
Por lo general, el código de simulación física en tiempo real se escribe en CUDA C++ de bajo nivel para obtener el máximo rendimiento. En esta publicación, presentamos NVIDIA Warp, un nuevo framework de Python que facilita la escritura de código de GPU de simulación y gráficos diferenciables en Python. Warp proporciona los componentes fundamentales necesarios para escribir código de simulación de alto rendimiento, pero con la productividad de trabajar en un lenguaje interpretado como Python.
Al final de esta publicación, aprenderás a usar Warp para crear kernels CUDA en tu entorno de Python y aprovechar algunas de las funciones de alto nivel integradas que facilitan la escritura de simulaciones físicas complejas, como una simulación de océanos (Figura 1).

Instalación
Warp está disponible como una biblioteca de código abierto de GitHub. Para descargar los paquetes de versión e instalarlos en tu entorno local de Python, sigue las instrucciones de README y usa el siguiente comando:
pip install .
Inicialización
Después de importar, debe inicializar explícitamente Warp:
import warp as wp
wp.init()
Lanzamiento de kernels
Warp utiliza el concepto de decoradores de Python para marcar funciones que se pueden ejecutar en la GPU. Por ejemplo, podría escribir un esquema de integración de partículas semiimplícitas, como se indica a continuación:
@wp.kernel
def integrate(x: wp.array(dtype=wp.vec3),
v: wp.array(dtype=wp.vec3),
f: wp.array(dtype=wp.vec3),
w: wp.array(dtype=float),
gravity: wp.vec3,
dt: float):
# thread id
tid = wp.tid()
x0 = x[tid]
v0 = v[tid]
# Semi-implicit Euler step
f_ext = f[tid] inv_mass = w[tid]
v1 = v0 + (f_ext * inv_mass + gravity) * dt
x1 = x0 + v1 * dt
# store results
x[tid] = x1
v[tid] = v1
Debido a que Warp está fuertemente tipado, debes proporcionar pistas de tipo a los argumentos del kernel. Para iniciar un kernel, usa la siguiente sintaxis:
wp.launch(kernel=simple_kernel, # kernel to launch
dim=1024, # number of threads
inputs=[a, b, c], # parameters
device="cuda") # execution device
A diferencia de los frameworks basados en tensor como NumPy, Warp utiliza un modelo de programación basado en kernel. La programación basada en kernel se equipara más de cerca con el modelo de ejecución de GPU subyacente. A menudo, es una forma más natural de expresar código de simulación que requiere operaciones detalladas de lógica condicional y de memoria. Sin embargo, Warp expone este modelo centrado en subprocesos de programación de una manera fácil de usar que no requiere un conocimiento de bajo nivel de la arquitectura de GPU.
Modelo de compilación
Al lanzar un kernel, se activa una proceso de compilación just-in-time (JIT) que genera automáticamente código del kernel C++/CUDA a partir de definiciones de funciones de Python.
Todos los kernels que pertenecen a un módulo Python se compilan en tiempo de ejecución en bibliotecas dinámicas y PTX. Figura 2. muestra el pipeline de compilación, que implica atravesar la función AST y convertir esto en código CUDA de línea recta que luego se compila y carga de nuevo en el proceso de Python.
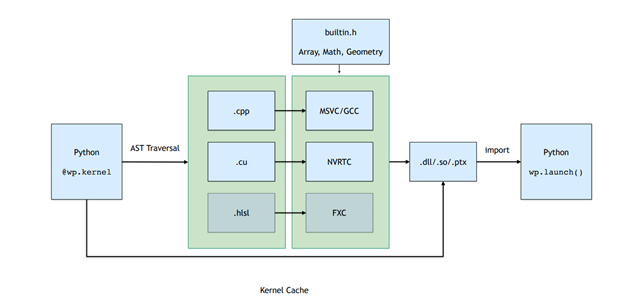
El resultado de esta compilación JIT se almacena en caché. Si el origen del kernel de entrada no cambia, los binarios precompilados se cargan de forma de bajo consumo general.
