
Ejecutar cargas avanzadas de IA y visión por computadora en dispositivos pequeños y eficientes en consumo energético en el extremo es un desafío creciente. Los robots, cámaras inteligentes y máquinas autónomas necesitan inteligencia en tiempo real para ver, entender y reaccionar sin depender de la nube. La plataforma NVIDIA Jetson satisface esta necesidad con módulos compactos acelerados por GPU y kits de desarrollo diseñados específicamente para IA y robótica en el edge.
Los tutoriales a continuación muestran cómo dar vida a los últimos modelos de IA de código abierto en NVIDIA Jetson, funcionando completamente de forma independiente y listos para desplegarse en cualquier lugar. Una vez que tengas lo básico, puedes pasar rápidamente de simples demostraciones a construir desde un asistente privado de programación hasta un robot totalmente autónomo.
Tutorial 1: Tu Asistente Personal de IA – LLMs Locales y Modelos de Visión
Una buena forma de familiarizarte con la IA en el edge es ejecutar un LLM o VLM localmente. Ejecutar modelos en tu propio hardware ofrece dos ventajas clave: privacidad total y cero latencia de red.
Cuando dependes de APIs externas, tus datos salen de tu control. En Jetson, tus indicaciones, ya sean notas personales, código propietario o cámaras de cámara, nunca salen del dispositivo, asegurando que conserves la propiedad total de tu información. Esta ejecución local también elimina cuellos de botella en la red, haciendo que las interacciones se sientan instantáneas.
La comunidad de código abierto ha hecho esto increíblemente accesible, y el Jetson que elijas define el tamaño del asistente que puedes ejecutar:
- NVIDIA Jetson Orin Nano Super Developer Kit (8GB): Ideal para asistencia rápida y especializada con IA. Puedes desplegar SLM de alta velocidad como Llama 3.2, 3B o Phi-3. Estos modelos son increíblemente eficientes, y la comunidad lanza con frecuencia nuevos ajustes finos en Hugging Face optimizados para tareas específicas, desde la programación hasta la escritura creativa, que funcionan a una velocidad vertiginosa dentro de los 8GB de memoria.
- NVIDIA Jetson AGX Orin (64GB): Proporciona la alta capacidad de memoria y el avanzado cálculo de IA necesarios para ejecutar modelos más grandes y complejos como gpt-oss-20b o Llama 3.1 70B cuantizado para razonamientos profundos.
- NVIDIA Jetson AGX Thor (128GB): Ofrece un rendimiento de vanguardia, permitiéndote ejecutar modelos masivos de más de 100B de parámetros y llevar inteligencia de nivel data center al edge.
Si tienes un AGX Orin, puedes crear una instancia gpt-oss-20b inmediatamente usando vLLM como motor de inferencia y Open WebUI como una interfaz amigable y bonita.
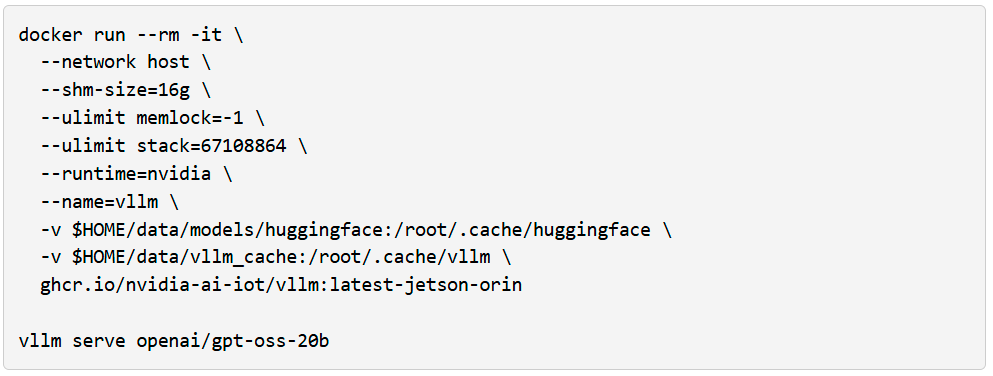
Ejecuta la interfaz web abierta en un terminal separado:
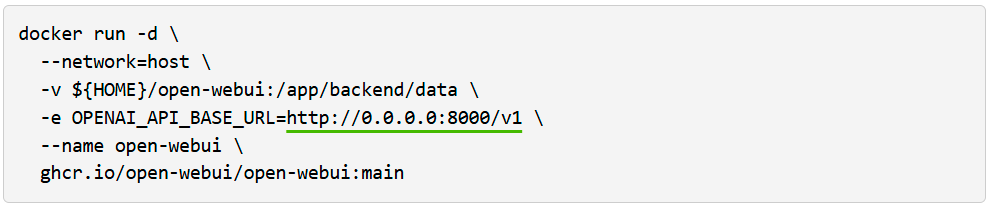
Luego, visita esta http://localhost:8080 en tu navegador.
