
La inferencia, el trabajo de aprovechar la IA en aplicaciones, se está adoptando en los usos más importantes y se está ejecutando más rápido que nunca.
Las GPUs de NVIDIA ganaron todas las pruebas de inferencia de IA en data centers y sistemas de computación de edge en la última ronda de las únicas evaluaciones revisadas por pares y basadas en consorcios de la industria.
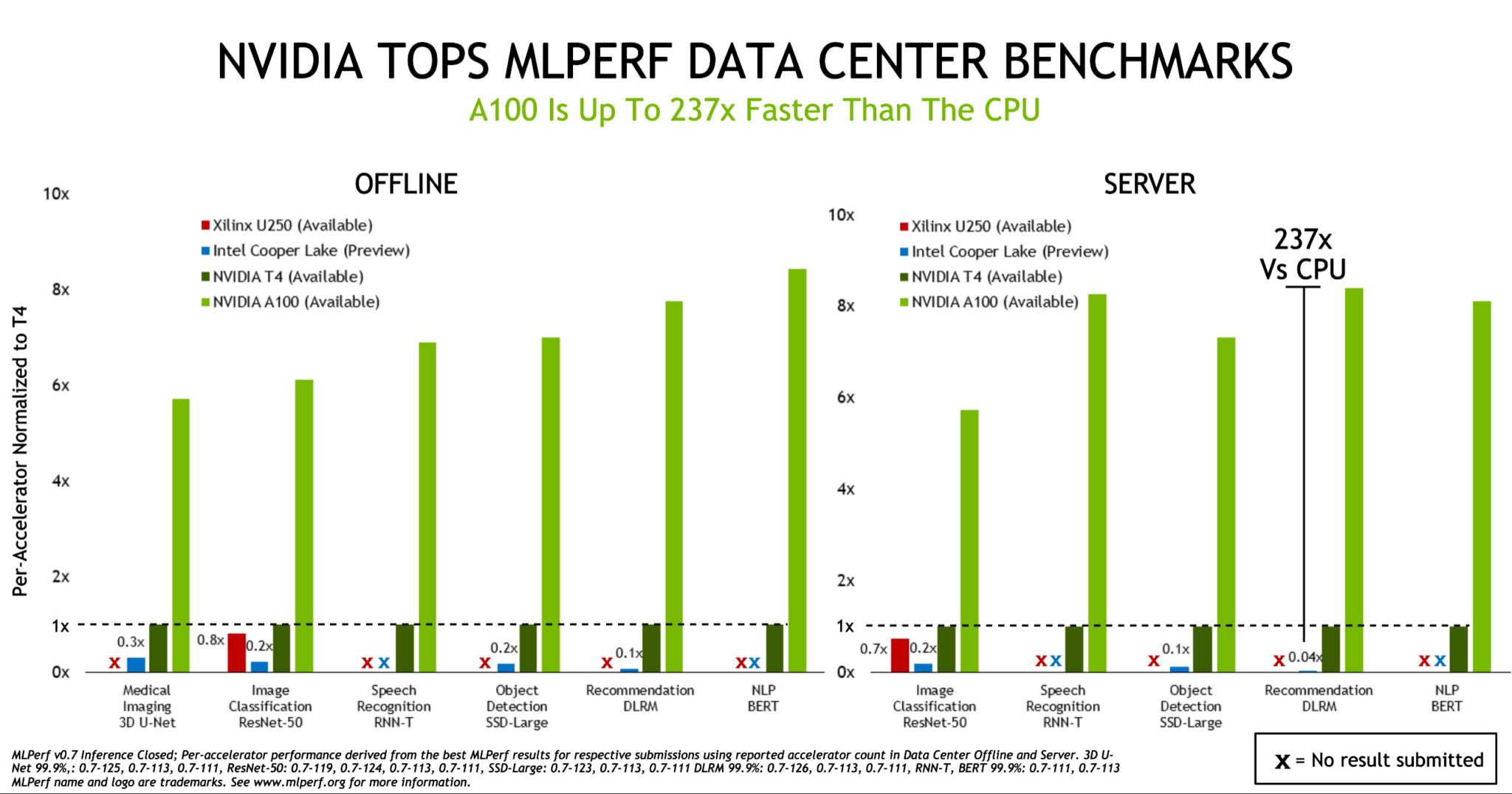
Las GPUs NVIDIA A100 Tensor Core ampliaron el liderazgo en rendimiento que demostramos en las primeras evaluaciones de inferencia de IA realizadas el año pasado por MLPerf, un consorcio de evaluación comparativa de la industria formado en mayo de 2018.
