Recientemente, NVIDIA presentó Jetson Generative AI Lab, que permite a los desarrolladores explorar las posibilidades ilimitadas de la IA generativa en un entorno del mundo real con los dispositivos en el edge NVIDIA Jetson. A diferencia de otras plataformas integradas, Jetson es capaz de ejecutar grandes modelos de lenguaje (LLM), transformadores de visión y difusión estable a nivel local. Eso incluye el modelo más grande de Llama-2-70B en Jetson AGX Orin a tarifas interactivas.
Para probar rápidamente los últimos modelos y aplicaciones en Jetson, utilice los tutoriales y recursos proporcionados en el Jetson Generative AI Lab. Ahora puede centrarse en descubrir el potencial sin explotar de las IA generativas en el mundo físico.
En esta publicación, exploramos las emocionantes aplicaciones de IA generativa que puede ejecutar y experimentar en los dispositivos Jetson, todas las cuales se cubren de manera exhaustiva en los tutoriales de laboratorio.
IA Generativa en el Edge
En el panorama de la IA, que evoluciona rápidamente, la atención se centra en los modelos generativos y, en particular, en los siguientes:
- LLM que son capaces de entablar conversaciones similares a las humanas.
- Modelos de lenguaje de visión (VLM) que proporcionan a los LLM la capacidad de percibir y comprender el mundo real a través de una cámara.
- Modelos de difusión que pueden transformar simples indicaciones de texto en impresionantes creaciones visuales.
Estos notables avances en IA han capturado la imaginación de muchos. Sin embargo, si se profundiza en la infraestructura que soporta esta inferencia de modelos de vanguardia, a menudo se encontrarán atados a la nube, dependiendo de los data centers para su potencia de procesamiento. Este enfoque centrado en la nube deja en gran medida inexploradas ciertas aplicaciones en el edge, que requieren un procesamiento de datos de baja latencia y gran ancho de banda.