Modelo de memoria
Las asignaciones de memoria en Warp se exponen a través del tipo warp.array. Las matrices envuelven una asignación de memoria subyacente que puede estar en la memoria del host (CPU) o del dispositivo (GPU). A diferencia de los frameworks tensor, las matrices en Warp están fuertemente tipadas y almacenan una secuencia lineal de estructuras integradas (vec3, matrix33, quat, etc.).
Puede crear matrices a partir de listas de Python o matrices NumPy, o inicializadas, utilizando una sintaxis similar a NumPy y PyTorch:
# allocate an uninitizalized array of vec3s
v = wp.empty(length=n, dtype=wp.vec3, device="cuda")
# allocate a zero-initialized array of quaternions
q = wp.zeros(length=n, dtype=wp.quat, device="cuda")
# allocate and initialize an array from a numpy array
# will be automatically transferred to the specified device
v = wp.from_numpy(array, dtype=wp.vec3, device="cuda")
Warp admite los protocolos de __array_interface__ y __cuda_array_interface__, que permiten vistas de datos sin copia entre frameworks basados en tensor. Por ejemplo, para convertir datos a NumPy, usa el siguiente comando:
# automatically bring data from device back to host
view = device_array.numpy()
Funciones
Warp incluye varias estructuras de datos de mayor nivel que facilitan la implementación de algoritmos de simulación y procesamiento de geometría.
Mallas
Las mallas triangulares son omnipresentes en la simulación y los gráficos por computación. Warp proporciona un tipo integrado para administrar los datos de malla que admiten consultas geométricas, como las verificaciones de superposiciones, de emisión de rayos y de punto más cercano.
En el ejemplo siguiente se muestra cómo utilizar Warp para calcular el punto más cercano de una malla a una matriz de posiciones de entrada. Este tipo de computación es el componente fundamental para muchos algoritmos en la detección de colisiones (Figura 3). Las consultas de malla de Warp facilitan la implementación de tales métodos.

@wp.kernel
def project(positions: wp.array(dtype=wp.vec3),
mesh: wp.uint64,
output_pos: wp.array(dtype=wp.vec3),
output_face: wp.array(dtype=int)):
tid = wp.tid()
x = wp.load(positions, tid)
face_index = int(0)
face_u = float(0.0)
face_v = float(0.0)
sign = float(0.0)
max_dist = 2.0
if (wp.mesh_query_point(mesh, x, max_dist, sign, face_index, face_u, face_v)):
p = wp.mesh_eval_position(mesh, face_index, face_u, face_v)
output_pos[tid] = p
output_face[tid] = face_index
Volúmenes dispersos
Los volúmenes dispersos son increíblemente útiles para representar datos de cuadrícula en grandes dominios, como campos de distancia firmadas (SDF) para objetos complejos o velocidades para el flujo de fluidos a gran escala. Warp incluye compatibilidad para volúmenes dispersos definidos mediante el estándar NanoVDB. Construye volúmenes utilizando herramientas estándar de OpenVDB como Blender, Houdini o Maya, y luego muestra dentro de los kernels de Warp.
Puedes crear volúmenes directamente a partir de archivos de cuadrícula binarios en el disco o en la memoria, y luego probarlos utilizando la API de volúmenes:
wp.volume_sample_world(vol, xyz, mode) # world space sample using interpolation mode
wp.volume_sample_local(vol, uvw, mode) # volume space sample using interpolation mode
wp.volume_lookup(vol, ijk) # direct voxel lookup
wp.volume_transform(vol, xyz) # map point from voxel space to world space
wp.volume_transform_inv(vol, xyz) # map point from world space to volume space

Mediante las consultas de volúmenes, puedes colisionar de manera eficiente contra objetos complejos con una sobrecarga de memoria mínima.
Cuadrículas de hash
Muchos métodos de simulación basados en partículas, como el método de elementos discretos (DEM) o la hidrodinámica de partículas suavizadas (SPH), implican la iteración en vecinos espaciales para calcular interacciones de fuerza. Las cuadrículas de hash son una estructura de datos bien establecida para acelerar estas consultas de vecino más cercanas y se adaptan especialmente a la GPU.
