
Los micrófonos estaban en vivo y la cinta estaba rodando en el estudio donde Miles Davis Quintet estaba grabando docenas de canciones en 1956 para Prestige Records.
Cuando un ingeniero preguntó por el título de la siguiente canción, Davis respondió: «La tocaré y luego les diré cuál es».
Al igual que el prolífico trompetista y compositor de jazz, los investigadores han estado generando modelos de IA a un ritmo frenético, explorando nuevas arquitecturas y casos de uso. Centrados en arar nuevos terrenos, a veces dejan a otros el trabajo de categorizar su trabajo.
Un equipo de más de cien investigadores de Stanford colaboró para hacer precisamente eso en un artículo de 214 páginas publicado en el verano de 2021.
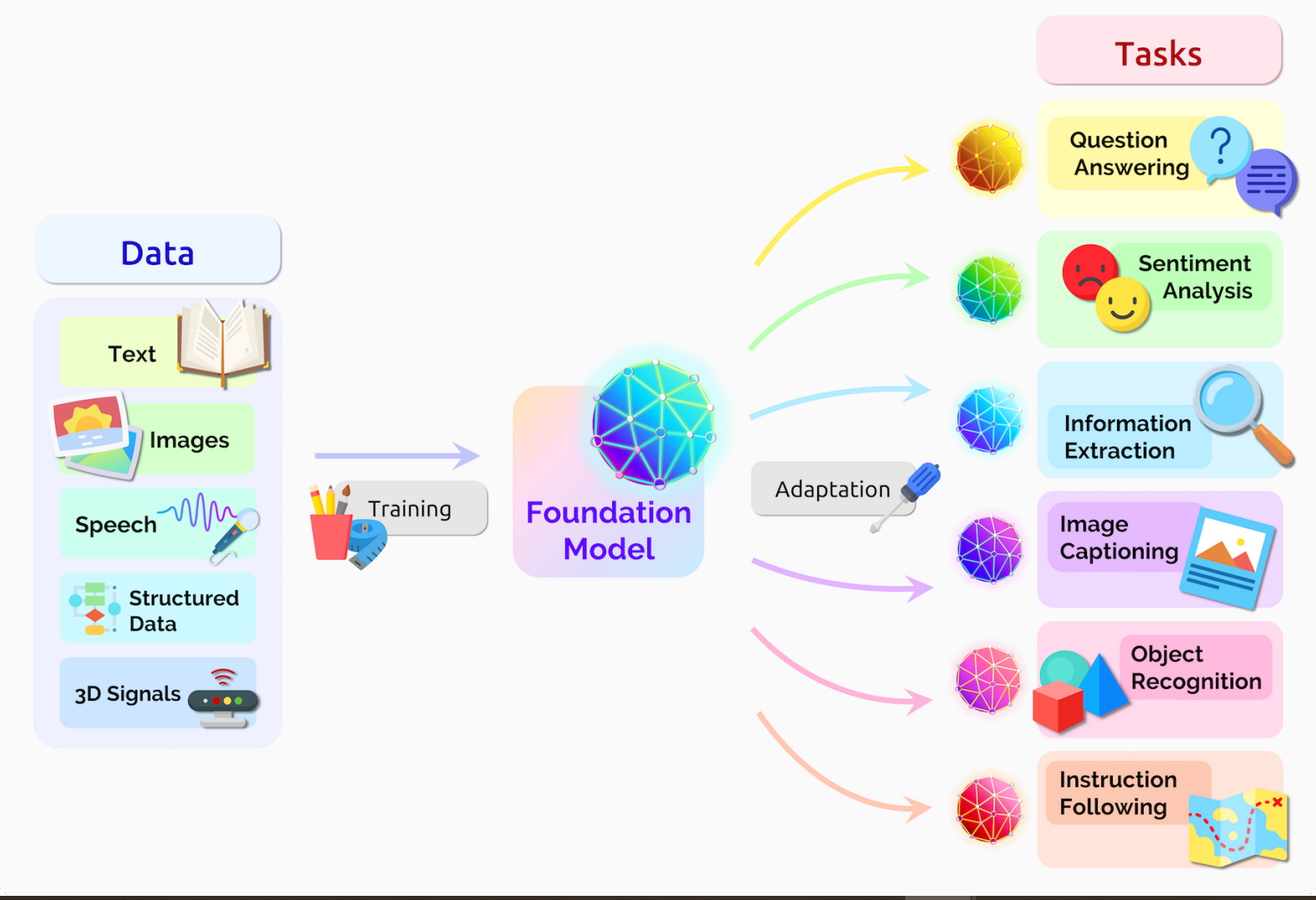
Dijeron que los modelos transformadores, los modelos de lenguaje grande (LLM) y otras redes neuronales que aún se están construyendo son parte de una nueva categoría importante que denominaron modelos de base.
