
Todo modelo de IA revolucionario comienza de la misma manera: con una ejecución de entrenamiento. La infraestructura que respalda esos trabajos de entrenamiento lo determina todo: la rapidez con la que los equipos pueden iterar, la escala del modelo que pueden construir y si esos trabajos se completan de manera confiable.
A medida que los modelos crecen en tamaño, complejidad e inteligencia, las exigencias sobre la infraestructura de entrenamiento también aumentan.
En MLPerf Training 6.0 —el más reciente de una serie de rigurosos benchmarks de la industria revisados por pares para evaluar el rendimiento del entrenamiento de IA— la plataforma NVIDIA Blackwell lideró en todas las categorías, demostrando:
- El tiempo de entrenamiento más rápido en todos los benchmarks
- Entrenamiento a la mayor escala con 8.192 GPUs usando sistemas NVIDIA Blackwell NVL72
- La única plataforma con envíos en los siete benchmarks del conjunto
NVIDIA combina rendimiento, escala y confiabilidad en una sola plataforma diseñada mediante un codesign extremo, para permitir que los desarrolladores de modelos de IA lancen modelos de frontera más rápido, minimicen los costos de entrenamiento y comiencen a generar ingresos antes.
Rendimiento: El Tiempo de Entrenamiento Más Rápido en Todos los Benchmarks
MLPerf Training 6.0 agregó dos nuevas cargas de trabajo de preentrenamiento de mixture-of-experts (MoE) al conjunto: DeepSeek-V3 671B y GPT-OSS-20B, lo que refleja la creciente centralidad de las arquitecturas MoE. La plataforma NVIDIA fue la única presentada en todos los benchmarks y entregó el tiempo de entrenamiento más rápido en los siete.

En esta ronda, NVIDIA envió resultados tanto en sistemas rack-scale NVIDIA GB200 NVL72 como GB300 NVL72. Dentro de cada sistema rack-scale, los NVLink Switches de quinta generación de NVIDIA conectan las 72 GPUs con alto ancho de banda en un grupo unificado de cómputo y memoria, lo que les permite actuar como una sola GPU gigante.
El entrenamiento MoE a gran escala enfrenta el mismo desafío de comunicación all-to-all que la inferencia MoE —los tokens deben enrutarse entre GPUs para llegar a la sub-red de expertos correcta— y la ventaja de ancho de banda de NVLink es lo que hace que eso sea rápido y eficiente a escala.
NVIDIA también presentó métodos de entrenamiento NVFP4 que aumentan el rendimiento mientras cumplen con estrictos requisitos de precisión en cargas de trabajo de preentrenamiento a gran y pequeña escala, así como cargas de trabajo de ajuste fino. NVIDIA continúa impulsando la innovación en entrenamiento de baja precisión en diferentes arquitecturas de modelos, utilizando más recientemente NVFP4 para preentrenar el masivo modelo NVIDIA Nemotron 3 Ultra de 550 mil millones de parámetros.