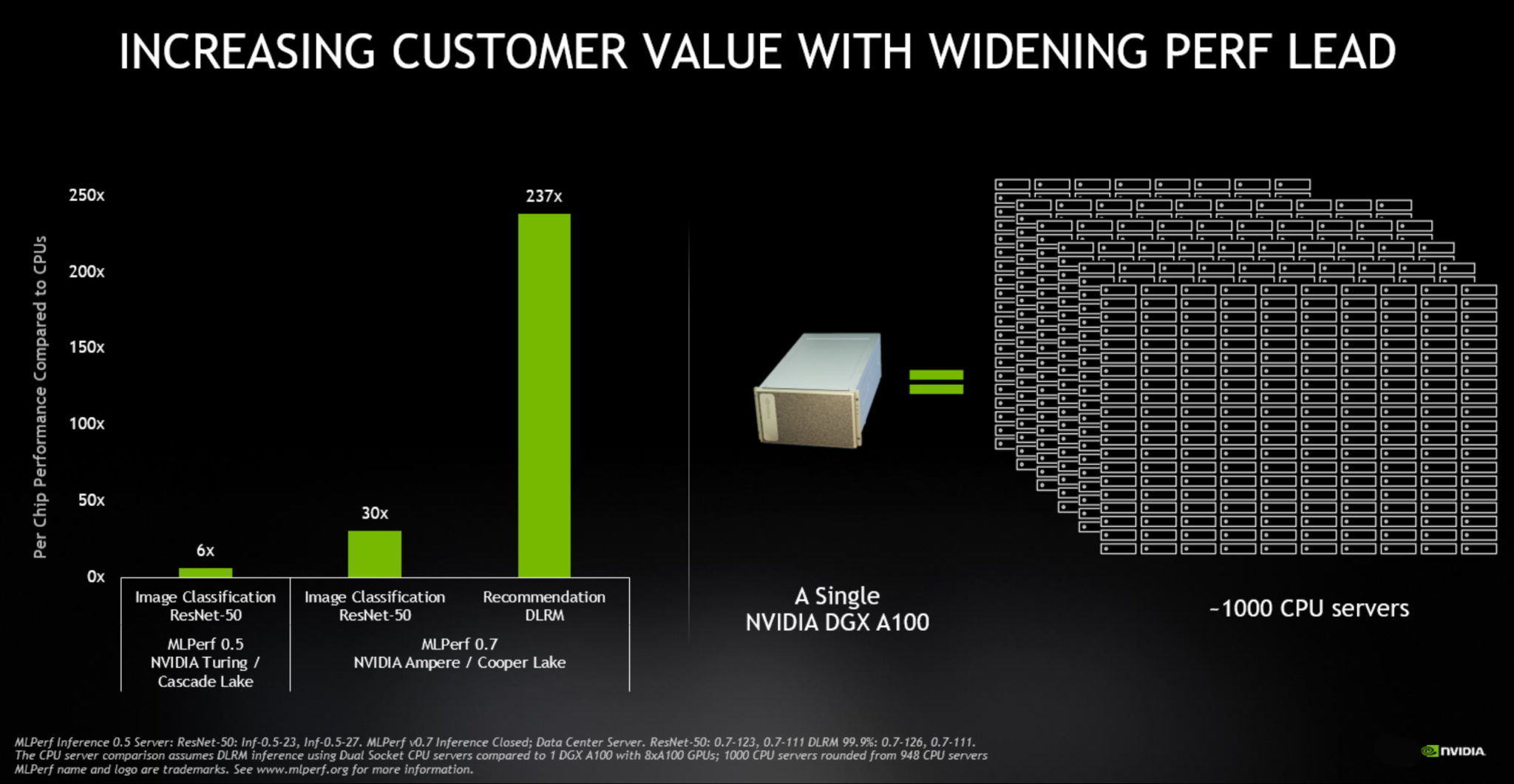
La A100, presentada en mayo, superó a las CPUs hasta en 237 veces en la inferencia de data centers, de acuerdo con las evaluaciones MLPerf Inference 0.7. Las GPU NVIDIA T4, de tamaño pequeño y de bajo consumo, superan a las CPU hasta 28 veces en las mismas pruebas.