La tendencia emergente de ejecutar LLM y otros modelos generativos en entornos locales está ganando impulso dentro de las comunidades de desarrolladores. Las prósperas comunidades en línea, como r/LocalLlama en Reddit, proporcionan una plataforma para que los entusiastas discutan los últimos desarrollos en tecnologías de IA generativa y sus aplicaciones en el mundo real. Numerosos artículos técnicos publicados en plataformas como Medium profundizan en las complejidades de ejecutar LLM de código abierto en configuraciones locales, y algunos aprovechan NVIDIA Jetson.
El Jetson Generative AI Lab sirve como un centro para descubrir los últimos modelos y aplicaciones de IA generativa y aprender a ejecutarlos en dispositivos Jetson. A medida que el campo evoluciona a un ritmo rápido, con nuevos LLM que surgen casi a diario y los avances en las bibliotecas de cuantificación que remodelan los puntos de referencia de la noche a la mañana, NVIDIA reconoce la importancia de ofrecer la información más actualizada y herramientas efectivas. Ofrecemos tutoriales fáciles de seguir y contenedores prediseñados.
La fuerza habilitante son los Jetson-Containers, un proyecto de código abierto cuidadosamente diseñado y meticulosamente mantenido para construir contenedores para dispositivos Jetson. Con GitHub Actions, está creando 100 contenedores en forma de CI/CD. Esto le permite probar rápidamente los últimos modelos, bibliotecas y aplicaciones de IA en Jetson sin la molestia de configurar herramientas y bibliotecas subyacentes.
