadística de Harvard, estaba ayudando a las ramas del gobierno de Estados Unidos a resolver problemas como un recuento insuficiente, especialmente de personas pobres en un censo, cuando se le dio una idea. Lo describió en un artículo de 1993 a menudo citado como el nacimiento de datos sintéticos.
«Utilicé el término datos sintéticos en ese documento refiriéndose a múltiples conjuntos de datos simulados», explicó Rubin.
«Cada uno parece que podría haber sido creado por el mismo proceso que creó el conjunto de datos real, pero ninguno de los conjuntos de datos revela datos reales, esto tiene una enorme ventaja al estudiar conjuntos de datos personales y confidenciales», agregó.

A raíz del Big Bang de la IA, la competencia ImageNet de 2012, cuando una red neuronal reconoció objetos más rápido de lo que un humano podría, los investigadores comenzaron a buscar en serio datos sintéticos.
En pocos años, «los investigadores estaban usando imágenes renderizadas en experimentos, y estaba rindiendo los frutos suficientes como para que la gente comenzara a invertir en productos y herramientas para generar datos con sus motores 3D y pipelines de contenido», dijo Gavriel State, director senior de tecnología de simulación e IA en NVIDIA.
Ford y BMW Generan Datos Sintéticos
Bancos, fabricantes de automóviles, drones, fábricas, hospitales, minoristas, robots y científicos utilizan datos sintéticos hoy en día.
En un podcast reciente, los investigadores de Ford describieron cómo combinan motores de juego y redes adversariales generativas (GANs) para crear datos sintéticos para el entrenamiento de IA.
Para optimizar el proceso de cómo fabrica automóviles, BMW creó una fábrica virtual utilizando NVIDIA Omniverse, una plataforma de simulación que permite a las empresas colaborar utilizando múltiples herramientas. Los datos que BMW genera ayudan a afinar cómo los trabajadores de ensamblaje y los robots trabajan juntos para construir automóviles de manera eficiente.
Datos Sintéticos en el Hospital, el Banco y la Tienda
Los proveedores de la area de la salud en campos como las imágenes médicas utilizan datos sintéticos para entrenar modelos de IA al tiempo que protegen la privacidad del paciente. Por ejemplo, la startup Curai entrenó un modelo de diagnóstico en 400.000 casos médicos simulados.
«Arquitecturas basadas en GAN para imágenes médicas, ya sea generando datos sintéticos [o] adaptando datos reales de otros dominios… definirá el estado del arte en el campo en los próximos años», dijo Nikolenko en su encuesta de 2019.
Los GANs también están recibiendo tracción en las finanzas. American Express estudió formas de usar GANs para crear datos sintéticos, refinando sus modelos de IA que detectan fraudes.
En las ventas minoristas, empresas como la startup Caper utilizan simulaciones 3D para tomar tan solo cinco imágenes de un producto y crear un conjunto de datos sintético de mil imágenes. Estos conjuntos de datos permiten tiendas inteligentes donde los clientes captan lo que necesitan y se van sin esperar en una línea de pago.
¿Cómo se Crean Datos Sintéticos?
«Hay un bazillion técnicas por ahí» para generar datos sintéticos, dijo State de NVIDIA. Por ejemplo, los autoencoders variacionales comprimen un conjunto de datos para hacerlo compacto y, a continuación, utilizan un descodificador para generar un conjunto de datos sintético relacionado.
Mientras que los GANs están en aumento, especialmente en la investigación, las simulaciones siguen siendo una opción popular por dos razones. Admiten una gran cantidad de herramientas para segmentar y clasificar imágenes fijas y en movimiento, generando etiquetas perfectas. Y pueden generar rápidamente versiones de objetos y entornos con diferentes colores, iluminación, materiales y poses.
Esta última capacidad ofrece los datos sintéticos que son cruciales para la aleatorización de dominios, una técnica cada vez más utilizada para mejorar la precisión de los modelos de IA.
Consejo Profesional: Usar la Aleatorización de Dominios
La aleatorización de dominios utiliza miles de variaciones de un objeto y su entorno para que un modelo de IA pueda comprender más fácilmente el patrón general. El siguiente video muestra cómo un almacén inteligente utiliza la aleatorización de dominios para entrenar a un robot impulsado por IA.