Para poner esto en perspectiva, un solo sistema NVIDIA DGX A100 con ocho GPUs A100 ahora proporciona el mismo rendimiento que casi 1000 servidores de CPU de doble socket en algunas aplicaciones de IA.
En esta ronda de evaluaciones también se vio una mayor participación, ya que incluyó 23 organizaciones, en comparación con las 12 de la edición anterior. Además, los socios de NVIDIA utilizaron la plataforma de IA de NVIDIA para impulsar más del 85 por ciento del total de presentaciones.
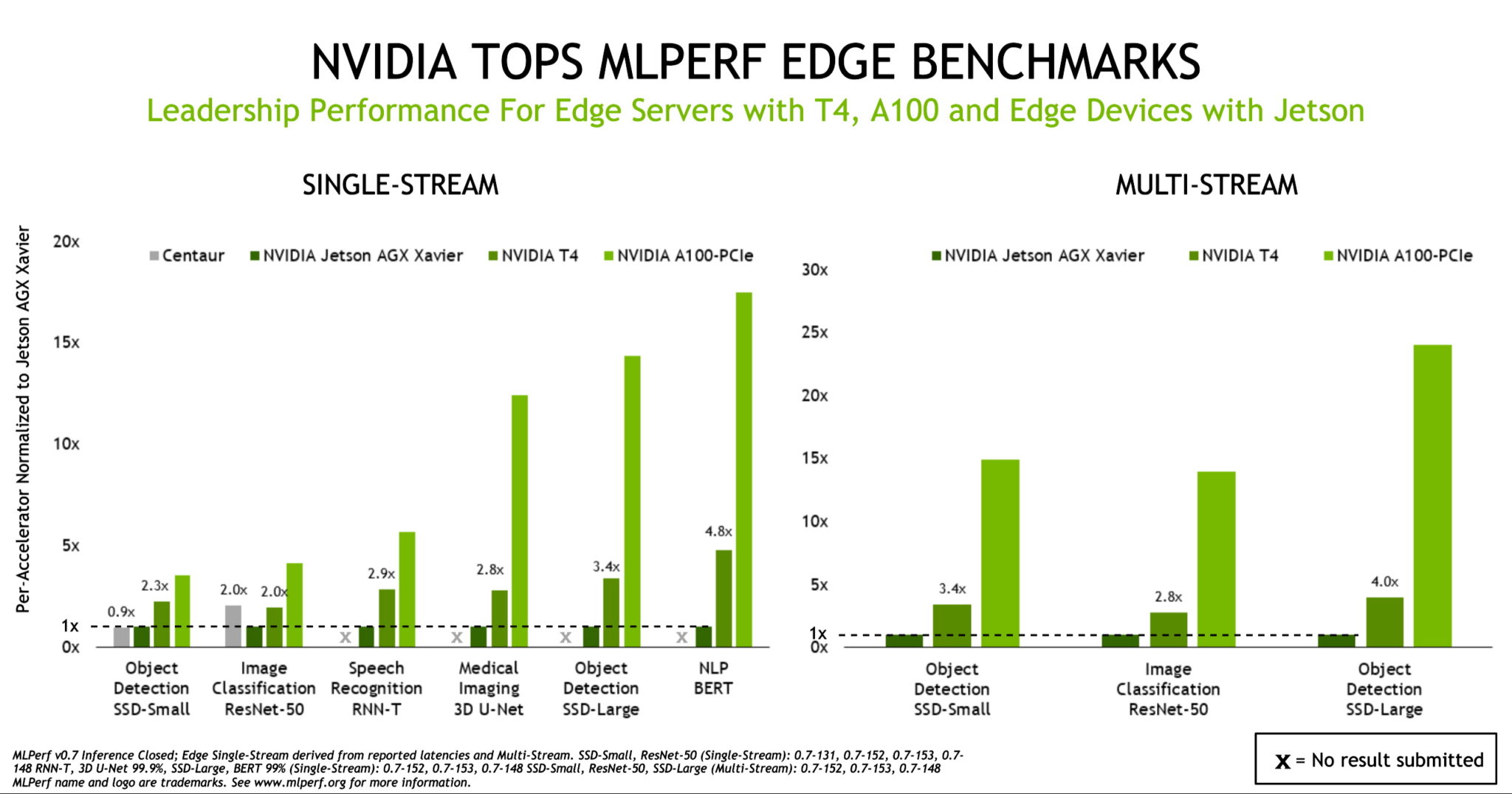
Las GPU A100 y Jetson AGX Xavier Llevan el Rendimiento al Edge
Si bien A100 está llevando el rendimiento de la inferencia de IA a nuevas alturas, las evaluaciones muestran que T4 sigue siendo una plataforma de inferencia sólida para la empresa convencional, los servidores de edge y las instancias de cloud rentables. Además, NVIDIA Jetson AGX Xavier se basa en su posición de liderazgo en dispositivos de edge basados en SoC que tienen limitaciones de energía, ya que son compatibles con todos los casos de uso nuevos.
Los resultados también apuntan a nuestro vibrante y creciente ecosistema de IA, que presentó 1,029 resultados utilizando soluciones de NVIDIA. Esto representa el 85 por ciento del total de las participaciones en las categorías de data center y edge. Las presentaciones demostraron un rendimiento sólido en todos los sistemas de socios como Altos, Atos, Cisco, Dell EMC, Dividiti, Fujitsu, Gigabyte, Inspur, Lenovo, Nettrix y QCT.
Los Casos de Uso en Expansión Llevan la IA a la Vida Diaria