El Jetson Generative AI Lab y los Jetson-Containers le permiten concentrarse en explorar las posibilidades ilimitadas de la IA generativa en entornos del mundo real con Jetson.
Tutorial
Estas son algunas de las emocionantes aplicaciones de IA generativa que se ejecutan en el dispositivo NVIDIA Jetson disponibles en el Jetson Generative AI Lab.
stable-diffusion-webui
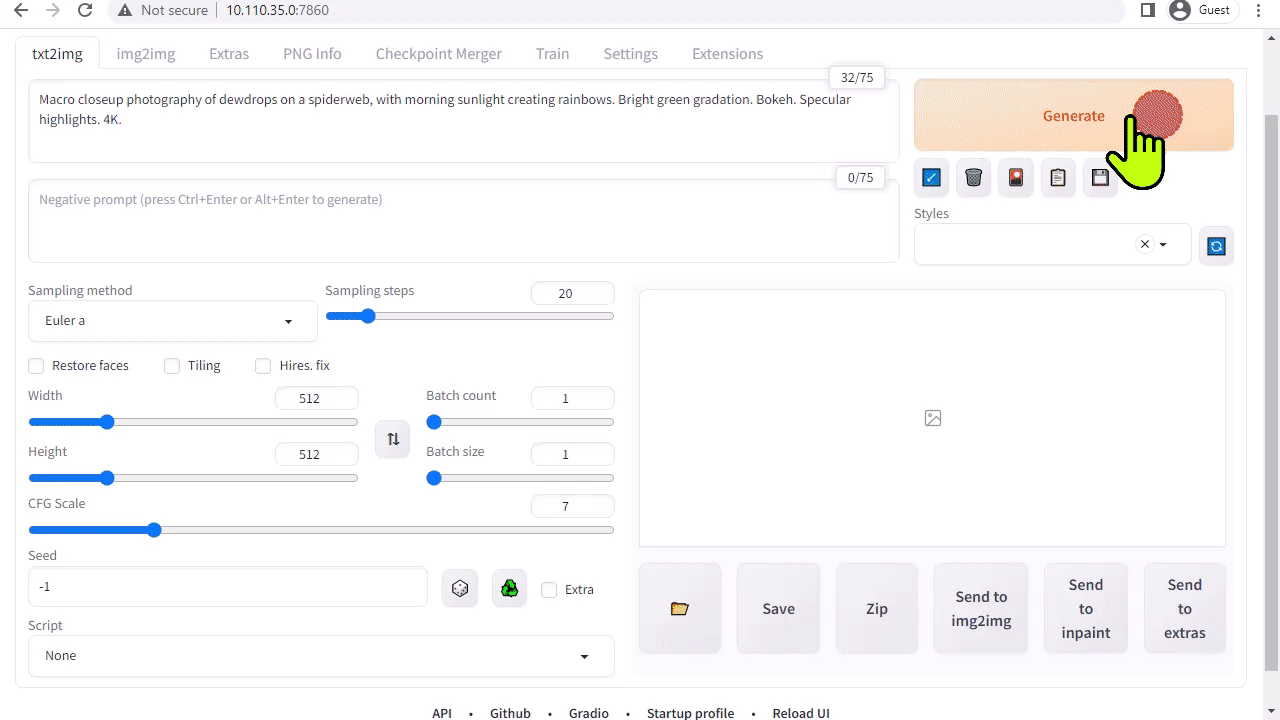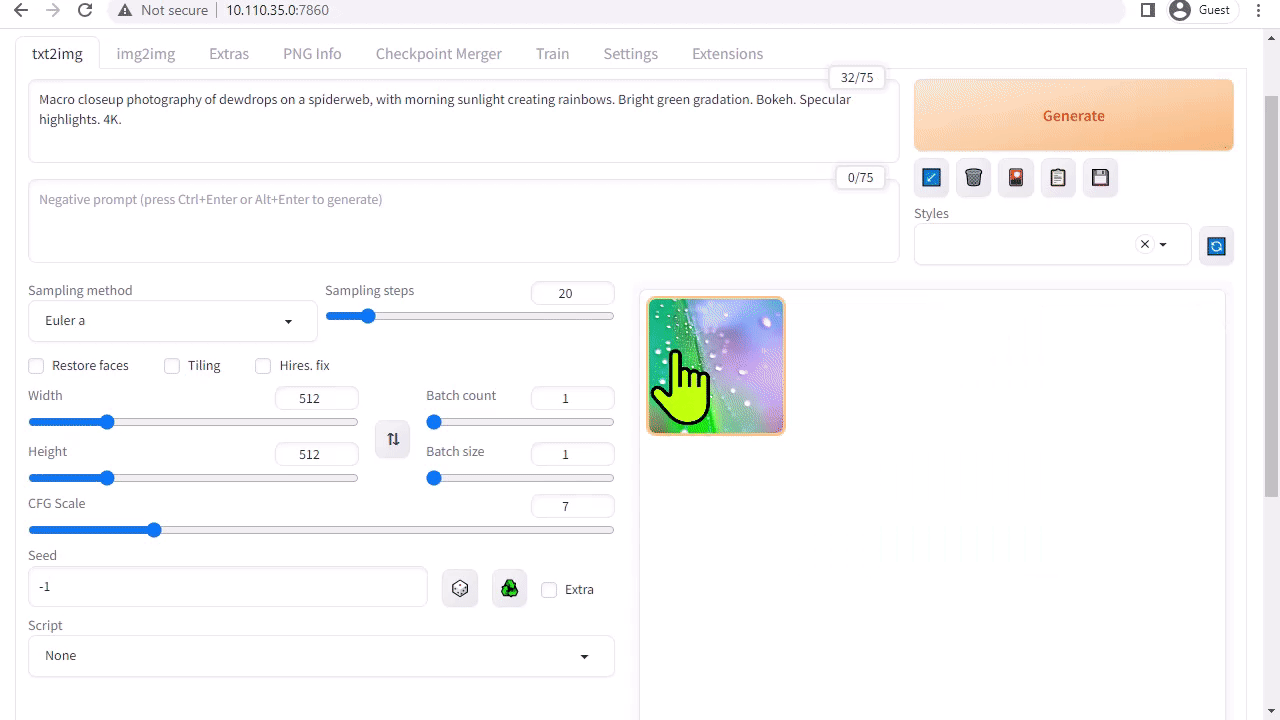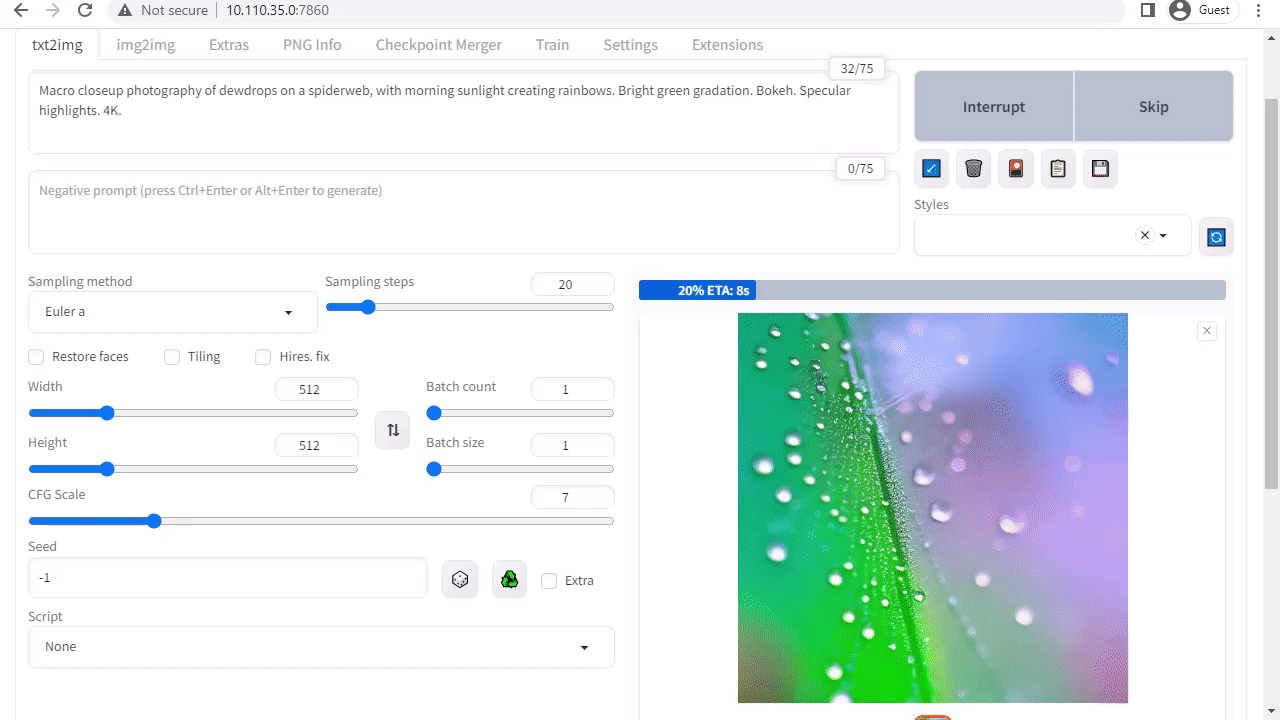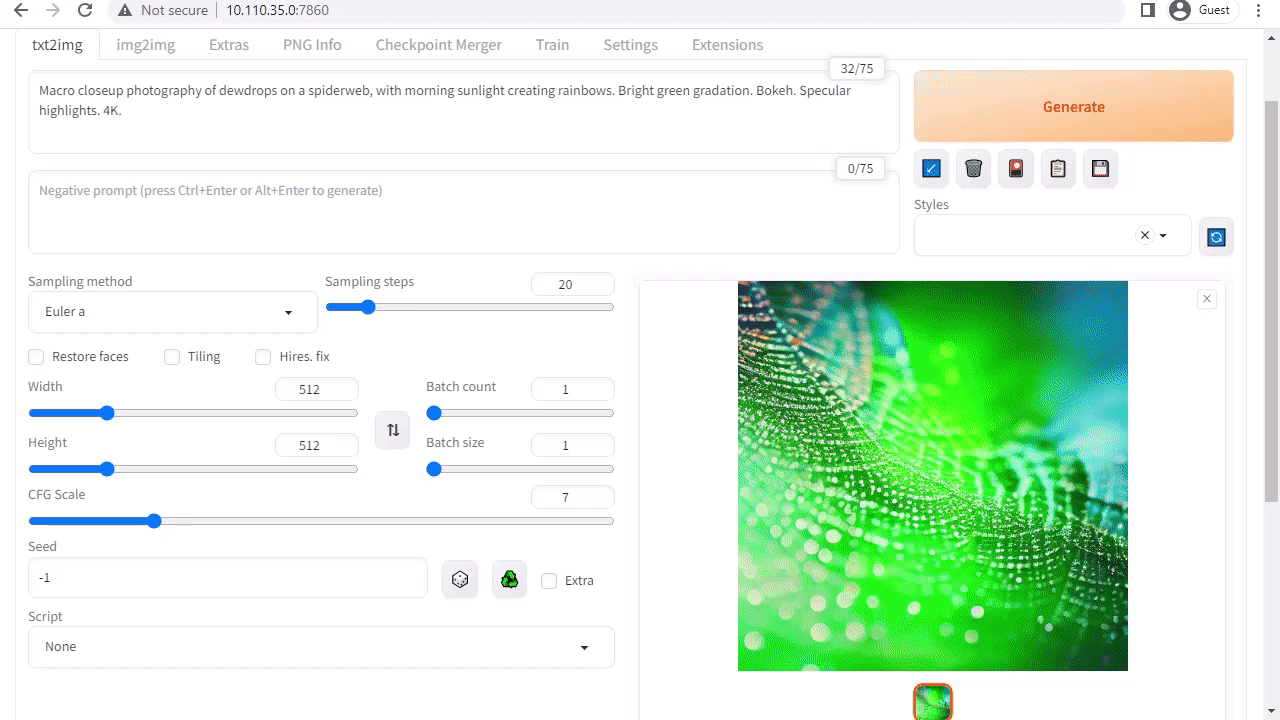
La interfaz de usuario stable-diffusion-webui de A1111 proporciona una interfaz fácil de usar para Stable Diffusion lanzada por Stability AI. Le permite realizar muchas tareas, incluidas las siguientes:
- Txt2img: Genera una imagen basada en un mensaje de texto.
- img2img: Genera una imagen a partir de una imagen de entrada y un mensaje de texto correspondiente.
- inpainting: Rellena las partes faltantes o enmascaradas de la imagen de entrada.
- Outpainting: Expande la imagen de entrada más allá de sus bordes originales.
La aplicación web descarga el modelo Stable Diffusion v1.5 automáticamente durante el primer inicio, por lo que puede comenzar a generar su imagen de inmediato. Si tienes un dispositivo Jetson Orin, es tan fácil como ejecutar los siguientes comandos, como se explica en el tutorial.
git clone https://github.com/dusty-nv/jetson-containerscd jetson-containers./run.sh $(./autotag stable-diffusion-webui) |
Para obtener más información sobre cómo ejecutar stable-diffusion-webui, consulte el tutorial del Jetson Generative AI Lab. Jetson AGX Orin también es capaz de ejecutar los nuevos modelos Stable Diffusion XL (SDXL), que generaron la imagen destacada en la parte superior de esta publicación.