Definición de Modelos de Base
Un modelo de base es una red neuronal de IA, entrenada en montañas de datos sin procesar, generalmente con aprendizaje no supervisado, que se puede adaptar para realizar una amplia gama de tareas, dijo el documento.
“La gran escala y el alcance de los modelos de base de los últimos años han ampliado nuestra imaginación de lo que es posible”, escribieron.
Dos conceptos importantes ayudan a definir esta categoría general: la recopilación de datos es más fácil y las oportunidades son tan amplias como el horizonte.
Sin Etiquetas, Muchas Oportunidades
Los modelos de base generalmente aprenden de conjuntos de datos sin etiquetar, lo que ahorra el tiempo y el gasto de describir manualmente cada elemento en colecciones masivas.
Las redes neuronales anteriores estaban estrechamente ajustadas para tareas específicas. Con un poco de ajuste, los modelos de base pueden manejar trabajos desde la traducción de texto hasta el análisis de imágenes médicas.
Los modelos de base están demostrando un «comportamiento impresionante» y se están implementando a escala, dijo el grupo en el sitio web de su centro de investigación formado para estudiarlos. Hasta ahora, han publicado más de 50 artículos sobre modelos de base solo de investigadores internos.
“Creo que hemos descubierto una fracción muy pequeña de las capacidades de los modelos de base existentes, por no hablar de los futuros”, dijo Percy Liang, director del centro, en la charla de apertura del primer taller sobre modelos de base.
Aparición y Homogeneización de la IA
En esa charla, Liang acuñó dos términos para describir los modelos de base:
La emergencia se refiere a las funciones de IA que aún se están descubriendo, como las muchas habilidades incipientes en los modelos de base. Él llama homogeneización a la combinación de algoritmos de IA y arquitecturas modelo, una tendencia que ayudó a formar modelos de base. (Consulte el cuadro a continuación).
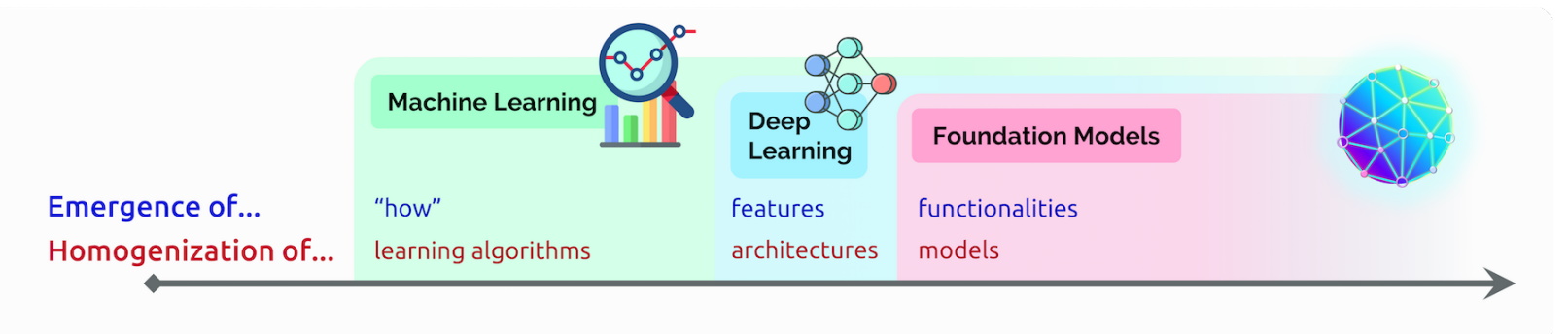
El campo continúa moviéndose rápido.
