
Para lograr una conversación de calidad entre un humano y una máquina, las respuestas deben ser rápidas, inteligentes y con un sonido natural.
Pero, hasta ahora, los desarrolladores de redes neuronales de procesamiento de idiomas que impulsan las aplicaciones de voz en tiempo real se han enfrentado a una compensación desafortunada: ser rápido y sacrificar la calidad de la respuesta, o crear una respuesta inteligente y tardar demasiado tiempo.
Eso es porque la conversación humana es increíblemente compleja. Cada declaración se basa en un contexto compartido y en interacciones previas. Los humanos hablan de maneras muy matizadas sin perder el ritmo, usando desde bromas internas hasta referencias culturales y juegos de palabras. Cada respuesta sigue a la última, casi instantáneamente. Los amigos anticipan lo que dirá el otro antes de que se pronuncien las palabras.
¿Qué es la IA Conversacional?
La verdadera IA conversacional es un asistente de voz que puede participar en diálogos similares a los humanos, capturando el contexto y proporcionando respuestas inteligentes. Estos modelos de IA deben ser masivos y muy complejos.
Pero cuanto más grande es un modelo, más largo es el lapso entre la pregunta de un usuario y la respuesta de la IA. Los espacios de más de tres décimas de segundo pueden parecer poco naturales.
Con las GPU NVIDIA, el software de IA conversacional y las bibliotecas de IA CUDA-X, los modelos de lenguaje masivos y de vanguardia se pueden entrenar y optimizar rápidamente para ejecutar inferencias en solo un par de milisegundos (milésimas de segundo) lo cual es una un gran paso hacia el fin de la compensación entre un modelo de IA que es rápido y uno que es grande y complejo.
Estos avances ayudan a los desarrolladores a construir e implementar las redes neuronales más avanzadas hasta el momento, y nos acercan al objetivo de lograr una IA verdaderamente conversacional.
Los modelos de comprensión de idiomas optimizados por GPU se pueden integrar en aplicaciones de inteligencia artificial para industrias como la area de la salud, las ventas minoristas y los servicios financieros, lo que proporciona a los asistentes de voz digitales avanzados en altavoces inteligentes y líneas de servicio al cliente. Estas herramientas de IA conversacional de alta calidad pueden permitir que las empresas de todos los sectores brinden un estándar de servicio personalizado previamente inalcanzable al interactuar con los clientes.
¿Qué Tan Rápida Debe Ser la IA Conversacional?
La brecha típica entre las respuestas en una conversación natural es de aproximadamente 300 milisegundos. Para que una IA reproduzca una interacción similar a la humana, es posible que tenga que ejecutar una docena o más de redes neuronales en secuencia como parte de una tarea de varias capas, todo dentro de esos 300 milisegundos o menos.
Responder a una pregunta implica varios pasos: convertir el habla de un usuario en texto, comprender el significado del texto, buscar la mejor respuesta para proporcionarla en contexto y proporcionar esa respuesta con una herramienta de conversión de texto a voz. Cada uno de estos pasos requiere ejecutar varios modelos de IA, por lo que el tiempo disponible para que se ejecute cada red individual es de alrededor de 10 milisegundos o menos.
Si cada modelo tarda más en ejecutarse, la respuesta es demasiado lenta y la conversación se vuelve discordante y antinatural.
Como trabajan con un tiempo de latencia tan acotado, los desarrolladores actuales de herramientas de comprensión de idiomas tienen que hacer concesiones. Un modelo complejo de alta calidad podría usarse como un chatbot, donde la latencia no es tan esencial como en una interfaz de voz. O los desarrolladores podrían confiar en un modelo de procesamiento de idiomas menos voluminoso que ofrezca resultados más rápidamente, pero carece de respuestas matizadas.