text-generation-webui
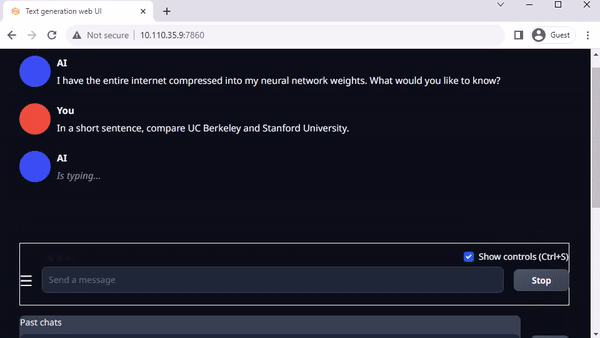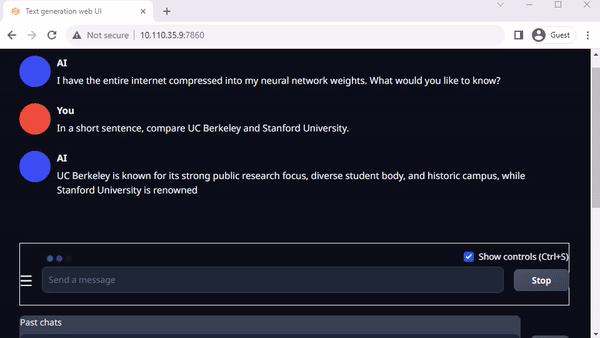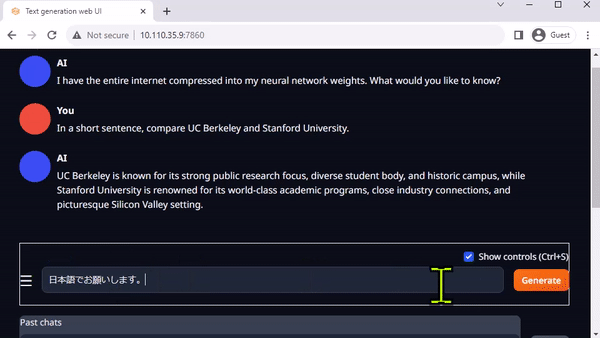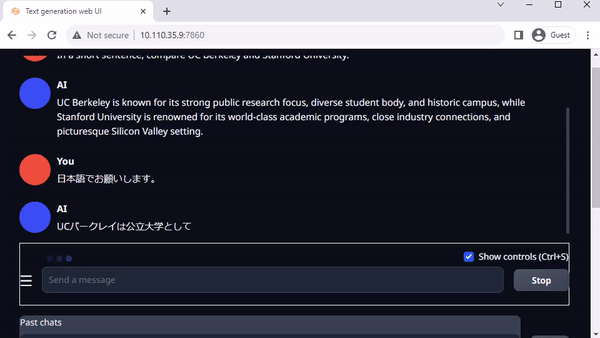
La interfaz web de generación de texto de Oobaboboga es otra interfaz web popular basada en Gradio para ejecutar LLM en un entorno local. El repositorio oficial proporciona instaladores de un solo clic para plataformas, pero los Jetson-Containers ofrecen un método aún más fácil.
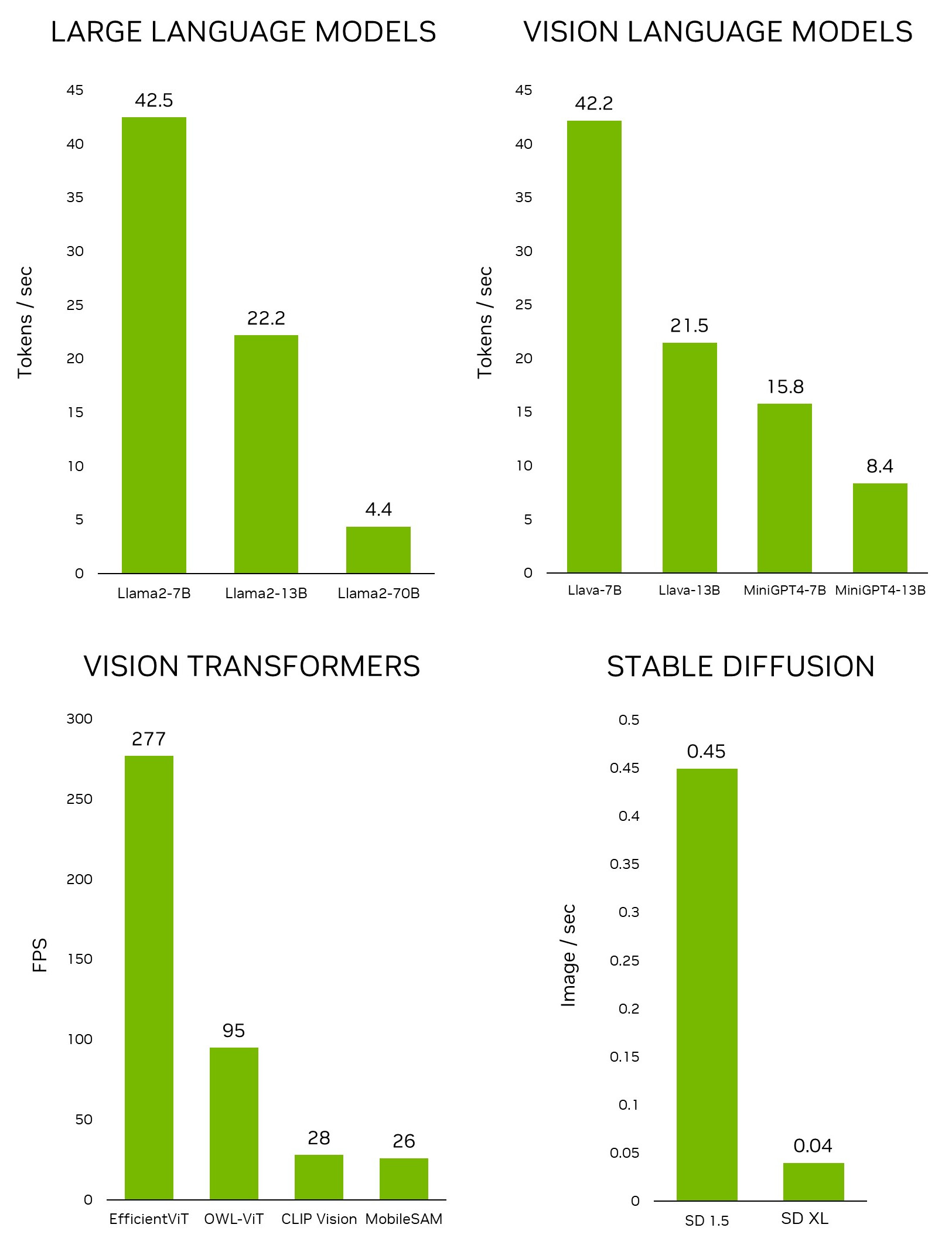
Usando la interfaz, puede descargar fácilmente un modelo desde el repositorio de modelos de Hugging Face. Con la cuantificación de 4 bits, la regla general es que Jetson Orin Nano generalmente puede acomodar un modelo de parámetros de 7B, Jetson Orin NX de 16 GB puede ejecutar un modelo de parámetros de 13B y Jetson AGX Orin de 64 GB puede ejecutar la friolera de modelos de parámetros de 70B.
Muchas personas están trabajando ahora en Llama-2, el modelo de lenguaje grande de código abierto de Meta, disponible de forma gratuita para investigación y uso comercial. Hay modelos basados en Llama-2 que también se entrenan utilizando técnicas como el torneado fino supervisado (SFT) y el aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). Algunos incluso afirman que está superando a GPT-4 en algunos puntos de referencia.