Un año después de que el grupo definiera los modelos de base, otros observadores tecnológicos acuñaron un término relacionado: IA generativa. Es un término genérico para transformadores, modelos de lenguaje extenso, modelos de difusión y otras redes neuronales que capturan la imaginación de las personas porque pueden crear texto, imágenes, música, software y más.
La IA generativa tiene el potencial de producir billones de dólares de valor económico, dijeron ejecutivos de la firma de riesgo Sequoia Capital que compartieron sus puntos de vista en un podcast de IA reciente.
Una Breve Historia de los Modelos de Base
“Estamos en un momento en el que métodos simples como las redes neuronales nos brindan una explosión de nuevas capacidades”, dijo Ashish Vaswani, un empresario y excientífico investigador senior de Google Brain que dirigió el trabajo en el artículo seminal de 2017 sobre transformadores.
Ese trabajo inspiró a los investigadores que crearon BERT y otros grandes modelos de lenguaje, lo que convirtió a 2018 en «un momento decisivo» para el procesamiento del lenguaje natural, según un informe sobre IA a fines de ese año.
Google lanzó BERT como software de código abierto, generando una familia de seguimientos y desencadenando una carrera para construir LLM cada vez más grandes y potentes. Luego aplicó la tecnología a su motor de búsqueda para que los usuarios pudieran hacer preguntas en oraciones simples.
En 2020, los investigadores de OpenAI anunciaron otro transformador histórico, GPT-3. En cuestión de semanas, la gente lo estaba usando para crear poemas, programas, canciones, sitios web y más.
“Los modelos de lenguaje tienen una amplia gama de aplicaciones beneficiosas para la sociedad”, escribieron los investigadores.
Su trabajo también mostró cuán grandes y computacionales pueden ser estos modelos. GPT-3 se entrenó en un conjunto de datos con casi un billón de palabras y cuenta con la friolera de 175 mil millones de parámetros, una medida clave del poder y la complejidad de las redes neuronales.
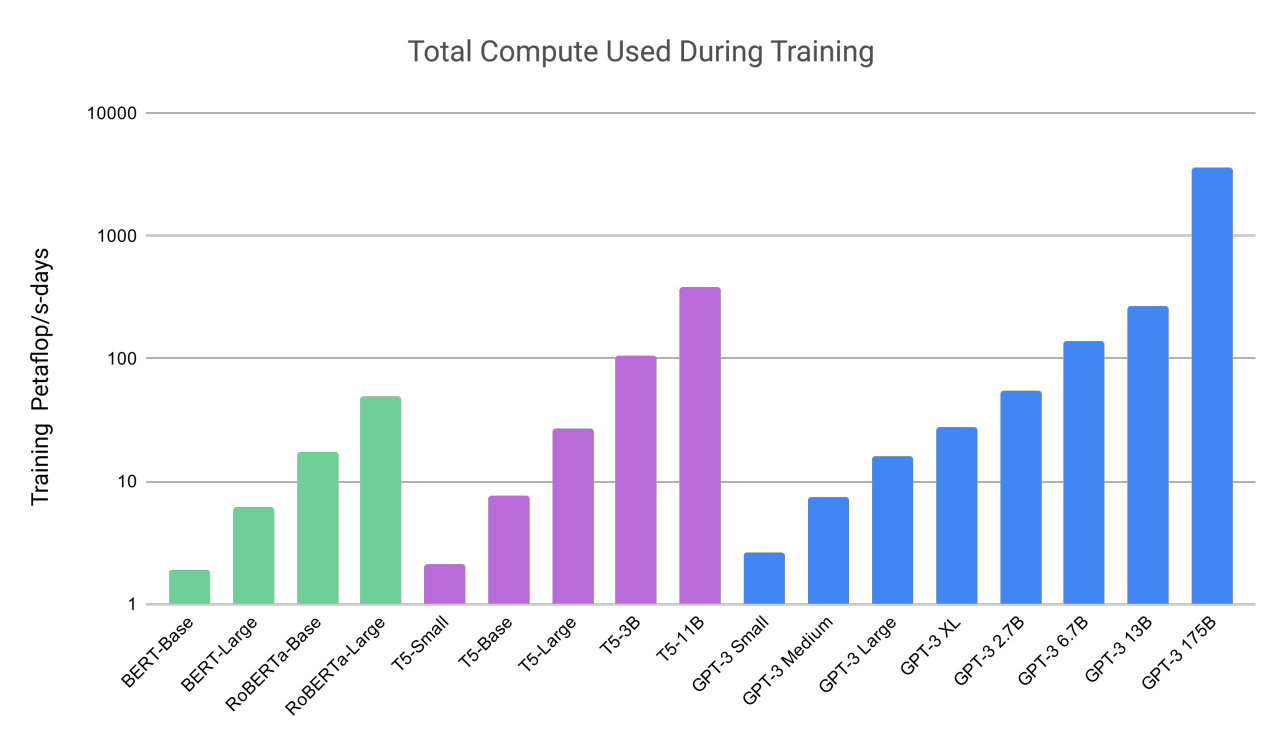