NVIDIA Riva es un framework de aplicaciones para desarrolladores que crean aplicaciones de IA conversacional de alta precisión que pueden ejecutarse muy por debajo del umbral de 300 milisegundos requerido para aplicaciones interactivas. Los desarrolladores de empresas pueden comenzar con modelos de última generación que han sido entrenados durante más de 100,000 horas en sistemas NVIDIA DGX.
Las empresas pueden aplicar el aprendizaje por transferencia con el Kit de Herramientas de Transfer Learning para ajustar estos modelos con sus datos personalizados. Estos modelos son más adecuados para comprender la jerga específica de la empresa que conduce a una mayor satisfacción del usuario. Los modelos se pueden optimizar con TensorRT, el SDK de inferencia de alto rendimiento de NVIDIA, y se pueden implementar como servicios que se pueden ejecutar y escalar en el data center. El habla y la visión se pueden usar juntas para crear aplicaciones que hacen que las interacciones con los dispositivos sean naturales y más parecidas a las humanas. Riva hace posible que todas las empresas utilicen tecnología de IA conversacional de clase mundial que antes solo podían intentar los expertos en IA.
¿Cómo Sonará la IA Conversacional del Futuro?
Las interfaces de voz básicas como los algoritmos de árbol telefónico (con indicaciones como “Para reservar un nuevo vuelo, diga ‘reservas’”) son transaccionales y requieren un conjunto de pasos y respuestas que mueven a los usuarios a través de una cola preprogramada. A veces, solo el agente humano al final del árbol telefónico puede comprender una pregunta matizada y resolver el problema de la persona que llama de manera inteligente.
Los asistentes de voz del mercado actual hacen mucho más, pero se basan en modelos de idiomas que no son tan complejos como podrían ser, con millones en lugar de miles de millones de parámetros. Estas herramientas de IA pueden bloquearse durante las conversaciones al proporcionar una respuesta como “déjame buscarte eso” antes de responder una pregunta. O mostrarán una lista de resultados de una búsqueda web en lugar de responder a una consulta con un lenguaje conversacional.
Una IA verdaderamente conversacional daría un paso más. El modelo ideal es lo suficientemente complejo como para comprender con precisión las consultas de una persona sobre los resultados de su extracto bancario o informe médico, y lo suficientemente rápido como para responder casi instantáneamente en un lenguaje natural y fluido.
Las aplicaciones para esta tecnología podrían incluir un asistente de voz en el consultorio de un médico que ayude al paciente a programar una cita y el análisis de sangre de seguimiento, o una IA de voz para comercios minoristas que explique a una persona que llama frustrada por qué se retrasa el envío de un paquete y ofrece un crédito en la tienda.
La demanda de estas herramientas avanzadas de IA conversacional está en aumento: se estima que el 50 por ciento de las búsquedas se realizarán con voz para 2020 y, para 2023, habrá 8,000 millones de asistentes de voz digitales en uso.
¿Qué Es BERT?
BERT (Representaciones de Codificador Bidireccional de Transformers) es un modelo grande y computacionalmente intensivo que estableció el camino para la comprensión de idiomas naturales, cuando se lanzó el 2020. Con un ajuste fino, se puede aplicar a una amplia gama de tareas lingüísticas, como comprensión de lectura, análisis de sentimientos o preguntas y respuestas.
BERT se entrenó con un enorme corpus de 3,300 millones de palabras de texto en inglés, por lo que se desempeña excepcionalmente bien, mejor que un humano promedio en algunos casos, para comprender los idiomas. Su ventaja es su capacidad para entrenarse con conjuntos de datos sin etiquetar y, con una mínima modificación, generalizar a una amplia gama de aplicaciones.
El mismo BERT se puede utilizar para comprender varios idiomas y ajustarse para realizar tareas específicas como traducción, autocompletado o clasificación de los resultados de la búsqueda. Esta versatilidad lo convierte en una opción popular para desarrollar una comprensión compleja de idiomas naturales.
