Cuando solicitamos a la IA generativa que responda a una pregunta o cree una imagen, los grandes modelos de lenguaje generan tokens de inteligencia que se combinan para proporcionar el resultado.
Un prompt. Un conjunto de tokens para la respuesta. A esto se le llama inferencia de IA
La IA basada en agentes utiliza el razonamiento para completar tareas. Los agentes de IA no se limitan a dar respuestas puntuales. Dividen las tareas en una serie de pasos, cada uno de los cuales es una técnica de inferencia diferente.
Un mensaje. Muchos conjuntos de tokens para completar el trabajo.
Los motores de la inferencia de IA se denominan fábricas de IA: infraestructuras masivas que sirven de IA a millones de usuarios a la vez.
Las fábricas de IA generan tokens de IA. Su producto es la inteligencia. En la era de la IA, esta inteligencia aumenta los ingresos y las ganancias. El crecimiento de los ingresos a lo largo del tiempo depende de la eficiencia que pueda tener la fábrica de IA a medida que escala.
Las fábricas de IA son las máquinas de la próxima revolución industrial.

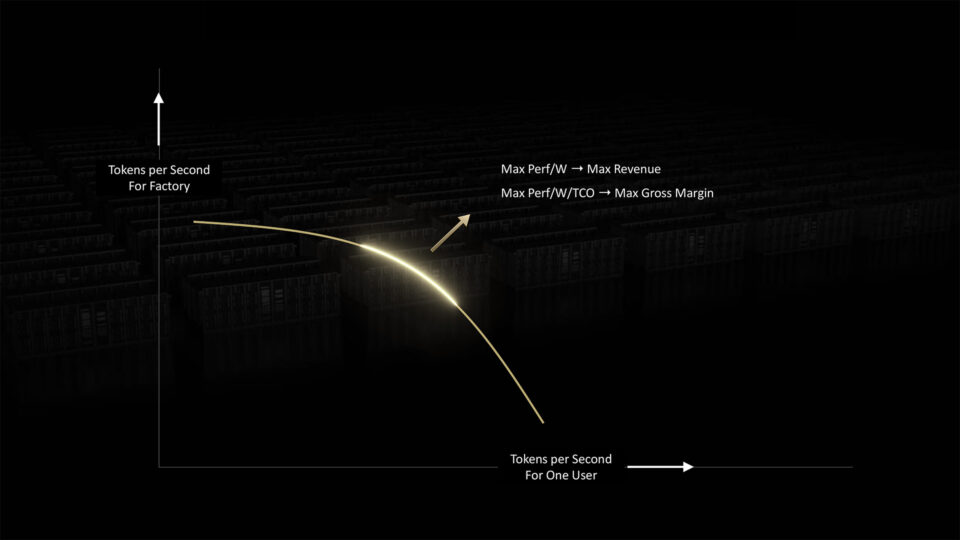
Las fábricas de IA tienen que equilibrar dos demandas que compiten entre sí para ofrecer una inferencia óptima: la velocidad por usuario y el rendimiento general del sistema.

Las fábricas de IA pueden mejorar ambos factores mediante la ampliación, a más FLOPS y mayor ancho de banda. Pueden agrupar y procesar cargas de trabajo de IA para maximizar la productividad.
Pero, en última instancia, las fábricas de IA están limitadas por la potencia a la que pueden acceder
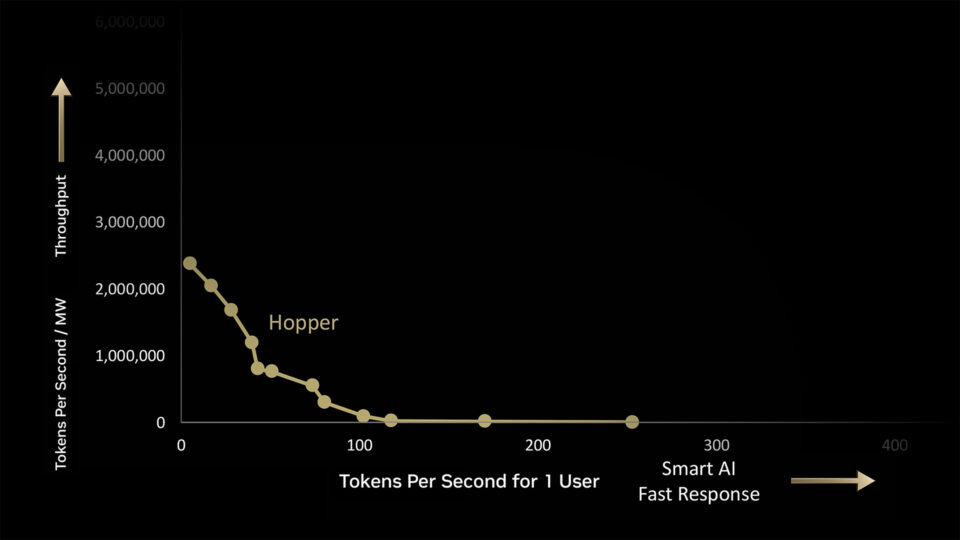
En una fábrica de IA de 1 megavatio, NVIDIA Hopper genera 180.000 tokens por segundo (TPS) al volumen máximo, o 225 TPS para un usuario como máximo.