“Recuerdo que me quedé un poco impresionado por las cosas que podía hacer”, dijo Liang, hablando de GPT-3 en un podcast.
La última versión, ChatGPT, entrenada en 10 000 GPU NVIDIA, es aún más atractiva y atrae a más de 100 millones de usuarios en solo dos meses. Su lanzamiento se ha llamado el momento iPhone para la IA porque ayudó a muchas personas a ver cómo podían usar la tecnología.

Del Texto a las Imágenes
Casi al mismo tiempo que debutó ChatGPT, otra clase de redes neuronales, llamadas modelos de difusión, causaron sensación. Su capacidad para convertir descripciones de texto en imágenes artísticas atrajo a usuarios ocasionales para crear imágenes asombrosas que se volvieron virales en las redes sociales.
El primer artículo que describía un modelo de difusión llegó con poca fanfarria en 2015. Pero al igual que los transformadores, la nueva técnica pronto se incendió.
Los investigadores publicaron más de 200 artículos sobre modelos de difusión el año pasado, según una lista mantenida por James Thornton, investigador de IA en la Universidad de Oxford.
En un tuit, el director ejecutivo de Midjourney, David Holz, reveló que su servicio de texto a imagen basado en la difusión tiene más de 4,4 millones de usuarios. Servirlos requiere más de 10,000 GPU NVIDIA principalmente para la inferencia de IA, dijo en una entrevista (se requiere suscripción).
Docenas de Modelos en Uso
Cientos de modelos de base ya están disponibles. Solo un documento cataloga y clasifica más de 50 modelos principales de transformadores (consulte el cuadro a continuación).
El grupo de Stanford comparó 30 modelos de base y señaló que el campo avanza tan rápido que no revisaron algunos nuevos y destacados.
La startup NLP Cloud, miembro del programa NVIDIA Inception que fomenta startups de vanguardia, dice que utiliza alrededor de 25 modelos de lenguaje grandes en una oferta comercial que sirve a aerolíneas, farmacias y otros usuarios. Los expertos esperan que una parte cada vez mayor de los modelos se haga de código abierto en sitios como el hub de modelos de Hugging Face.