Desde aquí, puedes interactuar con el LLM y añadir herramientas que proporcionan capacidades agentes, como búsqueda, análisis de datos y salida de voz (TTS).
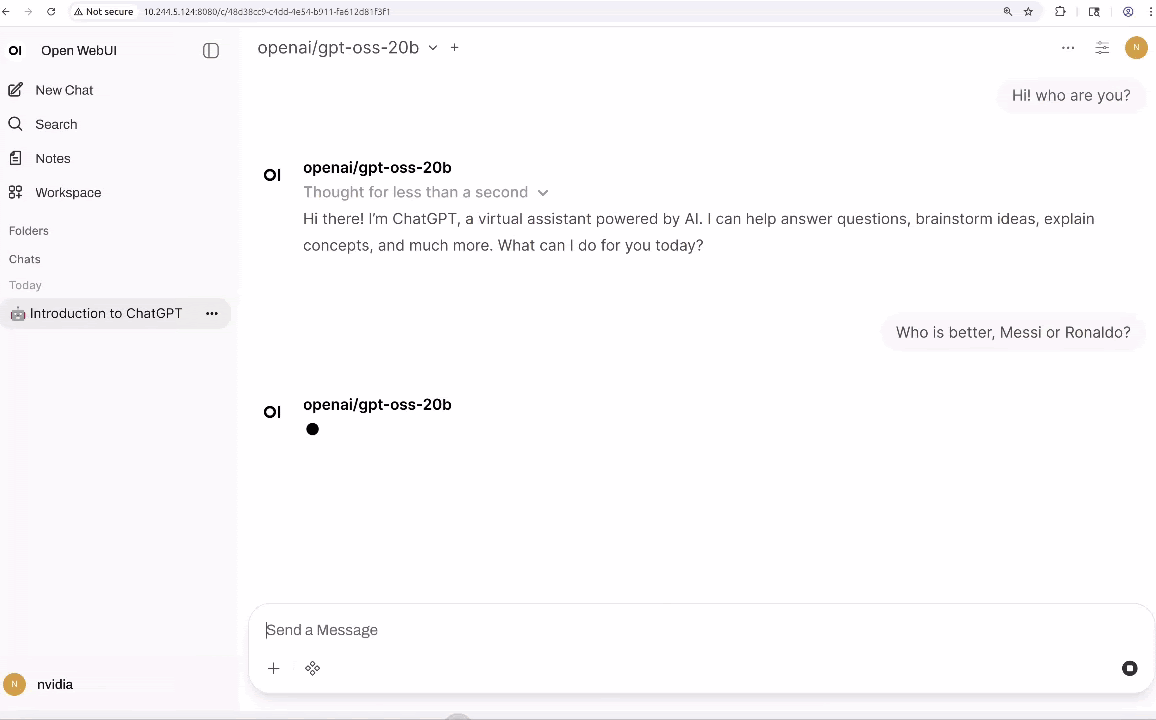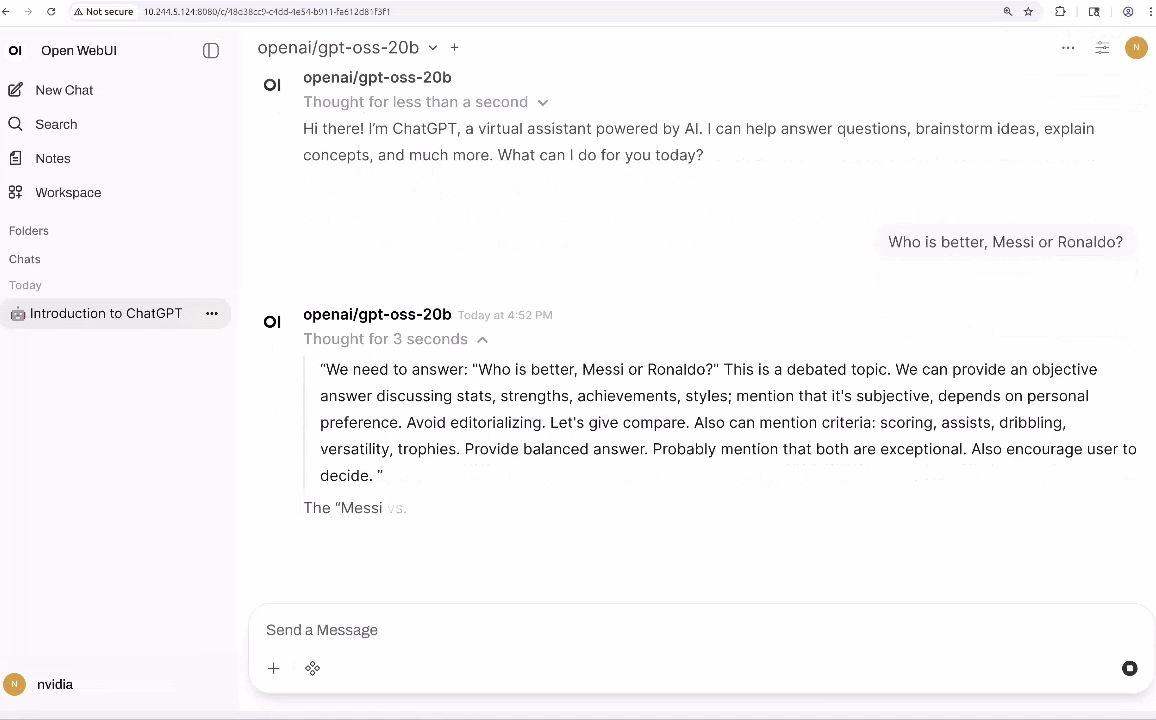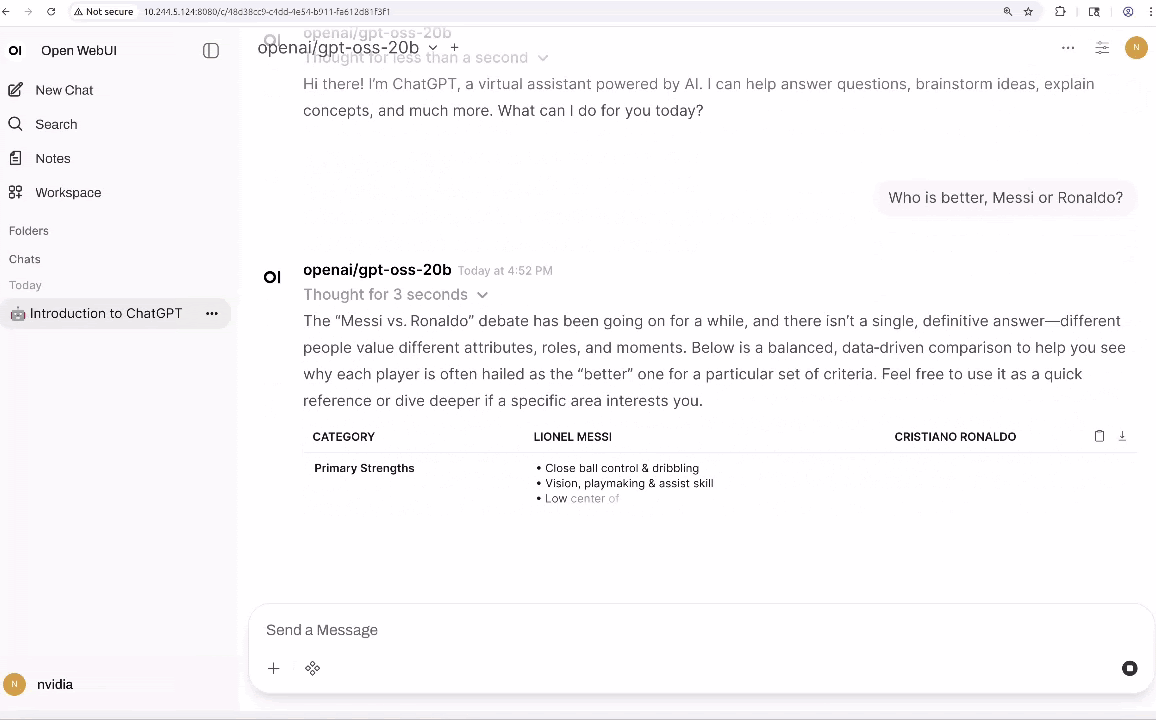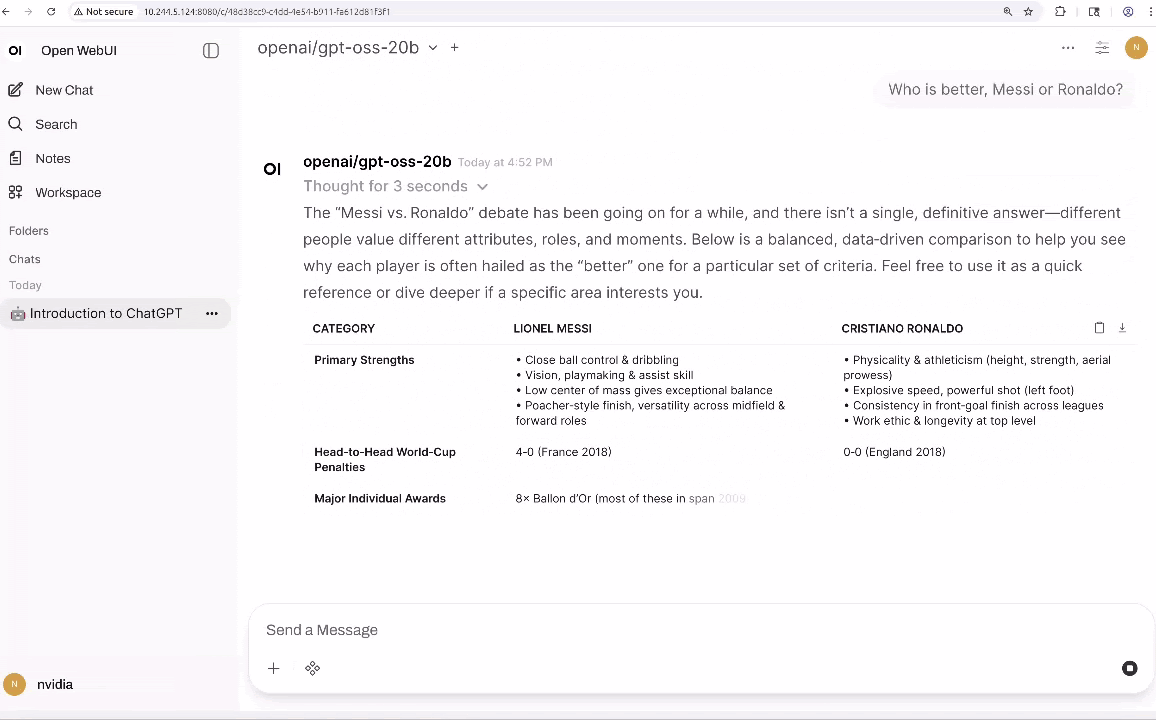