Las evaluaciones de MLPerf continúan evolucionando para representar casos de uso de la industria, gracias al amplio apoyo de la industria y el mundo académico. Las organizaciones que apoyan a MLPerf incluyen Arm, Baidu, Facebook, Google, Harvard, Intel, Lenovo, Microsoft, Stanford, la Universidad de Toronto y NVIDIA.
Las evaluaciones más recientes introdujeron cuatro nuevas pruebas, lo que destaca el panorama en expansión de la IA. El conjunto ahora evalúa el rendimiento en procesamiento de idiomas naturales, generación de imágenes médicas, sistemas de recomendación y reconocimiento de voz, así como casos de uso de IA en visión de computación.
No necesitas ir más allá de un motor de búsqueda para ver el impacto del procesamiento de idiomas naturales en la vida diaria.
“Los recientes avances de la IA en la comprensión de idiomas naturales aumentan la naturalidad en la interacción con más y más servicios de IA, como Bing. Esto brinda resultados, respuestas y recomendaciones precisas y útiles en menos de un segundo”, dijo Rangan Majumder, vicepresidente de búsqueda e inteligencia artificial de Microsoft.
“Las evaluaciones MLPerf estándar de la industria proporcionan datos de rendimiento relevantes en redes de IA ampliamente utilizados y ayudan a tomar decisiones informadas de compra de plataformas de IA”, dijo.
La IA Ayuda a Salvar Vidas en la Pandemia
El impacto de la IA en las imágenes médicas es aún más impactante. Por ejemplo, la startup Caption Health usa la IA para facilitar el trabajo de realizar ecocardiogramas, una capacidad que ayudó a salvar vidas en hospitales de EE. UU., al comienzo de la pandemia del COVID-19.
Es por eso que los líderes de opinión en IA para el cuidado de la salud ven los modelos como 3D U-Net, que se utilizaron en las últimas evaluaciones de MLPerf, como habilitadores clave.