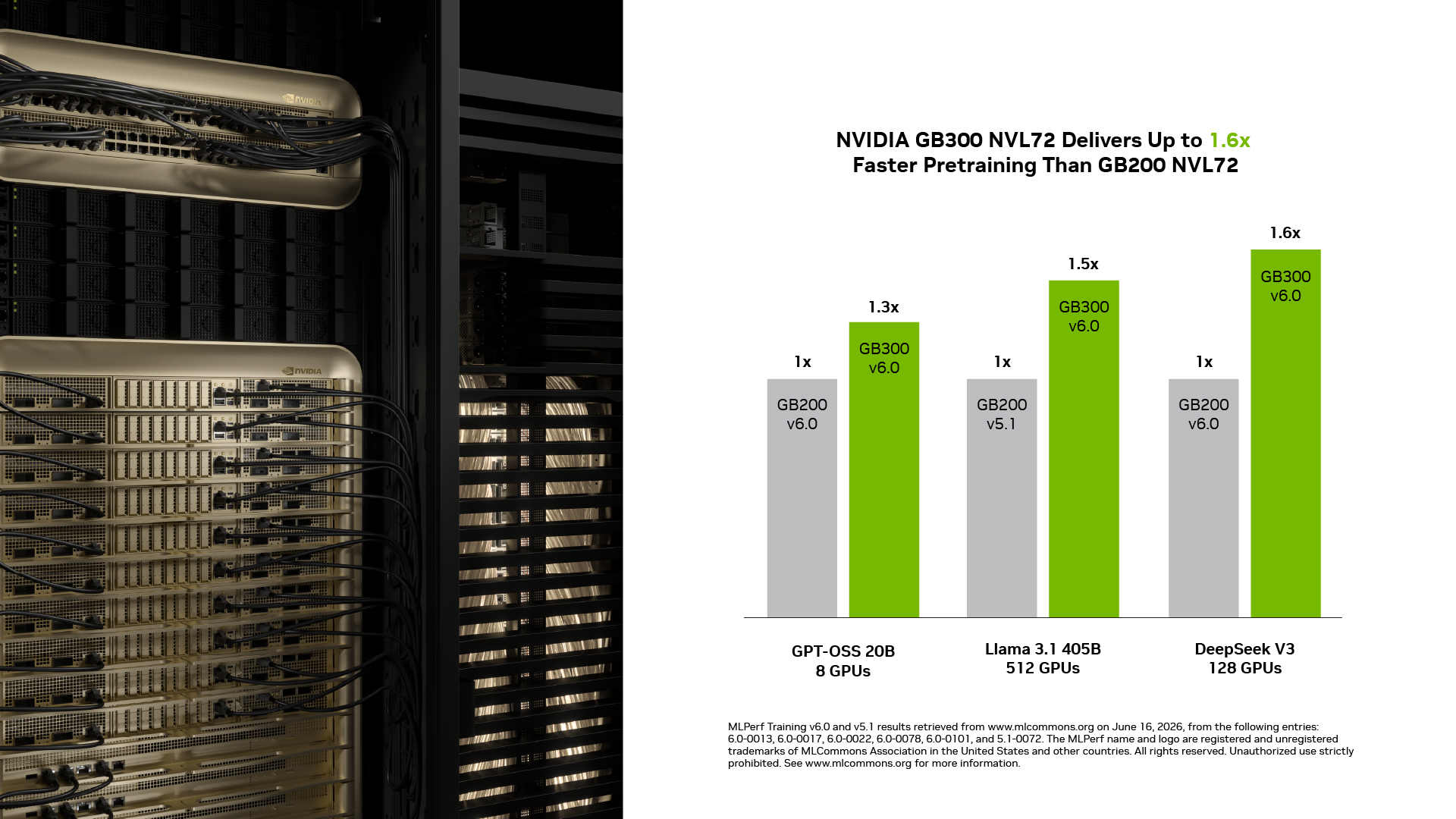
NVIDIA GB300 NVL72 entregó hasta 1,6x de rendimiento sobre GB200 NVL72: En esta ronda, el GB300 NVL72 entregó un entrenamiento hasta 1,6x más rápido que el GB200 NVL72 a la misma escala. Las capacidades clave de Blackwell Ultra, como mayor densidad de cómputo con NVFP4, mayor capacidad de memoria y un límite de energía más alto que permite a la GPU mantener el rendimiento máximo, impulsan esta mejora.