La aleatorización de dominios ayuda a cerrar la llamada brecha de dominio: el espacio corto de las predicciones perfectas que un modelo de IA haría si se entrenara sobre la situación exacta que encuentra en un día determinado. Es por eso que NVIDIA está construyendo la aleatorización de dominios para herramientas de generación de datos sintéticos en Omniverse, una parte del trabajo descrito en una charla reciente en GTC.
Estas técnicas están ayudando a las aplicaciones de visión artificial a pasar de la detección y clasificación de objetos en imágenes a ver y comprender actividades en videos.
«El mercado se está moviendo en esta dirección, pero la tecnología es más compleja. Los datos sintéticos son aún más valiosos aquí porque te permiten crear fotogramas de video completamente anotados», dijo Walborsky de AI.Reverie.
¿Dónde Puedo Obtener Datos Sintéticos?
Aunque el sector tiene solo unos pocos años, más de 50 empresas ya proporcionan datos sintéticos. Cada uno tiene su propia salsa especial, a menudo un enfoque en un mercado vertical o técnica en particular.
Por ejemplo, un puñado se especializa en usos de la area de la salud. Media docena ofrece herramientas o conjuntos de datos de código abierto, incluida la Bóveda de Datos Sintética, un conjunto de bibliotecas, proyectos y tutoriales desarrollados en el MIT.
NVIDIA tiene como objetivo trabajar con una amplia gama de datos sintéticos y servicios de etiquetado de datos. Entre sus últimos socios:
- AI.Reverie. en Nueva York ofrece entornos de simulación con sensores configurables que permiten a los usuarios recopilar sus propios conjuntos de datos, y ha trabajado en proyectos a gran escala en áreas como la agricultura, las ciudades inteligentes, la seguridad y la manifactura.
- Sky Engine, con sede en Londres, trabaja en aplicaciones de visión artificial en todos los mercados y puede ayudar a los usuarios a diseñar su propio workflow de ciencia de datos.
- Datagen, con sede en Israel, crea conjuntos de datos sintéticos a partir de simulaciones para una amplia gama de mercados, incluidas tiendas inteligentes, robótica e interiores para automóviles y edificios.
- CVEDIA incluye a Airbus, Honeywell y Siemens entre los usuarios de sus herramientas personalizables para visión artificial basada en datos sintéticos.
Habilitación de un Marketplace con Omniverse
Con Omniverse, NVIDIA tiene como objetivo permitir una galaxia en expansión de diseñadores y programadores interesados en construir o colaborar en mundos virtuales en todas las industrias. La generación de datos sintéticos es uno de los muchos negocios que la compañía espera que vivan allí.
NVIDIA creó Isaac Sim como una aplicación en Omniverse para robótica. Los usuarios pueden entrenar robots en este mundo virtual con datos sintéticos y aleatorización de dominios e implementar el software resultante en robots que trabajan en el mundo real.
Omniverse admite múltiples aplicaciones para mercados verticales como NVIDIA DRIVE Sim para vehículos autónomos. Ha estado permitiendo a los desarrolladores probar vehículos autónomos con la seguridad de una simulación realista, generando conjuntos de datos útiles incluso en medio de la pandemia.
Estas aplicaciones se encuentran entre los últimos ejemplos de cómo las simulaciones están cumpliendo la promesa de los datos sintéticos para la IA.
Más Información sobre los Datos Sintéticos
Para obtener más información sobre los datos sintéticos, consulte estos recursos:
- Un eBook de O’Reilly y NVIDIA sobre el uso de datos sintéticos en IA
- Una charla sobre datos sintéticos en GTC 2019 a cargo de Rev Lebaredian, vicepresidente de tecnología de simulación en NVIDIA (se requiere registro gratuito)
- Cuatro blogs de desarrolladores de NVIDIA publicados en 2021 sobre datos sintéticos.
- Una presentación en GTC 2021 por Scotiabank y la Universidad de Alberta sobre la investigación utilizando modelos generativos para crear datos sintéticos (Se requiere registro gratuito)
- Ejemplos con muetras de código para la generación de datos sintéticos en Omniverse