
Ya sea que trabajes en las instalaciones o en la nube, los microservicios de inferencia de NVIDIA NIM brindan a los desarrolladores empresariales modelos de IA optimizados fáciles de implementar de la comunidad, los socios y NVIDIA. Como parte de NVIDIA AI Enterprise, NIM ofrece un camino seguro y optimizado para iterar rápidamente y crear innovaciones para soluciones de IA generativa de clase mundial.
Con un solo contenedor optimizado, puede implementar fácilmente un microservicio NIM en menos de 5 minutos en sistemas acelerados con GPU NVIDIA en la nube o en un data center, o en workstations y PC. De manera alternativa, si desea evitar la implementación de un contenedor, puede comenzar a crear prototipos de sus aplicaciones con las API de NIM del Catálogo de API de NVIDIA.
- Utilice contenedores prediseñados que se implementen con un solo comando en la infraestructura acelerada de NVIDIA en cualquier lugar.
- Mantenga la seguridad y el control de sus datos, su recurso empresarial más valioso.
- Logre la mejor precisión con soporte para modelos que se han ajustado con técnicas como LoRA.
- Integre puntos de conexión de inferencia de IA acelerada aprovechando las API coherentes y estándar de la industria.
- Trabaje con los marcos de aplicaciones de IA generativa más populares, como LangChain, LlamaIndex y Haystack.
Esta publicación explica una implementación simple de NVIDIA NIM. Podrá utilizar las API de microservicios de NIM en los frameworks de aplicaciones de IA generativa más populares, como Hugging Face, Haystack, LangChain y LlamaIndex. Para obtener una guía completa sobre la implementación de NIM, consulte la Documentación de NVIDIA NIM.
Cómo Implementar NIM en 5 Minutos
Necesita una licencia NVIDIA AI Enterprise o una membresía del Programa para Desarrolladores de NVIDIA para implementar NIM. La forma más rápida de obtener cualquiera de las dos es visitar el Catálogo de API de NVIDIA y elegir Get API key desde una página de modelo, por ejemplo, Llama 3.1 405B. Luego, ingrese su dirección de correo electrónico comercial para acceder a NIM con una licencia NVIDIA AI Enterprise de 90 días o su dirección de correo electrónico personal para acceder a NIM a través de la membresía del Programa para Desarrolladores de NVIDIA.
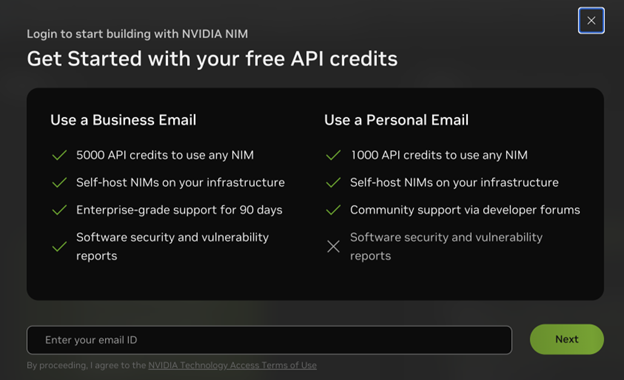
A continuación, asegúrese de configurar y seguir todas las instrucciones de los requisitos previos. Si copió su clave API en el flujo de inicio de sesión, puede omitir el paso para generar una clave API adicional según las instrucciones.
Cuando tenga todo configurado, ejecute el siguiente script:
# Elija un nombre de contenedor para bookkeepingexport CONTAINER_NAME=llama3-8b-instruct# Defina el nombre del proveedor para el LLMexport VENDOR_NAME=meta# Elija una imagen LLM NIM de NGCexport IMG_NAME="nvcr.io/nim/{VENDOR_NAME}/${CONTAINER_NAME}:1.0.0"# Elija una ruta en su sistema para almacenar en caché los modelos descargadosexport LOCAL_NIM_CACHE="~/.cache/nim"mkdir -p "$LOCAL_NIM_CACHE"# Inicia el LLM NIMdocker run -it --rm --name=$CONTAINER_NAME \ --runtime=nvidia \ --gpus all \ -e NGC_API_KEY \ -v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \ -u $(id -u) \ -p 8000:8000 \ $IMG_NAME |
A continuación, pruebe una solicitud de inferencia:
curl -X 'POST' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "meta/llama3-8b-instruct", "prompt": "Once upon a time", "max_tokens": 64 }' |
Ahora dispone de una implementación de producción controlada y optimizada para crear aplicaciones de IA generativa de forma segura. Las implementaciones de NIM alojadas en NVIDIA también están disponibles en el Catálogo de API de NVIDIA.
A medida que se lanza una nueva versión de NIM, la documentación más actualizada siempre está en NVIDIA NIM Large Language Models.