Text-generation-webui proporciona extensiones y le permite desarrollar sus propias extensiones. Esto se puede usar para integrar su aplicación, como verá más adelante en el ejemplo de llamaspeak. También tiene soporte para VLM multimodales como Llava y chat sobre imágenes.
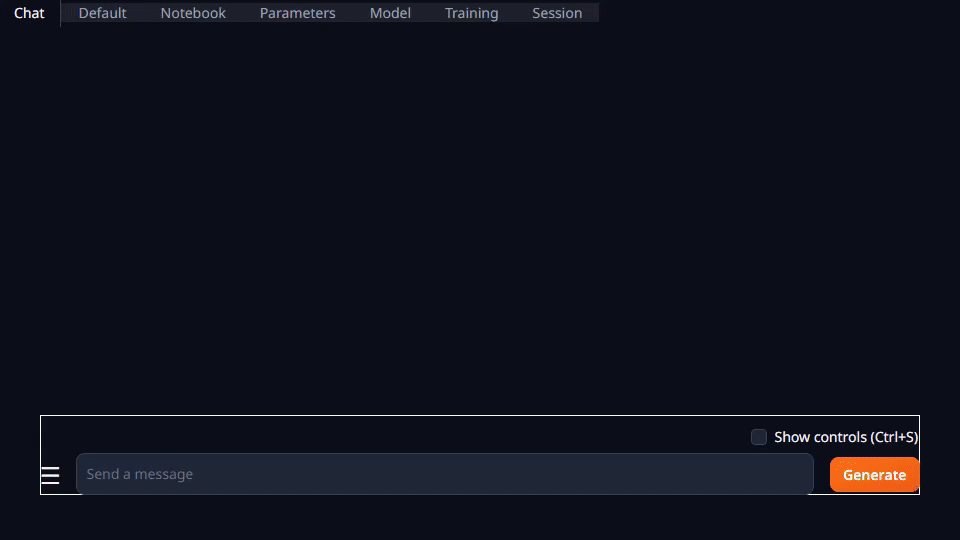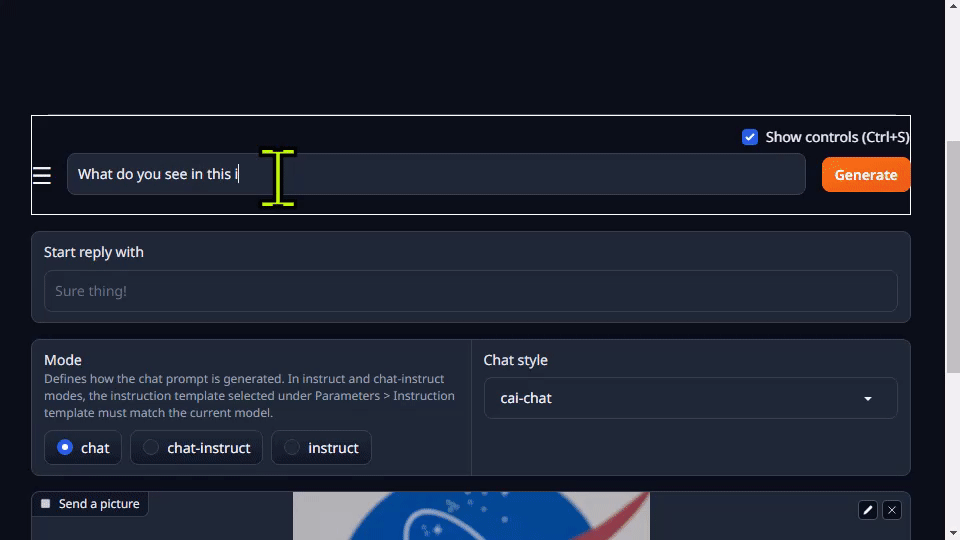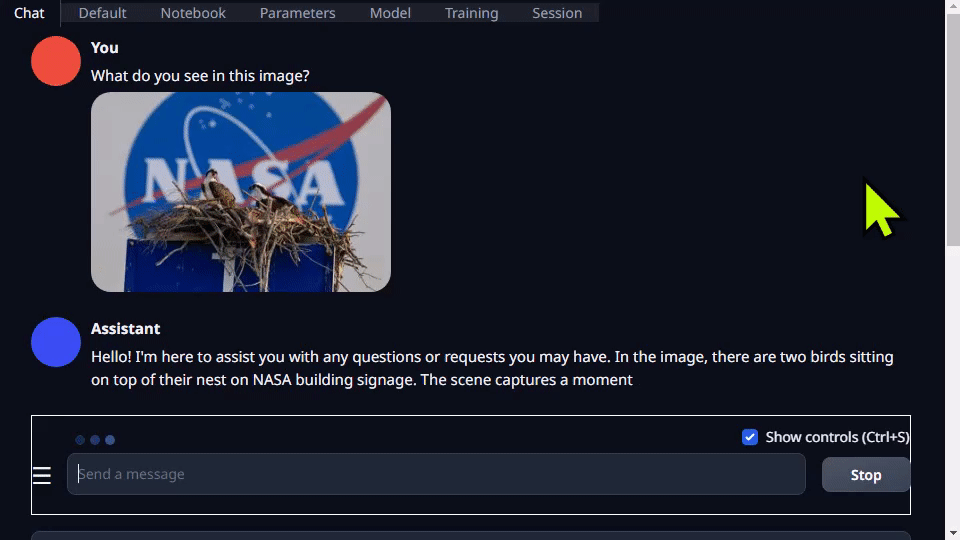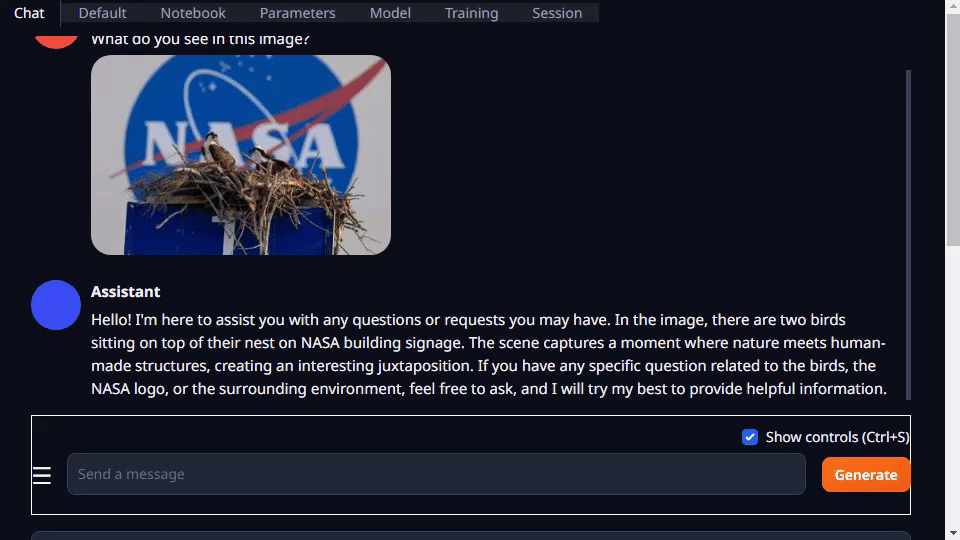
Para obtener más información sobre cómo ejecutar text-generation-webui, consulte el tutorial del Jetson Generative AI Lab.