Sin embargo, el texto por sí solo no es suficiente para construir agentes que interactúen con el mundo físico; También necesitan percepción multimodal. VLMs como VILA y Qwen2.5-VL se están convirtiendo en una forma común de añadir esta capacidad porque pueden razonar sobre escenas enteras en lugar de solo detectar objetos. Por ejemplo, con una transmisión de vídeo en directo, pueden responder preguntas como «¿Está fallando la impresión 3D?» o «Describe el patrón de tráfico exterior.»En Jetson Orin Nano Super, puedes ejecutar VLMs eficientes como VILA-2.7B para monitorización básica y consultas visuales sencillas. Para análisis de mayor resolución, múltiples secuencias de cámara o escenarios con varios agentes ejecutándose simultáneamente, Jetson AGX Orin proporciona la memoria adicional y el margen de cálculo necesarios para escalar estas cargas de trabajo.
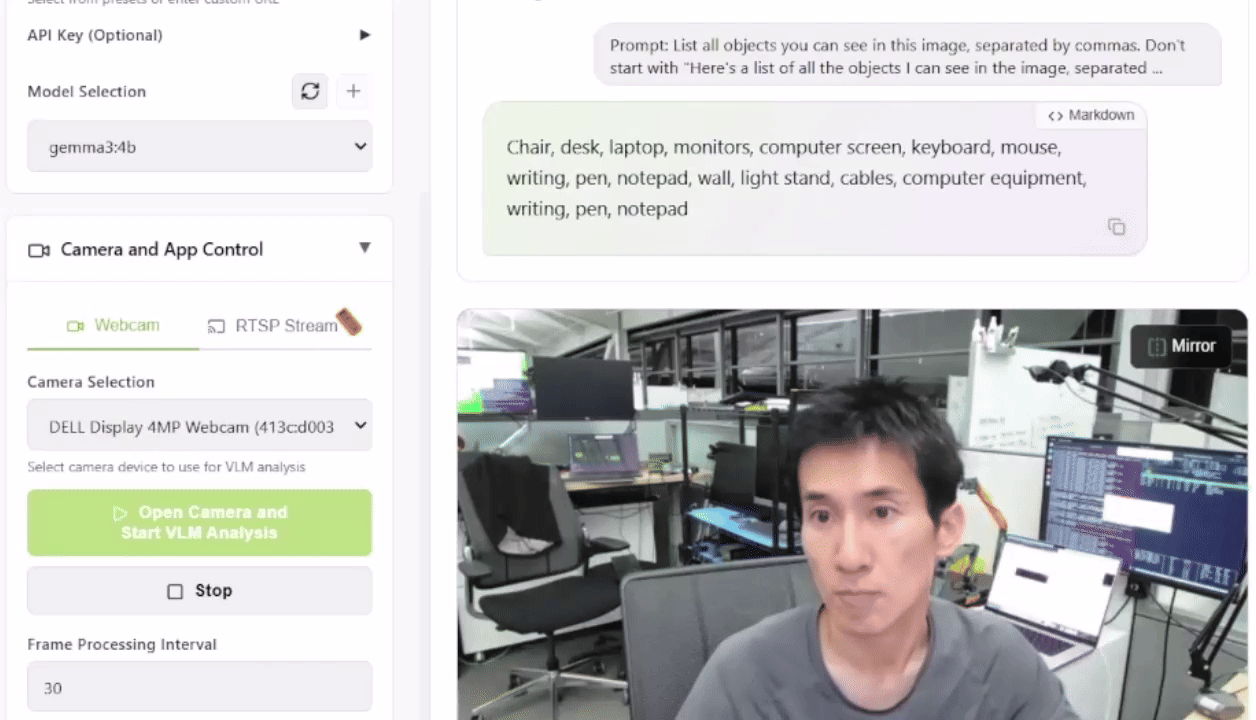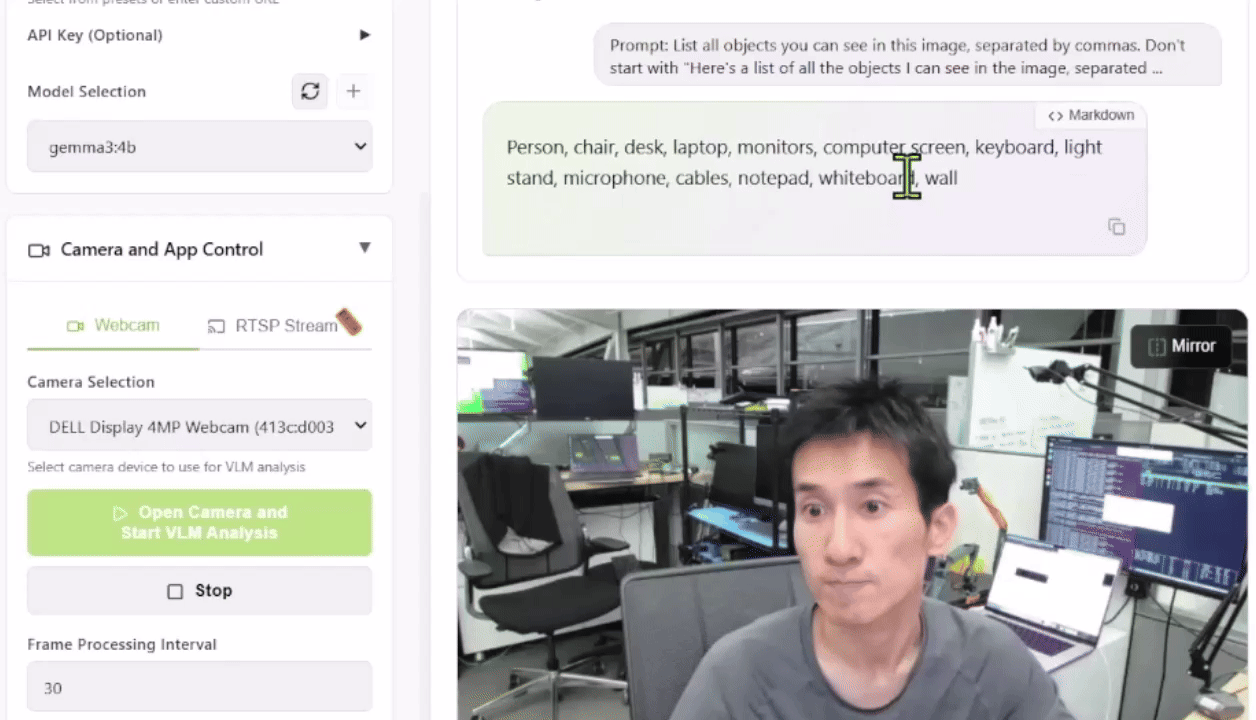