“Hemos trabajado en estrecha colaboración con NVIDIA para llevar innovaciones como 3D U-Net al mercado de la salud”, dijo Klaus Maier-Hein, director de computación de imágenes médicas en DKFZ, el Centro Alemán de Investigación del Cáncer.
“La visión de computación y las imágenes son el núcleo de la investigación de la IA, impulsan el descubrimiento científico y representan los componentes centrales de la atención médica. Además, las evaluaciones MLPerf estándar de la industria proporcionan datos de rendimiento relevantes que ayudan a las organizaciones de TI y los desarrolladores a acelerar sus proyectos y aplicaciones específicos”, agregó.
Comercialmente, los casos de uso de IA como los sistemas de recomendación, que también forman parte de las últimas pruebas de MLPerf, ya están teniendo un gran impacto. Alibaba utilizó sistemas de recomendación en noviembre pasado para realizar transacciones por $ 38,000 millones en ventas en línea durante el Día de los Solteros, su mayor día de compras del año.
La Adopción de la Inferencia de IA de NVIDIA Supera el Punto de Inflexión
La inferencia de IA superó un hito importante este año.
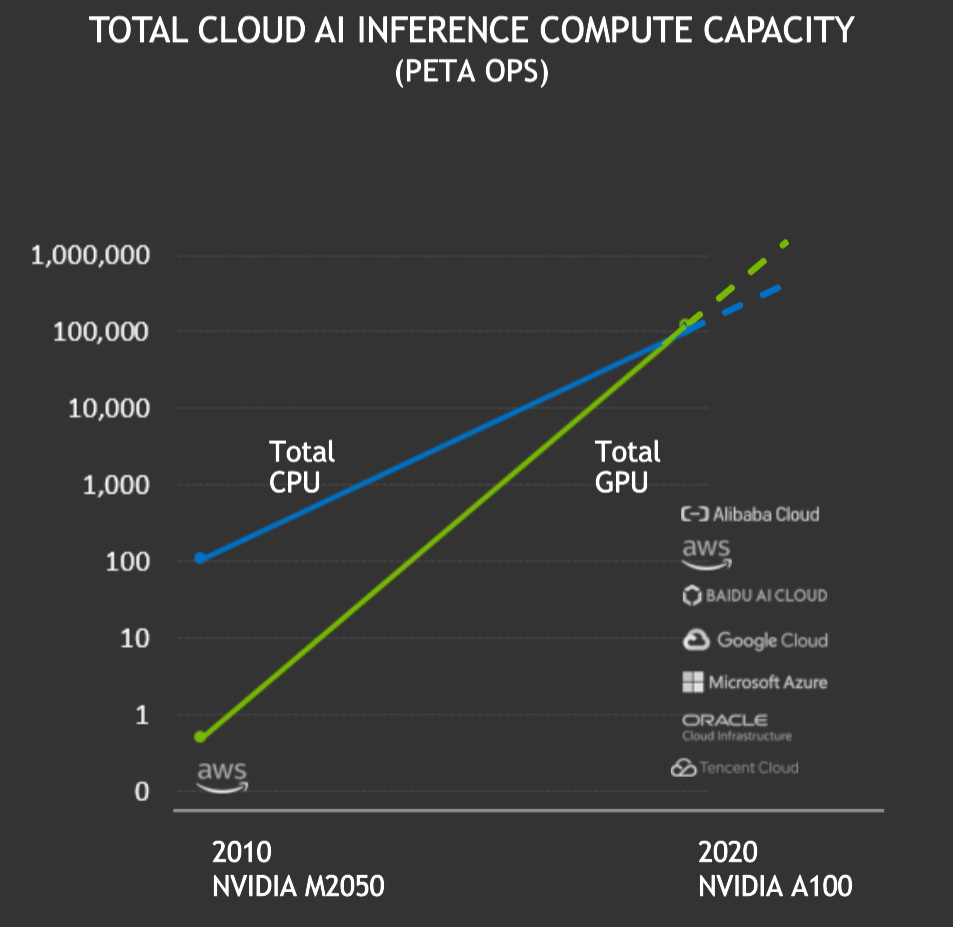
Las GPU NVIDIA entregaron un total de más de 100 exaflops de rendimiento de inferencia de IA en la instancia de cloud pública durante los últimos 12 meses. Esto superó la inferencia en las CPU de cloud por primera vez. La capacidad de computación total de inferencia de IA en cloud en las GPU de NVIDIA se ha multiplicado por diez cada dos años.