Llamaspeak
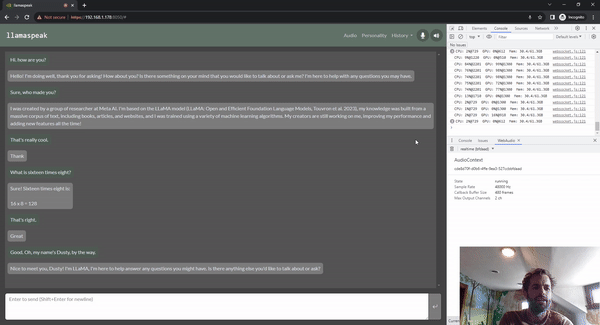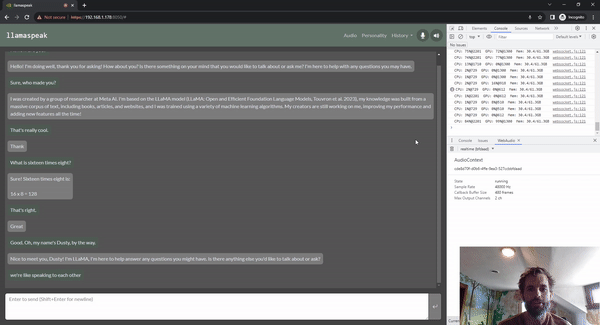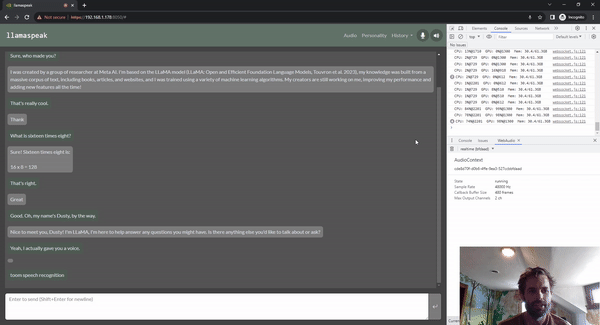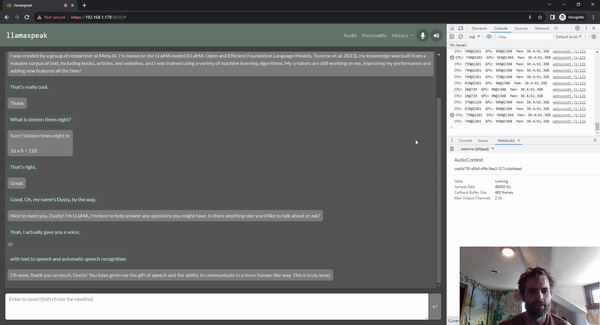
Llamaspeak es una aplicación de chat interactivo que emplea NVIDIA Riva ASR/TTS en vivo para permitirle llevar a cabo conversaciones verbales con un LLM que se ejecuta localmente. Actualmente se ofrece como parte de Jetson-Containers.
Para llevar a cabo una conversación de voz fluida, es fundamental minimizar el tiempo hasta el primer token de salida de un LLM. Además de eso, llamaspeak está diseñado para manejar la interrupción de la conversación para que pueda comenzar a hablar mientras llamaspeak todavía está TTS-ing la respuesta generada. Los microservicios de contenedor se usan para Riva, el LLM y el servidor de chat.
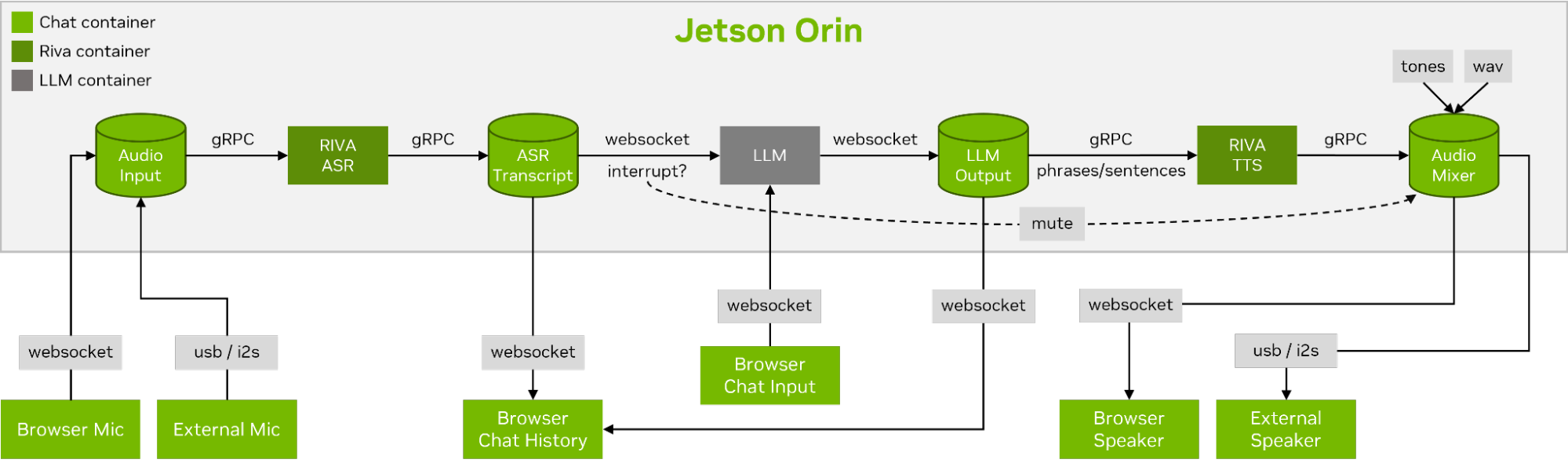
llamaspeak tiene una interfaz receptiva con transmisión de audio de baja latencia desde los micrófonos del navegador o un micrófono conectado a su dispositivo Jetson. Para obtener más información sobre cómo ejecutarlo usted mismo, consulte la documentación de Jetson-Containers.