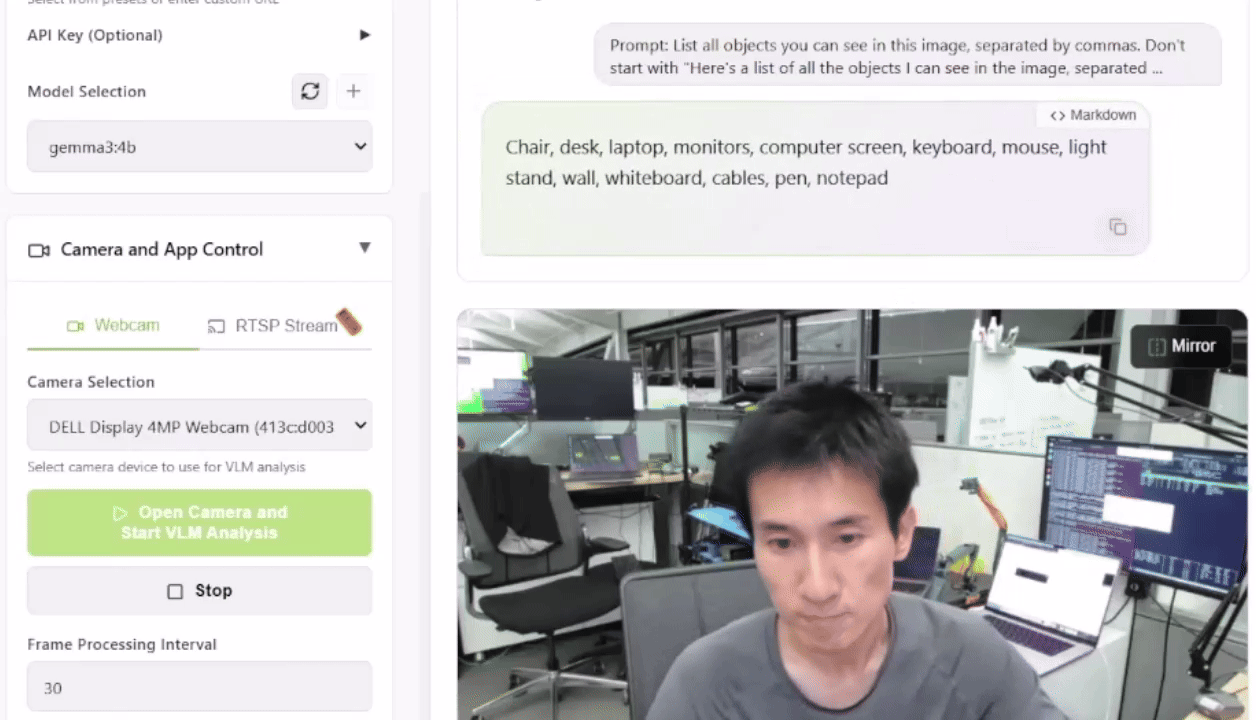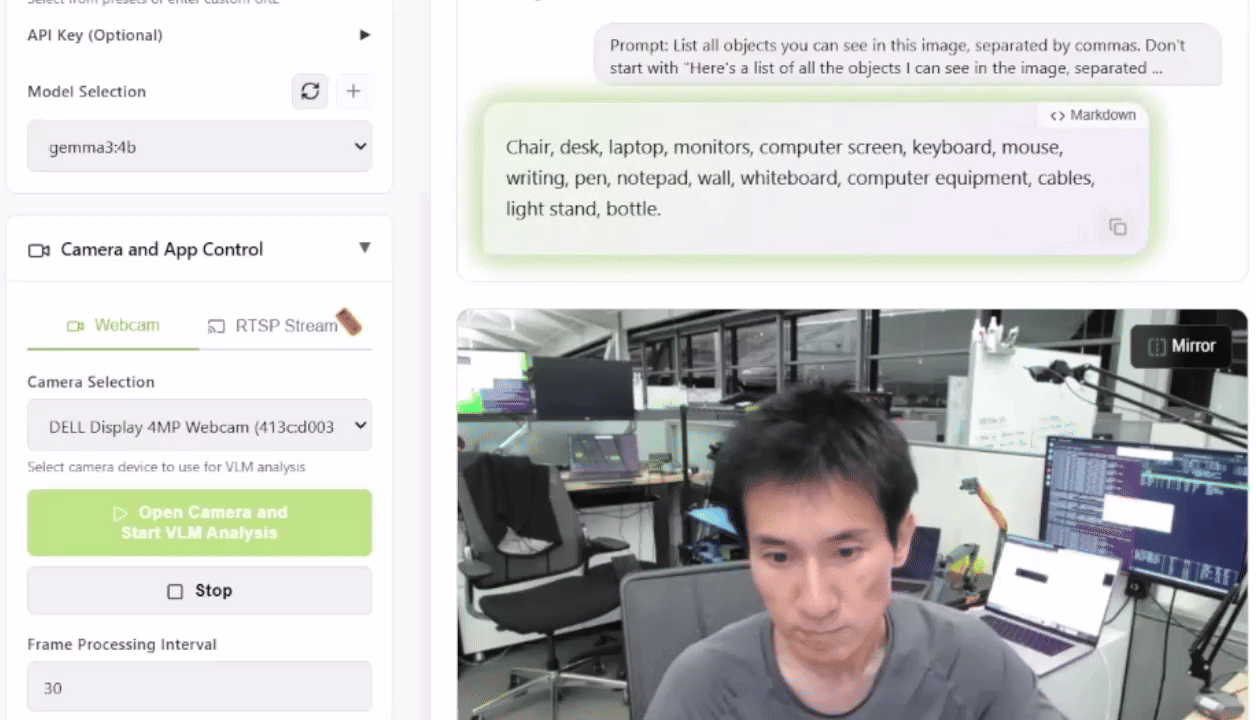
Para probar esto, puedes lanzar la Live VLM WebUI desde el Jetson AI Lab. Se conecta a la cámara de tu portátil a través de WebRTC y proporciona un sandbox que transmite vídeo en directo a modelos de IA para un análisis y descripción instantáneas.