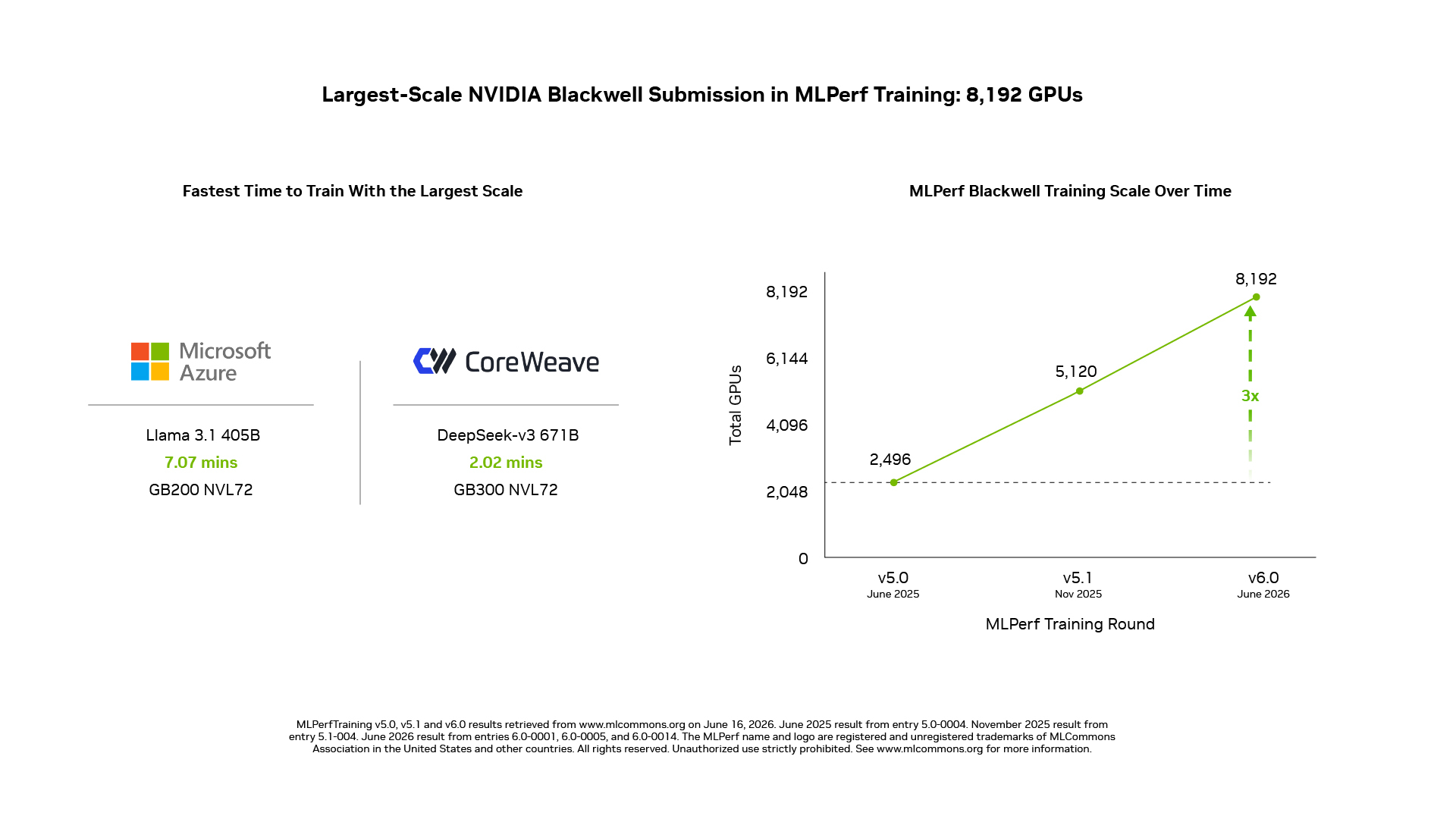
Escala: El Clúster Blackwell Más Grande en MLPerf Training
Para soportar el entrenamiento distribuido a escala, NVIDIA ofrece dos plataformas de redes scale-out complementarias —NVIDIA Quantum InfiniBand y NVIDIA Spectrum-X Ethernet— que dan a los centros de datos la flexibilidad para construir clústeres a gran escala optimizados para su infraestructura.
En DeepSeek-V3 671B, el modelo MoE más grande del conjunto, NVIDIA escaló su envío a 8.192 GPUs usando sistemas GB200 NVL72, el envío basado en Blackwell a mayor escala en MLPerf Training hasta la fecha.
NVIDIA también envió resultados con 5.120 GPUs en sistemas NVIDIA GB200 NVL72 para Llama 3.1 405B, uno de los LLMs densos más grandes del conjunto.
Los resultados de esta ronda también reflejan la profunda co-ingeniería entre NVIDIA y sus socios en arquitectura de sistemas, redes y software:
- Microsoft Azure escaló el entrenamiento de Llama 3.1 405B a 8.192 GPUs usando sistemas GB200 NVL72, y alcanzó el objetivo de calidad de referencia en 7,07 minutos, el tiempo de entrenamiento más rápido para este benchmark.