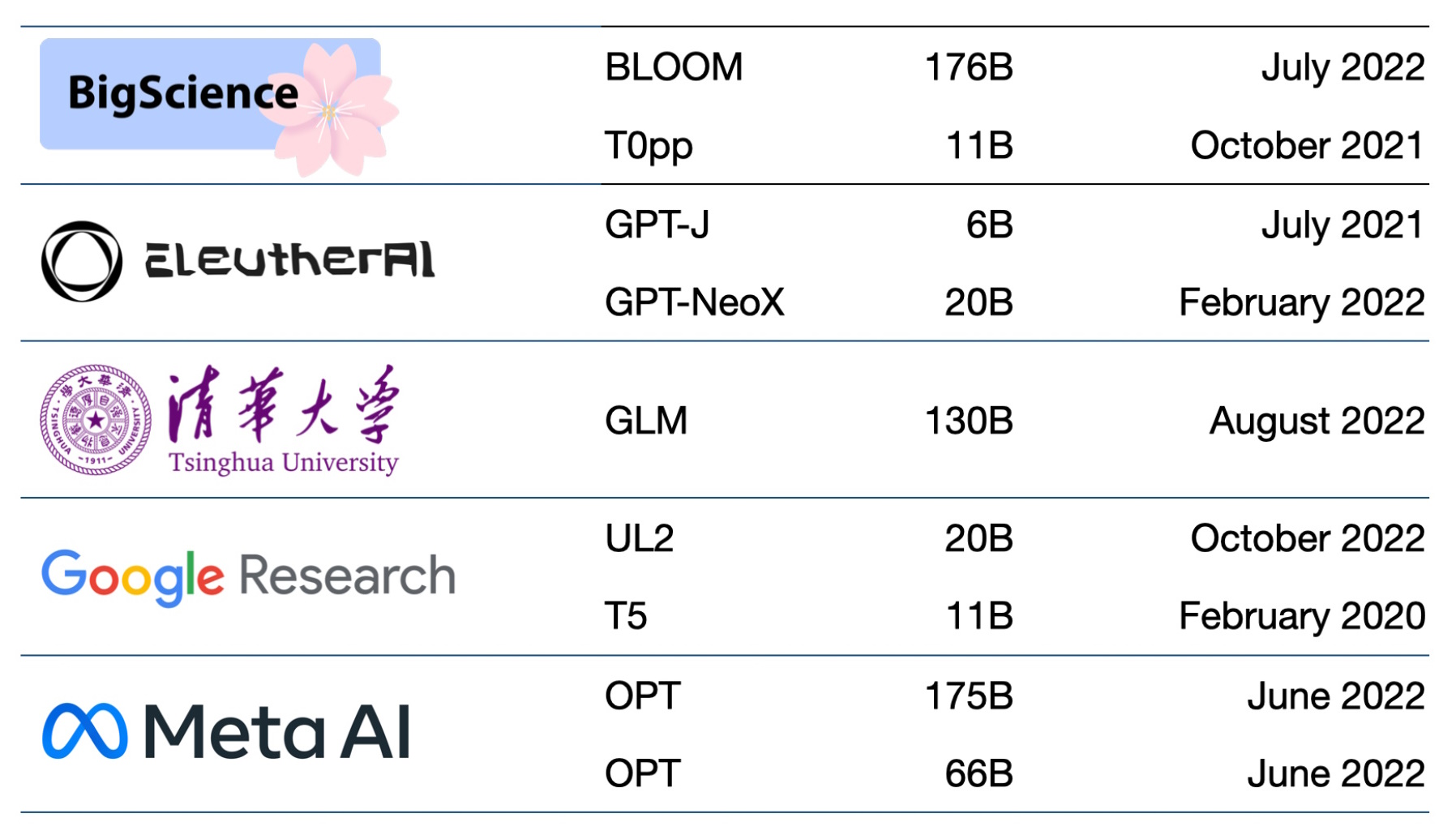
Los modelos de base también se vuelven cada vez más grandes y complejos.
Es por eso que, en lugar de crear nuevos modelos desde cero, muchas empresas ya están personalizando modelos de base previamente entrenados para impulsar sus viajes hacia la IA.