NanoOWL

Open World Localization with Vision Transformers (OWL-ViT) es un enfoque para la detección de vocabulario abierto, desarrollado por Google Research. Este modelo le permite detectar objetos proporcionando solicitudes de texto para esos objetos.
Por ejemplo, para detectar personas y coches, solicite al sistema un texto que describa las clases:
prompt = “a person, a car”
Esto es increíblemente valioso para desarrollar rápidamente nuevas aplicaciones, sin necesidad de entrenar un nuevo modelo. Para desbloquear aplicaciones en el edge, nuestro equipo desarrolló un proyecto, NanoOWL, que optimiza este modelo con NVIDIA TensorRT para obtener rendimiento en tiempo real en las plataformas NVIDIA Jetson Orin (~95 FPS de velocidad de codificación en Jetson AGX Orin). Este rendimiento significa que puede ejecutar OWL-ViT muy por encima de las velocidades de fotogramas comunes de la cámara.
El proyecto también contiene un nuevo pipeline de detección de árboles que permite combinar el modelo acelerado OWL-ViT con CLIP para permitir la detección y clasificación de disparo cero en cualquier nivel. Por ejemplo, para detectar rostros y clasificarlos como felices o tristes, utilice el siguiente mensaje:
prompt = “[a face (happy, sad)]”
Para detectar rostros y, a continuación, detectar rasgos faciales en cada región de interés, utilice el siguiente mensaje:
prompt = “[a face [an eye, a nose, a mouth]]”
Combínalos:
prompt = “[a face (happy, sad)[an eye, a nose, a mouth]]”
La lista continúa. Si bien la precisión de este modelo puede ser mejor para algunos objetos o clases que para otros, la facilidad de desarrollo significa que puede probar rápidamente diferentes indicaciones y averiguar si funciona para usted. ¡Esperamos ver qué increíbles aplicaciones desarrolláis!
Modelo Segment Anything
Meta lanzó el modelo Segment Anything (SAM), un modelo avanzado de segmentación de imágenes diseñado para identificar y segmentar con precisión objetos dentro de las imágenes, independientemente de su complejidad o contexto.
Su repositorio oficial también tiene cuadernos de Jupyter para verificar fácilmente el impacto del modelo, y los contenedores de supersón ofrecen un contenedor conveniente que tiene Jupyter Lab incorporado.
NanoSAM

Segment Anything (SAM) es un modelo increíble que es capaz de convertir puntos en máscaras de segmentación. Desafortunadamente, no se ejecuta en tiempo real, lo que limita su utilidad en aplicaciones periféricas.
Para superar esta limitación, recientemente hemos lanzado un nuevo proyecto, NanoSAM, que destila el codificador de imagen SAM en un modelo ligero. También optimiza el modelo con NVIDIA TensorRT para permitir el rendimiento en tiempo real en las plataformas NVIDIA Jetson Orin. Ahora, puede convertir fácilmente su cuadro delimitador o detector de puntos clave existente en un modelo de segmentación de instancias, sin necesidad de formación.
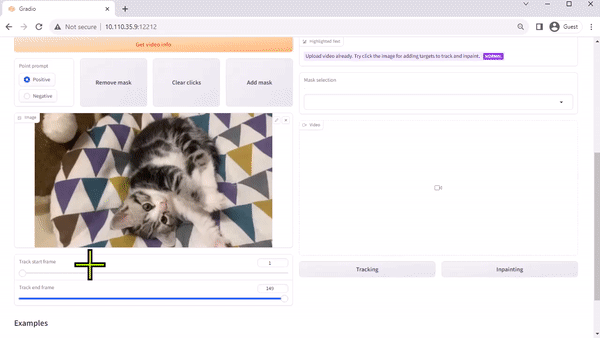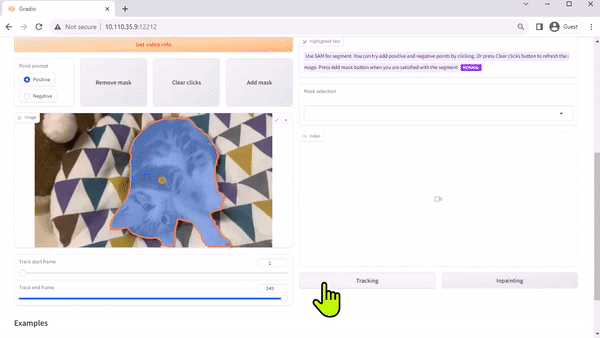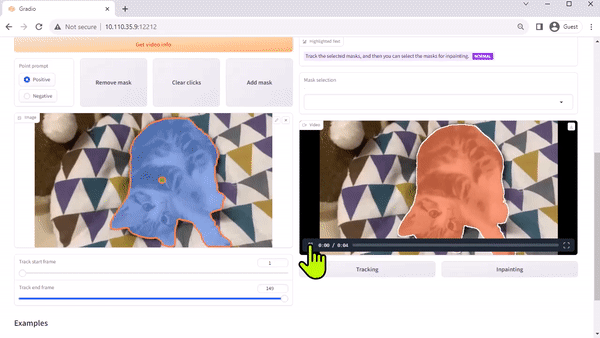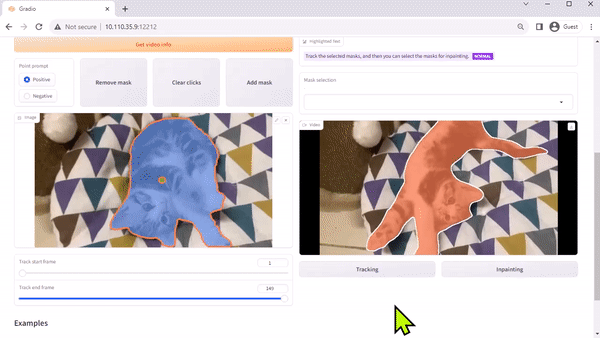
Modelo Track Anything
El modelo Track Anything (TAM) es, como explica el documento del equipo, «Segment Anything se encuentra con los videos». Su interfaz de código abierto basada en Radio le permite hacer clic en un fotograma de un video de entrada para especificar cualquier cosa para rastrear y segmentar. Incluso muestra una capacidad adicional de eliminar el objeto rastreado mediante el pintado interno.
