
La inteligencia artificial es el futuro. La inteligencia artificial es ciencia ficción. La inteligencia artificial ya forma parte de nuestra vida diaria. Todas esas afirmaciones son ciertas, solo depende a qué tipo de IA te refieres.
Por ejemplo, cuando el programa AlphaGo de Google DeepMind derrotó al maestro surcoreano Lee Se-dol en el juego de mesa Go a principios de este año, se usaron los términos IA, machine learning y deep learning en los medios para describir cómo ganó DeepMind. Y los tres son parte de la razón por la que AlphaGo derrotó a Lee Se-Dol. Pero no son las mismas cosas.
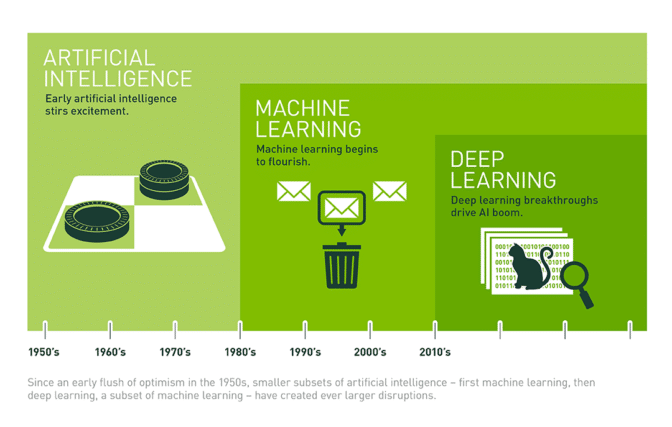
La forma más fácil de pensar en su relación es visualizarlos como círculos concéntricos con IA, la idea que surgió primero, como el más grande. Luego, aparece machine learning, que floreció más tarde y, finalmente, deep learning, que está impulsando la explosión de la IA actual y se incluye en ambos.
 Del Fracaso al Éxito
Del Fracaso al Éxito
La IA ha sido parte de nuestra imaginación y ha estado evolucionando lentamente en los laboratorios de investigación desde que un puñado de informáticos crearon el término en las Conferencias de Dartmouth de 1956 y dio origen al campo de la IA. Desde entonces, en las décadas siguientes, la IA ha sido alternativamente anunciada como la clave para alcanzar el futuro más brillante de nuestra civilización y desechada como una noción descabellada de delirantes exagerados. Francamente, hasta 2012, fue ambas cosas.
En los últimos años, la IA se ha disparado y, especialmente, desde 2015. Mucho de eso tiene que ver con la amplia disponibilidad de las GPU que hacen que el procesamiento paralelo sea cada vez más rápido, económico y potente. También tiene que ver con la combinación de un almacenamiento prácticamente infinito y una avalancha de datos de todo tipo (gracias al movimiento de Big Data): imágenes, texto, transacciones, datos de mapas, lo que sea.
Veamos cómo los científicos de la computación han pasado de una especie de fracaso, hasta un éxito en 2012, que ha desatado aplicaciones utilizadas por cientos de millones de personas todos los días.
Inteligencia Artificial: Inteligencia Humana Exhibida por Máquinas

El sueño de los pioneros que asistieron a esa conferencia del verano de 1956 era construir máquinas complejas (gracias a las computadoras que recién aparecían) que tuvieran las mismas características que la inteligencia humana. Este es el concepto que consideramos “IA general”: máquinas fabulosas que tienen todos nuestros sentidos (tal vez incluso más), toda nuestra razón y piensan igual que nosotros. Has visto estas máquinas sin cesar en películas como amigos, C-3PO, y enemigos, Terminator. Las máquinas de IA generales se han mantenido en las películas y novelas de ciencia ficción por una buena razón; no podemos lograr que sean una realidad, al menos no todavía.
Lo que podemos hacer cae en el concepto de “IA estrecha”. Tecnologías que son capaces de realizar tareas específicas igual o mejor que los humanos. Los ejemplos de IA estrecha son cosas como la clasificación de imágenes en un servicio como Pinterest y el reconocimiento facial en Facebook.
Esos son ejemplos de la IA estrecha en la práctica. Estas tecnologías exhiben algunas facetas de la inteligencia humana. ¿Pero cómo? ¿De dónde proviene esa inteligencia? Eso nos lleva al siguiente círculo, machine learning.
Machine Learning: Un Enfoque para Alcanzar la Inteligencia Artificial
Machine learning, en su forma más básica, es la práctica de usar algoritmos para analizar datos, aprender de ellos y, luego, hacer una determinación o predicción sobre algo en el mundo. Entonces, en lugar de codificar manualmente rutinas de software con un conjunto específico de instrucciones para realizar una tarea en particular, la máquina se “entrena” utilizando grandes cantidades de datos y algoritmos que le dan la capacidad de aprender a realizar la tarea.
Machine learning provino directamente de las mentes de la primera multitud de IA. A largo de los años, los enfoques algorítmicos incluyeron el aprendizaje del árbol de decisiones y la programación lógica inductiva, el agrupamiento, el aprendizaje reforzado y las redes bayesianas, entre otros. Como sabemos, ninguno logró el objetivo final de la IA general. Incluso la IA estrecha estaba fuera del alcance de los primeros enfoques de machine learning.