En la base de BERT se encuentra la capa Transformer, una alternativa a las redes neuronales recurrentes que aplica una técnica de atención: analizar una oración enfocando la atención en las palabras más relevantes que vienen antes y después de ella.
La declaración “Me paré junto al banco”, por ejemplo, podría describir una entidad financiera o una silla, dependiendo de si la oración termina con “donde pedí un préstamo” o “de la plaza”. Usando un método conocido como la codificación bidireccional o no direccional, los modelos de lenguaje como BERT pueden usar señales de contexto para comprender mejor qué significado se aplica en cada caso.
Los principales modelos de procesamiento de idiomas en los dominios actuales se basan en BERT, lo que incluye BioBERT (para documentos biomédicos) y SciBERT (para publicaciones científicas).
¿Cómo Optimiza la Tecnología NVIDIA los Modelos Basados en Transformer?
Las capacidades de procesamiento paralelo y la arquitectura Tensor Core de las GPU de NVIDIA permiten un mayor rendimiento y escalabilidad cuando se trabaja con modelos de lenguaje complejos, lo que permite un rendimiento récord tanto para el entrenamiento como para la inferencia de BERT.
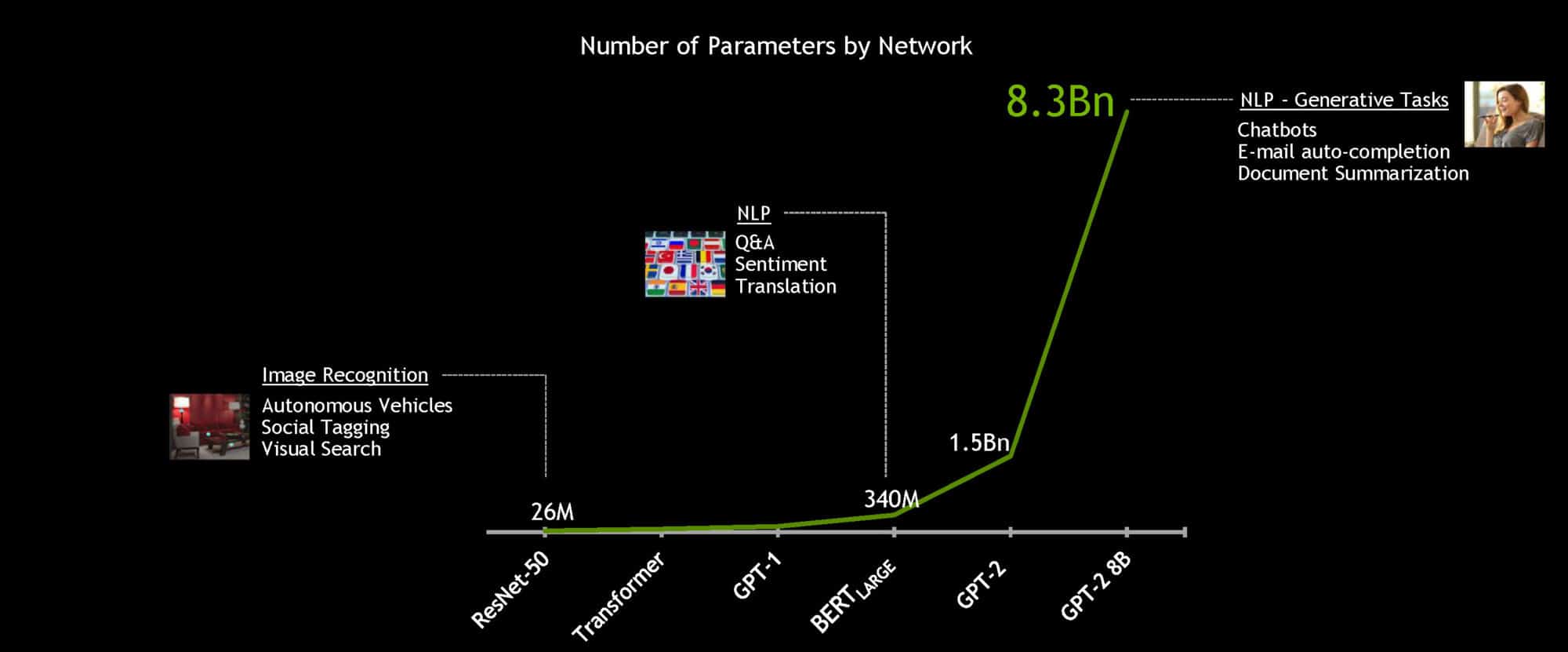
Con el potente sistema NVIDIA DGX SuperPOD, el modelo BERT-Large de 340 millones de parámetros se puede entrenar en menos de una hora, en comparación con un tiempo de entrenamiento típico de varios días. Pero para la IA conversacional en tiempo real, la aceleración esencial es la inferencia.