Bae en la Nube
Una firma de capital de riesgo enumera 33 casos de uso para la IA generativa, desde la generación de anuncios hasta la búsqueda semántica.
Los principales servicios en la nube han estado utilizando modelos de base durante algún tiempo. Por ejemplo, Microsoft Azure trabajó con NVIDIA para implementar un transformador para su servicio Translator. Ayudó a los trabajadores de desastres a entender el Haitian Creole mientras respondían a un terremoto de 7.0.
En febrero, Microsoft anunció planes para mejorar su navegador y motor de búsqueda con ChatGPT e innovaciones relacionadas. “Pensamos en estas herramientas como un copiloto de IA para la web”, decía el anuncio.
Google anunció Bard, un servicio experimental de inteligencia artificial conversacional. Planea conectar muchos de sus productos al poder de sus modelos de base como LaMDA, PaLM, Imagen y MusicLM.
“La IA es la tecnología más profunda en la que estamos trabajando hoy”, escribió el blog de la compañía.
Las Startups También Obtienen Tracción
La startup Jasper espera registrar $ 75 millones en ingresos anuales de productos que escriben copias para empresas como VMware. Lidera un campo de más de una docena de empresas que generan texto, incluida Writer, miembro de NVIDIA Inception.
Otros miembros de Inception en el campo incluyen a rinna, con sede en Tokio, que creó chatbots utilizados por millones en Japón. En Tel Aviv, Tabnine ejecuta un servicio de inteligencia artificial generativa que automatiza hasta el 30 % del código escrito por un millón de desarrolladores en todo el mundo.
Una Plataforma para el Área de la Salud
Los investigadores de la startup Evozyne utilizaron modelos de base en NVIDIA BioNeMo para generar dos nuevas proteínas. Uno podría tratar una enfermedad rara y otro podría ayudar a capturar carbono en la atmósfera.
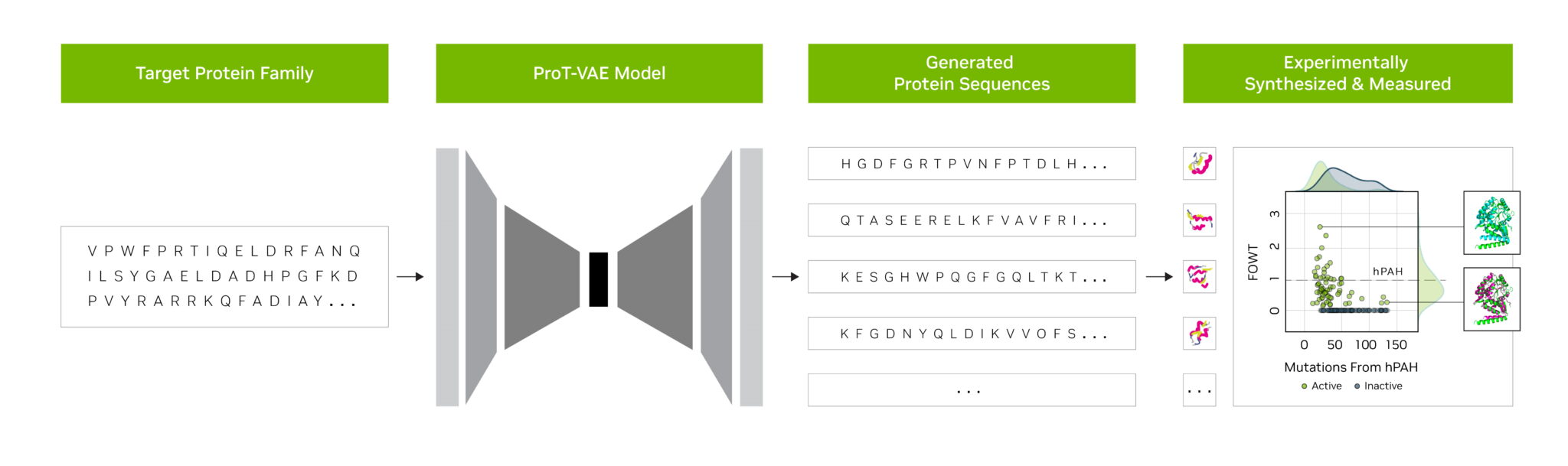
BioNeMo, una plataforma de software y servicio en la nube para IA generativa en el descubrimiento de fármacos ofrece herramientas para entrenar, ejecutar inferencias e implementar modelos de IA biomolecular personalizados. Incluye MegaMolBART, un modelo de IA generativa para química desarrollado por NVIDIA y AstraZeneca.