Con el alto rendimiento, la usabilidad y la disponibilidad de la computación con GPU de NVIDIA, un conjunto creciente de empresas de industrias como la automotriz, el cloud, la robótica, la atención médica, el comercio minorista, los servicios financieros y la manufactura ahora confían en las GPU de NVIDIA para la inferencia de IA. Entre ellas se encuentran American Express, BMW, Capital One, Domino’s, Ford, GE Healthcare, Kroger, Microsoft, Samsung y Toyota.

Por Qué la Inferencia de IA es Difícil
Los casos de uso de la IA claramente se están expandiendo, pero la inferencia de la IA es difícil de lograr por muchas razones.
Constantemente se generan nuevos tipos de redes neuronales, como las redes generativas adversarias, para nuevos casos de uso. Además, los modelos están creciendo exponencialmente. Los mejores modelos de lenguajes para la IA ahora abarcan miles de millones de parámetros, y la investigación en el campo recién empieza.
Estos modelos deben ejecutarse en cloud, en data centers empresariales y en el edge de la red. Eso significa que los sistemas que los ejecutan deben ser altamente programables, ya que se llevan a cabo de forma excelente en muchas dimensiones.
El fundador y director ejecutivo de NVIDIA, Jensen Huang, resumió las complejidades en una sigla: PLASTER. La inferencia de IA moderna requiere excelencia en Programabilidad, Latencia, Exactitud, Tamaño de modeloa, Tasa de transferencia, Eficiencia energética y Tasa de aprendizaje.
Para impulsar la excelencia en todas las dimensiones, nos enfocamos en la evolución constante de nuestra plataforma de IA integral para manejar trabajos de inferencia exigentes.
La IA Requiere Rendimiento y Usabilidad
Un acelerador como el A100, con sus Tensor Cores de tercera generación y la flexibilidad de su arquitectura de GPU múlti-instancias, es solo el comienzo. La entrega de resultados de liderazgo requiere un conjunto de software completo.
El software de IA de NVIDIA comienza con una variedad de modelos previamente entrenados que están listos para ejecutar la inferencia de IA. Nuestro Kit de Herramientas de Transfer Learning permite a los usuarios optimizar estos modelos para sus casos de uso y conjuntos de datos particulares.
NVIDIA TensorRT optimiza los modelos entrenados para la inferencia. Cuenta con 2,000 optimizaciones, y ha sido descargado 1.3 millones de veces por 16,000 organizaciones.
El Servidor de Inferencia NVIDIA Triton proporciona un entorno optimizado para ejecutar estos modelos de IA que admiten múltiples GPU y frameworks. Las aplicaciones simplemente envían la consulta y las restricciones, como el tiempo de respuesta que necesitan o el rendimiento para escalar a miles de usuarios, y Triton se encarga del resto.
Estos elementos se ejecutan en CUDA-X AI, un conjunto maduro de bibliotecas de software basado en nuestra popular plataforma de computación acelerada.
Cómo Acelerar el Uso de los Frameworks de Aplicaciones
Finalmente, nuestros frameworks de aplicaciones impulsan la adopción de la IA empresarial en diferentes industrias y casos de uso.
Nuestros frameworks incluyen NVIDIA Merlin para sistemas de recomendación, NVIDIA Jarvis para la IA conversacional, NVIDIA Maxine para la videoconferencia, NVIDIA Clara para la atención médica y muchos otros disponibles en la actualidad.
Estos frameworks, junto con nuestras optimizaciones para los últimos benchmarks de MLPerf, están disponibles en NGC, nuestro centro para el software acelerado por GPU que se ejecuta en todos los sistemas OEM y servicios de cloud certificados por NVIDIA.
De esta manera, el arduo trabajo que hemos realizado beneficia a toda la comunidad.