Las cuadrículas de hash se construyen a partir de conjuntos de puntos como se indica a continuación:
grid = wp.HashGrid(dim_x=128, dim_y=128, dim_z=128, device="cuda")
grid.build(points=p, radius=r)
Cuando se crean cuadrículas de hash, puede consultarlas directamente desde el código del kernel del usuario, como se muestra en el ejemplo siguiente, que calcula la suma de todas las posiciones de partículas vecinos:
@wp.kernel
def sum(grid : wp.uint64,
points: wp.array(dtype=wp.vec3),
output: wp.array(dtype=wp.vec3),
radius: float):
tid = wp.tid()
# query point
p = points[tid]
# create grid query around point
query = wp.hash_grid_query(grid, p, radius)
index = int(0)
sum = wp.vec3()
while(wp.hash_grid_query_next(query, index)):
neighbor = points[index]
# compute distance to neighbor point
dist = wp.length(p-neighbor)
if (dist <= radius):
sum += neighbor
output[tid] = sum
La Figura 5 muestra un ejemplo de una simulación de materiales granulares de DEM para un material cohesivo. El uso de la estructura de datos de hash-grid incorporada te permite escribir dicha simulación en menos de 200 líneas de Python y se ejecuta a velocidades interactivas para más de 100,000 partículas.

El uso de los datos de la cuadrícula de hash warp te permite evaluar fácilmente las interacciones de fuerza en el par entre las partículas vecinos.
Diferenciabilidad
Los frameworks basados en Tensor, como PyTorch y JAX, proporcionan gradientes de computaciones de tensor y son muy adecuados para aplicaciones como el entrenamiento de ML.
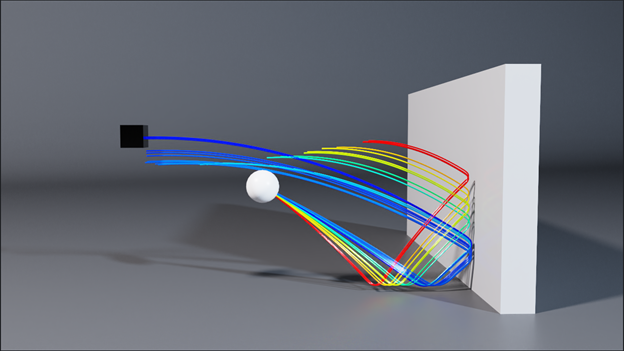
Una característica única de Warp es la capacidad de generar versiones anteriores y posteriores del código del kernel. Esto facilita la escritura de simulaciones diferenciables que pueden propagar gradientes como parte de un proceso de entrenamiento más grande. Un escenario común es utilizar frameworks de ML tradicionales para capas de red, y Warp para implementar capas de simulación que permitan una diferenciabilidad integral.
Cuando se requieren gradientes, debes crear matrices con requires_grad =True. Por ejemplo, la clase warp.Tape puede grabar lanzamientos de kernel y reproducirlos para calcular el gradiente de una función de pérdida escalar con respecto a las entradas del kernel:
tape = wp.Tape()
# forward pass
with tape:
wp.launch(kernel=compute1, inputs=[a, b], device="cuda")
wp.launch(kernel=compute2, inputs=[c, d], device="cuda")
wp.launch(kernel=loss, inputs=[d, l], device="cuda")
# reverse pass
tape.backward(loss=l)
Después de completar la pasada hacia atrás, los gradientes con respecto a las entradas están disponibles a través de una asignación en el objeto Tape:
# gradient of loss with respect to input a
print(tape.gradients[a])
Resumen
En esta publicación, presentamos NVIDIA Warp, un framework de Python que facilita la escritura de código de GPU de simulación y gráficos diferenciables en Python. Te recomendamos que descargues la versión preliminar de Warp, compartas los resultados y nos brindes tus comentarios.
Para obtener más información, consulta los siguientes recursos:
- Página del producto Warp
- Repositorio de GitHub para NVIDIA/warp
- Documentación de Warp
- Warp: Un Framework Python de Alto Rendimiento para la Simulación de GPU y los GráficosSesión de GTC
- Simulación Física Diferenciable para el Aprendizaje y la RobóticaSesión de GTC (PDF)