NanoDB
Además de indexar y buscar eficazmente los datos en el edge, estas bases de datos vectoriales se utilizan a menudo junto con los LLM para la generación aumentada de recuperación (RAG) para la memoria a largo plazo más allá de su longitud de contexto incorporada (4096 tokens para los modelos Llama-2). Los modelos de lenguaje de visión también utilizan las mismas incrustaciones que las entradas.
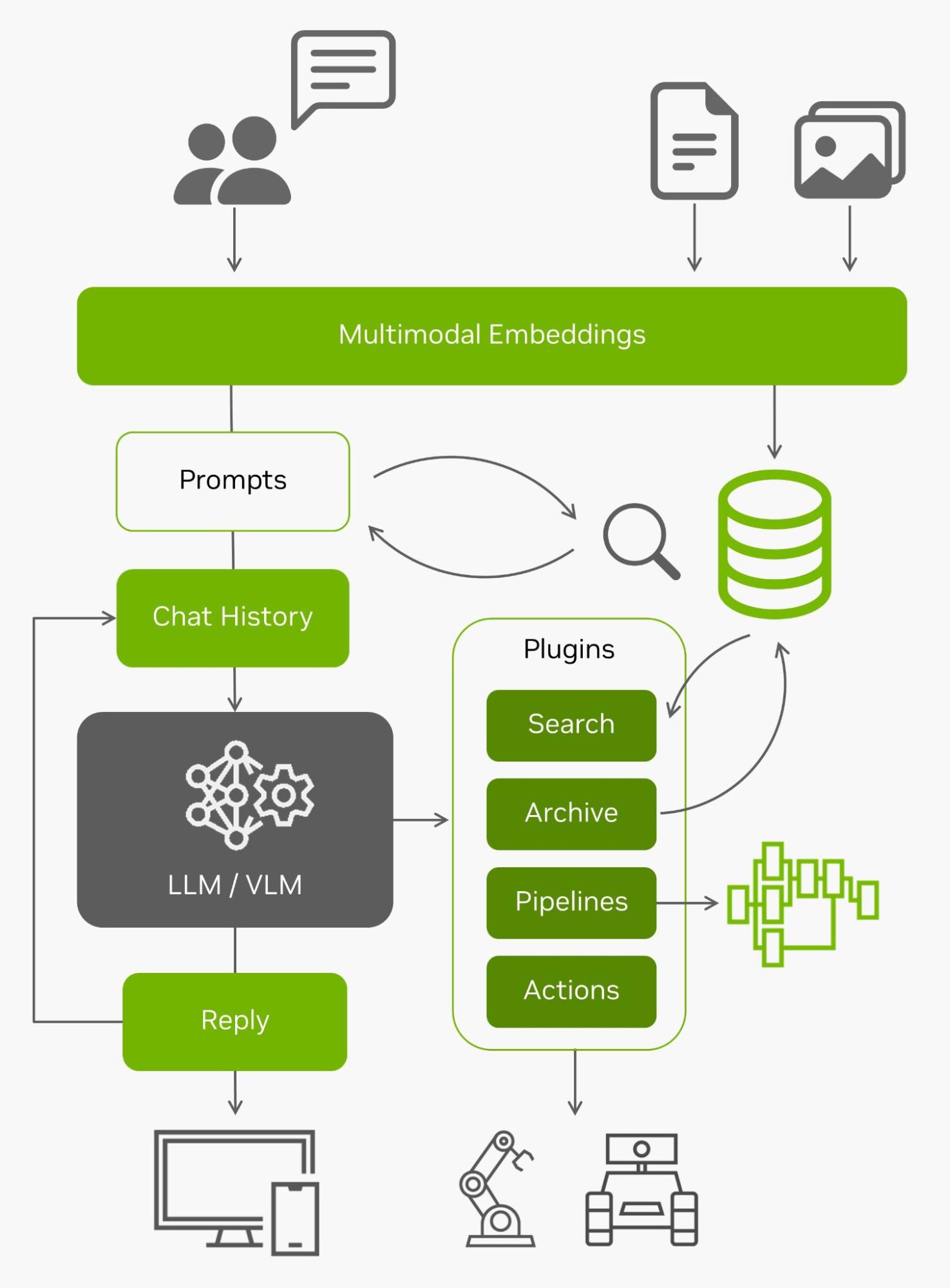
Con todos esos datos en vivo entrantes desde el edge y la capacidad de entenderlos, se convierten en agentes capaces de interactuar con el mundo real. Para obtener más información sobre cómo experimentar con el uso de NanoDB en sus propias imágenes y conjuntos de datos, consulte el tutorial de laboratorio.
Conclusión
¡Ahí lo tienes! Están surgiendo numerosas aplicaciones interesantes de IA generativa, y puedes ejecutarlas fácilmente en Jetson Orin siguiendo estos tutoriales. Para ser testigo de las increíbles capacidades de las IA generativas que se ejecutan localmente, explore el Jetson Generative AI Lab.
Si creas tu propia aplicación de IA generativa en Jetson y estás interesado en compartir tus ideas, asegúrate de mostrar tu creación en el foro de Jetson Projects.