Al final resultó que, una de las mejores áreas de aplicación para machine learning durante muchos años fue la visión de computación, aunque todavía requería una gran cantidad de codificación manual para hacer el trabajo. La gente escribía clasificadores codificados a mano, como filtros de detección de bordes para que el programa pudiera identificar dónde comenzaba y terminaba un objeto, un filtro detección de formas para determinar si el objeto tenía ocho lados o un clasificador para reconocer las letras “A-L-T-O”. A partir de todos esos clasificadores codificados a mano, se desarrollarían algoritmos para dar sentido a la imagen y que “aprenderían” a determinar si era una señal de alto.
Algo bueno, pero no increíblemente genial. En especial, en un día con niebla, cuando el letrero no es perfectamente visible o un árbol oculta parte de él. Hay una razón por la que la visión de computación y la detección de imágenes no se acercaron a un nivel similar al de los humanos hasta hace muy poco: era demasiado frágil y propensa a errores.
El tiempo y los algoritmos de aprendizaje adecuados marcaron la diferencia.
Deep Learning: Una Técnica para Implementar Machine Learning

Las redes neuronales artificiales (otro enfoque algorítmico de la primera multitud del machine learning) aparecieron y desaparecieron a lo largo de las décadas. Las redes neuronales se inspiran en nuestra comprensión de la biología de nuestro cerebro, todas esas interconexiones entre las neuronas. Pero, a diferencia de un cerebro biológico, donde cualquier neurona puede conectarse a cualquier otra neurona dentro de una cierta distancia física, estas redes neuronales artificiales tienen direcciones de propagación de datos, conexiones y capas discretas.
Uno podría, por ejemplo, tomar una imagen y cortarla en un montón de mosaicos que se ingresan en la primera capa de la red neuronal. En la primera capa, los reciben neuronas individuales; luego los datos pasan a una segunda capa. La segunda capa de neuronas hace su tarea, y así sucesivamente, hasta la capa final, en donde se obtiene el resultado.
Cada neurona asigna un peso a su entrada con respecto a qué tan correcta o incorrecta es en relación con la tarea que se está realizando. Luego, el resultado final se determina por el total de esos pesos. Así que piensa en nuestro ejemplo de la señal de alto. Las neuronas cortan y “examinan” los atributos de la imagen de una señal de alto: la forma octogonal de la señal, su color rojo como el de un camión de bomberos, sus letras distintivas, el tamaño de la señal de tráfico y su movimiento o la ausencia de él. La tarea de la red neuronal es determinar si es una señal de alto o no. Genera un “vector de probabilidad”, una conjetura fundamentada y basada en los pesos, o ponderación. En nuestro ejemplo, el sistema podría tener un 86% de confianza en que la imagen es una señal de alto, un 7% de confianza en que es una señal de límite de velocidad, un 5% de que es una cometa atascada en un árbol y así sucesivamente. Luego, la arquitectura de la red le dice a la red neuronal si está bien o no.
Incluso este ejemplo se está adelantando a sí mismo, porque hasta hace poco las redes neuronales eran casi rechazadas por la comunidad de investigación de IA. Habían existido desde los primeros días de la IA y habían producido muy poco en cuanto a “inteligencia”. El problema era que incluso las redes neuronales más básicas requerían mucha potencia de computación, por lo que no era un enfoque práctico. Aun así, un pequeño y herético grupo de investigación dirigido por Geoffrey Hinton de la Universidad de Toronto siguió adelante y finalmente paralelizó los algoritmos para que las supercomputadoras se ejecutaran y así demostrar el concepto. Sin embargo, no fue hasta que se implementaron las GPU en el esfuerzo que se cumplió la promesa.
Si volvemos a nuestro ejemplo de la señal de alto, es muy probable que, a medida que la red se sintonice o “entrene”, devuelva respuestas incorrectas, muchas. Lo que necesita es el entrenamiento. Necesita ver cientos de miles, incluso millones de imágenes, hasta que las ponderaciones de las entradas de las neuronas se sintonicen con tanta precisión que obtenga la respuesta correcta prácticamente en todo momento: niebla o sin niebla, sol o lluvia. Es en ese momento que la red neuronal se ha enseñado a sí misma cómo se ve una señal de alto; o el rostro de tu madre, en el caso de Facebook; o un gato, que es lo que hizo Andrew Ng en 2012 en Google.
El gran avance de Ng fue tomar estas redes neuronales y, esencialmente, hacerlas enormes, aumentar las capas y las neuronas y luego ejecutar grandes cantidades de datos a través del sistema para entrenarlo. En el caso de Ng, eran imágenes de 10 millones de videos de YouTube. Ng puso le dio sentido al término “deep” (profundo) en deep learning, que describe todas las capas de estas redes neuronales.
Hoy en día, el reconocimiento de imágenes por máquinas entrenadas a través de deep learning en algunos escenarios es mejor que el de los humanos, y eso va desde gatos hasta la identificación de indicadores de cáncer en la sangre y tumores en resonancias magnéticas. AlphaGo de Google aprendió las reglas del juego Go y se entrenó para una partida partido Go (sintonizó su red neuronal) jugando contra sí mismo una y otra y otra vez..
Gracias al Deep Learning, la IA Tiene un Futuro Brillante
Deep learning ha permitido muchas aplicaciones prácticas de machine learning y, por extensión, el campo general de la IA. Deep learning desglosa las tareas de tal manera que hace que todo tipo de asistencia de máquinas parezca posible, incluso probable. Coches sin conductor, una mejor atención médica preventiva, mejores recomendaciones de películas, todo está al alcance en la actualidad o en el futuro. La IA es el presente y el futuro. Con la ayuda de deep learning, la IA puede incluso llegar a ese estado de ciencia ficción que imaginamos durante tanto tiempo. Si tienes un C-3PO, lo acepto. Puedes quedarte con Terminator.