- CoreWeave entregó el tiempo de entrenamiento más rápido para DeepSeek-V3 671B, alcanzando el objetivo de calidad en 2,02 minutos a escala de 8.192 GPUs usando sistemas GB300 NVL72 conectados con redes Spectrum-X Ethernet.
Confiabilidad a Escala: Diseñado para Producción
En entornos de entrenamiento en producción, las ejecuciones pueden abarcar semanas o meses en cientos de miles de GPUs. A esa escala, el rendimiento efectivo del entrenamiento depende tanto del rendimiento del sistema como de la resiliencia que lo hace reproducible con el tiempo.
Los resultados de MLPerf Training v6.0 anteriores hablan del rendimiento de la plataforma de NVIDIA. En cuanto a la resiliencia, la plataforma de NVIDIA está diseñada en dos dimensiones:
- Menos interrupciones: Las GPUs NVIDIA están construidas para evitar fallas antes de que ocurran. Antes de que una GPU llegue a un centro de datos, NVIDIA la somete a más de 30 etapas de pruebas de fabricación para detectar posibles fallas de forma temprana. Una vez implementado, el Reliability, Availability and Serviceability Engine monitorea casi todo el chip, y las capacidades de autocorrección enrutan automáticamente alrededor de las fallas detectadas sin interrumpir la carga de trabajo. A nivel de red, Spectrum-X Ethernet redirige alrededor de los enlaces fallidos en milisegundos, manteniendo el fabric en buen estado sin interrumpir el trabajo.
- Recuperación más rápida cuando ocurren interrupciones: NVIDIA Resiliency Extension, o NVRx, minimiza el tiempo perdido cuando ocurren fallas, con capacidades que abarcan detección de fallas, recuperación y monitoreo de estado en todo el clúster. Detecta y gestiona automáticamente los nodos de bajo rendimiento antes de que ralenticen al resto del clúster. Cuando un nodo experimenta una interrupción, en lugar de reiniciar todo el trabajo, el sistema reanuda desde un checkpoint reciente, es decir, una instantánea guardada del estado de entrenamiento.
IA de Frontera Construida Sobre NVIDIA
Los socios del ecosistema NVIDIA también participaron ampliamente en esta ronda, con envíos de 19 organizaciones, incluidas ASUSTeK, Microsoft Azure, Cisco, CoreWeave, Dell Technologies, Fujitsu, Giga Computing, Google Cloud, Hewlett Packard Enterprise, Inventec, Krai, Lambda, Nebius, Netweb Technologies India Ltd., Quanta Cloud Computing (QCT), Scitix, Supermicro y TTA. Muchos de estos socios ejecutan algunas de las cargas de trabajo de entrenamiento de IA más exigentes en la infraestructura de NVIDIA.
CoreWeave, que aloja su infraestructura NVIDIA dentro de sistemas Dell PowerRack con servidores Dell PowerEdge, es hogar de varias de estas cargas de trabajo. Cohere logró un entrenamiento 3x más rápido en GB200 NVL72 para su plataforma de IA agéntica North. Midjourney, que entrenó su modelo de generación de imágenes v8 en un clúster Blackwell, ahora está escalando una gran flota de GPUs Blackwell Ultra en CoreWeave para entrenar próximos modelos de imagen y video.
En Google Cloud, Thinking Machines Lab vio velocidades de entrenamiento y servicio 2x más rápidas en GB300 NVL72 en comparación con GPUs de generación anterior, acelerando la investigación de modelos de frontera y los flujos de trabajo de aprendizaje por refuerzo.
Nebius, ejecutando infraestructura NVIDIA Blackwell y Blackwell Ultra en su nube de IA, permitió a Higgsfield reducir el tiempo de entrenamiento de modelos en un 30%, apoyando una plataforma que ahora atiende a 22 millones de usuarios y genera más de 6 millones de contenidos de IA por día.
Para un análisis técnico más profundo de los resultados de MLPerf Training 6.0 y las optimizaciones detrás de ellos, lea este blog técnico.