Cómo Integrar NIM Con Sus Aplicaciones
Si bien la configuración debe completarse primero, si desea probar NIM sin implementarlo por su cuenta, puede hacerlo utilizando los puntos de conexión de API alojados por NVIDIA en el Catálogo de API de NVIDIA:
- Integración de puntos de conexión de NIM
- Integración de puntos de conexión Hugging Face de NIM
Integración de Puntos de Conexión NIM
Puede comenzar con una solicitud curl de finalizaciones que siga la especificación de OpenAI. Tenga en cuenta que para transmitir salidas, debe establecer stream en True. Al usar Python con la biblioteca OpenAI, no es necesario proporcionar una clave API si se utiliza un microservicio NIM.
Asegúrese de actualizar el valor base_url en el lugar donde se esté ejecutando el microservicio NIM.
from openai import OpenAIclient = OpenAI( api_key="no-key-required")completion = client.chat.completions.create( model="meta/llama3-8b-instruct", messages=[{"role":"user","content":"What is a GPU?"}] temperature=0.5, top_p=1, max_tokens=1024, stream=True)for chunk in completion: if chunk.choices[0].delta.content is not None: print(chunk.choices[0].delta.content, end="")NIM también está integrado en frameworks de aplicaciones como Haystack, LangChain y LlamaIndex, lo que brinda una inferencia de modelos segura, confiable y acelerada a los desarrolladores que ya están creando increíbles aplicaciones de IA generativa con estas herramientas populares.
Para usar microservicios NIM en Python con LangChain, use el siguiente ejemplo de código:
from langchain_nvidia_ai_endpoints import ChatNVIDIAllm = ChatNVIDIA(base_url="http://0.0.0.0:8000/v1", model="meta/llama3-8b-instruct", temperature=0.5, max_tokens=1024, top_p=1) result = llm.invoke("What is a GPU?")print(result.content)Para obtener más información sobre cómo usar NIM, consulte los siguientes cuadernos de notas del framework de trabajo:
- Pipeline Haystack RAG con modelos de IA autoimplementados y NVIDIA NIM
- Agente LangChain RAG con NVIDIA NIM
- Pipeline LlamaIndex RAG con NVIDIA NIM
Echa un vistazo a los blocs de notas de cada uno de estos marcos para aprender a usar NIM:
Integración de Puntos de Conexción de Hugging Face de NIM
También puede integrar una conexión de NIM dedicada directamente en Hugging Face. Hugging Face activa instancias en su nube preferida, implementa el modelo optimizado por NVIDIA y le permite iniciar la inferencia con solo unos pocos clics. Navegue a la página del modelo en Hugging Face y cree un punto final dedicado directamente con su CSP preferido. Para obtener más información y una guía paso a paso, consulte NVIDIA Collaborates with Hugging Face to Simplify Generative AI Model Deployments.
Obtenga Más de NIM
Con una implementación de modelos rápida, confiable y simple con NVIDIA NIM, puede concentrarse en crea workflows y aplicaciones de IA generativa innovadoras y de alto rendimiento.
Personalice NIM con LoRA
Para obtener aún más de NIM, aprenda a usar los microservicios con LLM personalizados con adaptadores LoRA. NIM admite adaptadores LoRA entrenados con HuggingFace o NVIDIA NeMo. Almacene los adaptadores LoRA en /LOCAL_PEFT_DIRECTORY y preséntelos con un script similar al que se usa para el contenedor base.
# Elija un nombre de contenedor para bookkeepingexport CONTAINER_NAME=llama3-8b-instruct# Defina el nombre del proveedor para el LLMexport VENDOR_NAME=meta# Elija una imagen LLM NIM de NGCexport IMG_NAME="nvcr.io/nim/${VENDOR_NAME}/${CONTAINER_NAME}:1.0.0"Elija una imagen LLM NIM de NGC# Choose a LLM NIM image from NGCexport LOCAL_PEFT_DIRECTORY=~/loras# Descargue el formato NeMo lora. También puede descargar el formato PEFT lora HuggingFacengc registry model download-version "nim/meta/llama3-70b-instruct-lora:nemo-math-v1"# Inicia el microservicio LLM NIMdocker run -it --rm --name=$CONTAINER_NAME \ --runtime=nvidia \ --gpus all \ -e NGC_API_KEY \ -e NIM_PEFT_SOURCE \ -v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \ -v $LOCAL_PEFT_DIRECTORY:$NIM_PEFT_SOURCE \ -u $(id -u) \ -p 8000:8000 \ $IMG_NAME |
Luego puede implementar usando el nombre de uno de los adaptadores LoRA en /LOCAL_PEFT_DIRECTORY.
curl -X 'POST' \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{"model": "llama3-8b-instruct-lora_vhf-math-v1","prompt": "John buys 10 packs of magic cards. Each pack has 20 cards and 1/4 of those cards are uncommon. How many uncommon cards did he get?","max_tokens": 128}' |
Para obtener más información sobre LoRA, consulte Seamlessly Deploying a Swarm of LoRA Adapters with NVIDIA NIM.
Los microservicios NIM se lanzan y mejoran periódicamente. Para ver los últimos microservicios NVIDIA NIM para visión, recuperación, 3D, biología digital y más, consulte el Catálogo de API de NVIDIA.