Los desarrolladores de NVIDIA optimizaron el modelo BERT-Base de 110 millones de parámetros para la inferencia utilizando el software TensorRT. Al ejecutarse en GPU NVIDIA T4, el modelo fue capaz de calcular respuestas en solo 2.2 milisegundos cuando se probó en el conjunto de datos de respuesta a preguntas de Stanford. Conocido como SQuAD, el conjunto de datos es un punto de referencia popular para evaluar la capacidad de un modelo para comprender el contexto.
El umbral de latencia para muchas aplicaciones en tiempo real es de 10 milisegundos. Incluso el código de CPU altamente optimizado da como resultado un tiempo de procesamiento de más de 40 milisegundos.
Al reducir el tiempo de inferencia a un par de milisegundos, es práctico por primera vez implementar BERT en producción. Y no se trata solo de BERT: los mismos métodos se pueden usar para acelerar otros grandes modelos de idiomas naturales basados en Transformer como GPT-2, XLNet y RoBERTa.
Para trabajar hacia el objetivo de una IA verdaderamente conversacional, los modelos de idiomas se hacen más grandes con el tiempo. Los modelos futuros serán mucho más grandes que los que se utilizan hoy en día, por lo que NVIDIA creó la IA basada en Transformer más grande hasta el momento: GPT-2 8B, un modelo de procesamiento de idiomas de 8,300 millones de parámetros que es 24 veces más grande que BERT-Large.
Aprende a Desarrollar tus Propias Aplicaciones de Procesamiento de Idiomas Naturales Basadas en Transformer
El Deep Learning Institute de NVIDIA ofrece capacitación práctica dirigida por instructores sobre las herramientas y técnicas fundamentales para desarrollar modelos de procesamiento de idiomas naturales basados en Transformer para tareas de clasificación de texto, como la categorización de documentos. Este taller detallado e impartido por un experto tiene una duración de 8 horas y abarca los siguientes temas:
- Comprender cómo las incrustaciones de palabras han evolucionado rápidamente en las tareas de PNL, desde Word2Vec y las incrustaciones recurrentes basadas en redes neuronales hasta las incrustaciones contextualizadas basadas en Transformer
- Ver cómo las características de la arquitectura Transformer, especialmente la atención personal, se utilizan para crear modelos de idiomas sin RNN
- Usar la autosupervisión para mejorar la arquitectura de Transformer en BERT, Megatron y otras variantes para obtener resultados superiores en PNL.
- Aprovechar los modelos modernos de PNL previamente entrenados para resolver múltiples tareas, como clasificación de texto, NER y respuesta a preguntas
- Administrar los desafíos de inferencia e implementar modelos refinados para aplicaciones en vivo
Obtener un certificado DLI para demostrar competencia en la materia y acelerar el crecimiento de su carrera. Solicita un taller para tu organización.
Para obtener más información sobre la IA conversacional, el entrenamiento de BERT en GPU, la optimización de BERT para inferencia y otros proyectos de procesamiento de idiomas naturales, consulta el Blog1 para Desarrolladores de NVIDIA.