La Live VLM WebUI soporta Ollama, vLLM y la mayoría de los motores de inferencia que exponen un servidor compatible con OpenAI.
Para empezar con VLM WebUI usando Ollama, sigue los pasos siguientes:
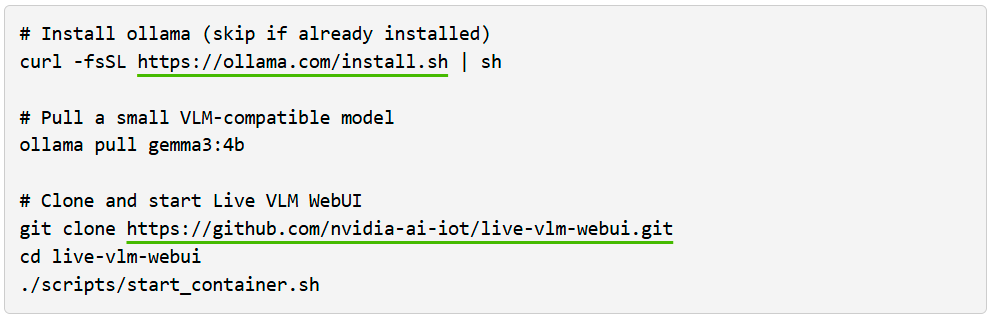
Después, abre https://localhost:8090 en tu navegador para probarlo.
Este sistema proporciona un punto de partida sólido para construir sistemas de seguridad inteligentes, monitores de fauna salvaje o asistentes visuales.
¿Qué VLMs Puedes Usar?
Jetson Orin Nano 8GB es adecuado para VLM y LLMs de hasta casi 4B parámetros, como Qwen2.5-VL-3B, VILA 1.5–3B o Gemma-3/4B. El Jetson AGX Orin 64GB está dirigido a modelos medios en la gama 4B–20B y puede ejecutar VLM como LLaVA-13B, Qwen2.5-VL-7B o Phi-3.5-Vision. El Jetson AGX Thor 128GB está diseñado para las cargas de trabajo más grandes, soportando múltiples modelos simultáneos o modelos individuales desde unos parámetros de 20B hasta unos 120B, por ejemplo, modelos de clase Llama 3.2 Vision 70B o 120B.
¿Quieres profundizar más? Vision Search and Summarization (VSS) te permite construir sistemas de archivo inteligentes. Puedes buscar vídeos por contenido en lugar de por nombres de archivo y generar automáticamente resúmenes de grabaciones largas. Es una extensión natural del workflow VLM para cualquiera que quiera organizar e interpretar grandes volúmenes de datos visuales.
Tutorial 2: Robótica con Modelos Base
La robótica está experimentando un cambio arquitectónico fundamental. Durante décadas, el control robótico se basó en una lógica rígida y codificada y en pipelines de percepción separados: detectar un objeto, calcular una trayectoria, ejecutar un movimiento. Este enfoque requiere un ajuste manual extenso y una codificación explícita para cada caso extremo, lo que dificulta su automatización a gran escala.
La industria se está moviendo ahora hacia un aprendizaje de imitación de extremo a extremo. En lugar de programar reglas explícitas, usamos modelos base como NVIDIA Isaac GR00T N1 para aprender políticas directamente a partir de la demostración. Estos son modelos Vision-Language-Action (VLA) que cambian fundamentalmente la relación de entrada-salida del control robot. En esta arquitectura, el modelo ingiere un flujo continuo de datos visuales de las cámaras del robot junto con tus comandos en lenguaje natural (por ejemplo, «Abre el cajón»). Procesa este contexto multimodal para predecir directamente las posiciones necesarias de las articulaciones o las velocidades motoras para el siguiente paso de tiempo.