«Así como los modelos de lenguaje de IA pueden aprender las relaciones entre las palabras en una oración, nuestro objetivo es que las redes neuronales entrenadas en datos de estructuras moleculares puedan aprender las relaciones entre los átomos en las moléculas del mundo real», dijo Ola Engkvist, jefe de IA molecular, ciencias de descubrimiento e I+D en AstraZeneca, cuando se anunció el trabajo.
Por otra parte, el centro académico de salud de la Universidad de Florida colaboró con investigadores de NVIDIA para crear GatorTron. El modelo de lenguaje grande tiene como objetivo extraer información de volúmenes masivos de datos clínicos para acelerar la investigación médica.
Un centro de Stanford está aplicando los últimos modelos de difusión para avanzar en imágenes médicas. NVIDIA también ayuda a las empresas del área de la salud y a los hospitales a usar IA en imágenes médicas, lo que acelera el diagnóstico de enfermedades mortales.
Base de IA para Empresas
Otro framework nuevo, el framework NVIDIA NeMo, tiene como objetivo permitir que cualquier empresa cree sus propios transformadores de mil millones o billones de parámetros para impulsar chatbots personalizados, asistentes personales y otras aplicaciones de IA.
Creó el modelo Megatron-Turing Natural Language Generation (MT-NLG) de 530 000 millones de parámetros que alimenta a TJ, el avatar de Toy Jensen que pronunció parte del discurso de apertura en NVIDIA GTC el año pasado.
Los modelos de base, conectados a plataformas 3D como NVIDIA Omniverse, serán clave para simplificar el desarrollo del metaverso, la evolución 3D de Internet. Estos modelos impulsarán aplicaciones y activos para usuarios industriales y de entretenimiento.
Las fábricas y los almacenes ya están aplicando modelos de base dentro de los gemelos digitales, simulaciones realistas que ayudan a encontrar formas más eficientes de trabajar.
Los modelos de base pueden facilitar el trabajo de entrenar vehículos autónomos y robots que ayuden a los humanos en las plantas de producción y los centros logísticos. También ayudan a entrenar vehículos autónomos mediante la creación de entornos realistas como el que se muestra a continuación.
Todos los días surgen nuevos usos para los modelos de base, al igual que los desafíos para aplicarlos.
Varios artículos sobre modelos de IA generativa y de base que describen riesgos como:
- sesgo de amplificación implícito en los conjuntos de datos masivos utilizados para entrenar modelos,
- introducir información inexacta o engañosa en imágenes o videos, y
- violar los derechos de propiedad intelectual de las obras existentes.
“Dado que los futuros sistemas de IA probablemente dependerán en gran medida de los modelos de base, es imperativo que nosotros, como comunidad, nos unamos para desarrollar principios más rigurosos para los modelos de base y una guía para su desarrollo e implementación responsables”, dijo el documento de Stanford sobre los modelos de base.
Las ideas actuales para salvaguardas incluyen el filtrado de avisos y sus resultados, la recalibración de modelos sobre la marcha y la limpieza de conjuntos de datos masivos.
“Estos son problemas en los que estamos trabajando como comunidad de investigación”, dijo Bryan Catanzaro, vicepresidente de investigación de deep learning aplicado en NVIDIA. “Para que estos modelos se implementen realmente ampliamente, tenemos que invertir mucho en seguridad”.
Es un campo más que los investigadores y desarrolladores de IA están investigando a medida que crean el futuro.