Pero el verdadero trabajo ocurre en el espacio intermedio. Cada punto a lo largo de la curva representa lotes de cargas de trabajo para que la fábrica de IA las procese, cada una con su propia combinación de demandas de rendimiento.
Las GPU NVIDIA tienen la flexibilidad para manejar este espectro completo de cargas de trabajo porque se pueden programar con el software NVIDIA CUDA.
La arquitectura NVIDIA Blackwell puede hacer mucho más con 1 megavatio que la arquitectura Hopper, y hay más por venir. La optimización de las pilas de software y hardware significa que Blackwell se vuelve más rápido y eficiente con el tiempo.
Blackwell recibe otro impulso cuando los desarrolladores optimizan las cargas de trabajo de las fábricas de IA de forma autónoma con NVIDIA Dynamo, el nuevo sistema operativo para las fábricas de IA.
Dynamo divide las tareas de inferencia en componentes más pequeños, enrutando y redirigiendo dinámicamente las cargas de trabajo a los recursos informáticos más óptimos disponibles en ese momento.
Las mejoras son notables. En un solo salto generacional de la arquitectura de procesadores de Hopper a Blackwell, podemos lograr una mejora de 50 veces en el rendimiento del razonamiento de la IA utilizando la misma cantidad de energía.
Así es como la integración de pila completa de NVIDIA y el software avanzado brindan a los clientes aumentos masivos de velocidad y eficiencia en el tiempo entre generaciones de arquitectura de chips.
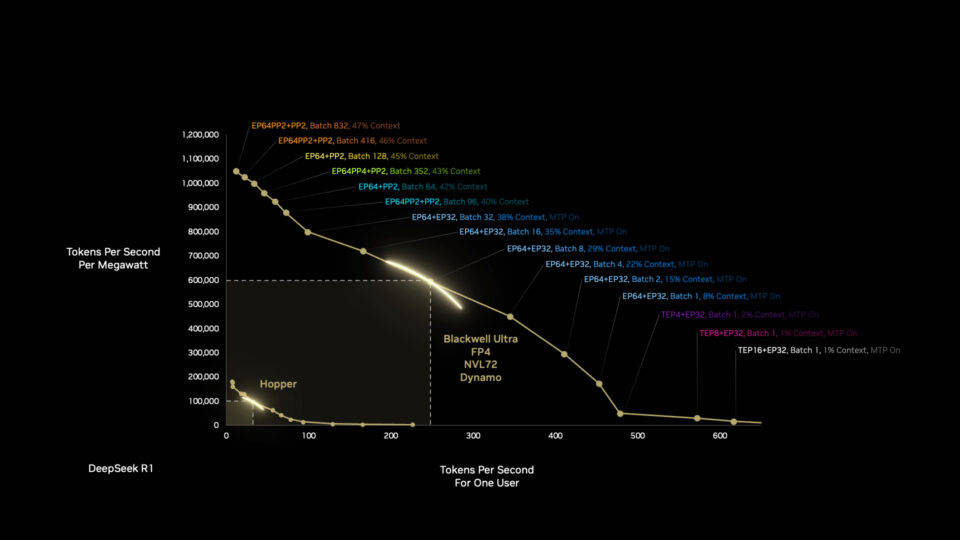
Empujamos esta curva hacia afuera con cada generación, desde el hardware hasta el software, desde la computación hasta las redes.
Y con cada avance en el rendimiento, la IA puede crear billones de dólares de productividad para los socios y clientes de NVIDIA en todo el mundo, al tiempo que nos acerca un paso más a la cura de enfermedades, revierte el cambio climático y descubre algunos de los mayores secretos del universo.
Esto es la computación que se convierte en capital y progreso.