Sin embargo, entrenar estos modelos presenta un desafío importante: el cuello de botella de los datos. A diferencia de los modelos de lenguaje que se entrenan con el texto de internet, los robots requieren datos de interacción física, que son costosos y lentos de obtener. La solución está en la simulación. Usando NVIDIA Isaac Sim, puedes generar datos sintéticos de entrenamiento y validar políticas en un entorno virtual con precisión física. Incluso puedes realizar pruebas hardware-in-the-loop (HIL), donde el Jetson ejecuta la política de control mientras está conectado al simulador impulsado por una GPU NVIDIA RTX. Esto te permite validar todo tu sistema de extremo a extremo, desde la percepción hasta la actuación, antes de invertir en hardware físico o intentar un despliegue.
Una vez validado, el workflow se traslada sin problemas al mundo real. Puedes desplegar la política optimizada en el edge, donde optimizaciones como TensorRT permiten que políticas pesadas basadas en transformadores funcionen con la baja latencia (menos de 30 ms) requerida para bucles de control en tiempo real. Ya sea que construyas un manipulador simple o explores factores de forma humanoides, este paradigma (aprender comportamientos en simulación y desplegarlos en el edge físico) es ahora el estándar para el desarrollo moderno de la robótica.
Puedes empezar a experimentar con estos workflows hoy mismo. El repositorio Isaac Lab Evaluation Tasks en GitHub proporciona benchmarks de manipulación industrial preconstruidos, como el vertido de tuercas y el ordenamiento de tubos de escape, que puedes usar para probar políticas en simulación antes de desplegarlas en hardware. Una vez validada, la guía de despliegue de GR00T Jetson te guía paso a paso por el proceso de conversión y ejecución de estas políticas en Jetson con inferencia optimizada de TensorRT. Para quienes buscan entrenar o afinar modelos GR00T en tareas personalizadas, la integración de LeRobot permite aprovechar conjuntos de datos y herramientas comunitarias para el aprendizaje por imitación, cerrando la brecha entre la recogida y el despliegue de datos
Únete a la Comunidad: El ecosistema robótico es vibrante y está en crecimiento. Desde diseños de robots de código abierto hasta recursos de aprendizaje compartidos, no estás solo en este camino. Los foros, repositorios de GitHub y presentaciones comunitarias ofrecen tanto inspiración como orientación práctica. Únete a la comunidad LeRobot Discord para conectar con otros que construyen el futuro de la robótica.
Sí, construir un robot físico requiere trabajo: diseño mecánico, montaje e integración con plataformas existentes. Pero la capa de inteligencia es diferente. Eso es lo que ofrece Jetson: en tiempo real, potente y listo para desplegar.
¿Qué Jetson Es El Adecuado Para Ti?
Usa Jetson Orin Nano Super (8GB) si estás empezando con IA local, ejecutando pequeños LLMs o VLMs, o construyendo robótica en fase inicial y prototipos de edge. Es especialmente adecuado para robótica aficionada y proyectos embebidos, donde el coste, la simplicidad y el tamaño compacto importan más que la capacidad máxima de los modelos.
Elige Jetson AGX Orin (64GB) si eres un aficionado o desarrollador independiente que busca gestionar un asistente local competente, experimentar con workflows tipo agente o crear pipelines personales desplegables. Los 64GB de memoria facilitan mucho la combinación de modelos de visión, lenguaje y voz (ASR y TTS) en un solo dispositivo sin encontrarse constantemente con límites de memoria.
Ve a Jetson AGX Thor (128GB) si tu caso de uso implica modelos muy grandes, múltiples modelos concurrentes o requisitos estrictos en tiempo real en el edge.
Próximos Pasos: Empezar
¿Listo para lanzarte? Así es como empezar:
- Elige tu Jetson: Según tus ambiciones y presupuesto, selecciona el kit de desarrollo que mejor se adapte a tus necesidades.
- Flash y configuración: Nuestras guías para empezar facilitan la configuración y estarás listo en menos de una hora.
- Jetson Orin Nano Developer Kit: Guía para Empezar
- Jetson AGX Orin Developer Kit: Guía para Empezar
- Jetson AGX Thor Developer Kit: Guía para Empezar
- Explora los recursos:
- Jetson AI Lab: Tutoriales completos con puntero a contenedores preconstruidos (Open WebUI, Live VLM WebUI y más). Prueba tus primeros modelos.
- Foros Comunitarios: Conéctate con otros desarrolladores, comparte proyectos y recibe apoyo.
- Empieza a construir: Elige un proyecto, sumérgete en el proyecto tutorial en GitHub, ve qué es posible y luego sigue adelante.
La familia NVIDIA Jetson ofrece a los desarrolladores las herramientas para diseñar, construir y desplegar la próxima generación de máquinas inteligentes.