
La misión de NVIDIA es acelerar el trabajo de los Da Vincis y Einsteins de nuestro tiempo y capacitarlos para resolver los grandes desafíos de la sociedad. Como la complejidad de la inteligencia artificial (IA), la computación de alto rendimiento(HPC) y el análisis de datos aumenta exponencialmente, los científicos necesitan una plataforma de computación avanzada que sea capaz de impulsar aceleraciones de millones de veces en una sola década para resolver estos desafíos extraordinarios.
Para responder a esta necesidad, presentamos la NVIDIA HGX H100, un componente fundamental para servidores de GPU con la tecnología de la arquitectura NVIDIA Hopper. Esta plataforma de última generación ofrece de forma segura un alto rendimiento con baja latencia e integra una pila completa de capacidades, desde la red hasta la computación a escala del data center, la nueva unidad de computación.
En esta publicación, analizaré cómo NVIDIA HGX H100 está ayudando a ofrecer el próximo enorme salto en nuestra plataforma de data center de computación acelerada.
HGX H100 8-GPU
La HGX H100 8-GPU representa el componente fundamental del nuevo servidor de GPU de la generación Hopper. Cuenta con ocho GPU H100 Tensor Core y cuatro NVSwitch de tercera generación. Cada GPU H100 tiene varios puertos NVLink de cuarta generación y se conecta a los cuatro NVSwitches. Cada NVSwitch es un switch sin bloqueo que conecta por completo las ocho GPU H100 Tensor Core.
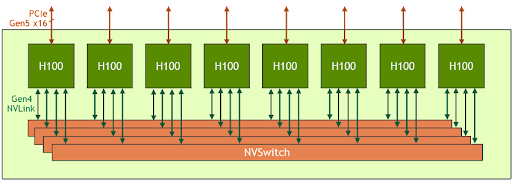
Esta topología completamente conectada de NVSwitch permite que cualquier H100 hable con cualquier otra H100 al mismo tiempo. En particular, esta comunicación se ejecuta a la velocidad bidireccional de NVLink de 900 gigabytes por segundo (GB/s), lo que implica un ancho de banda 14 veces más grande que el bus PCIe Gen4 x16 actual.
La NVSwitch de tercera generación también proporciona una nueva aceleración de hardware para operaciones colectivas con reducciones de multidifusión y NVIDIA SHARP en la red. Al combinarse con la velocidad de NVLink más rápida, el ancho de banda eficaz para las operaciones colectivas comunes de IA, como la reducción total, aumenta 3 veces en comparación con el modelo HGX A100. La aceleración NVSwitch de los colectivos también reduce significativamente la carga en la GPU.
| HGX A100 8-GPU | HGX H100 8-GPU | Relación de Mejora | |
| FP8 | – | 32,000 TFLOPS | 6 veces (en comparación con A100 FP16) |
| FP16 | 4,992 TFLOPS | 16,000 TFLOPS | 3 veces |
| FP64 | 156 TFLOPS | 480 TFLOPS | 3 veces |
| Computación en la Red | 0 | 3.6 TFLOPS | Infinite |
| Interfaz para alojar la CPU | 8 PCIe Gen4 x16 | 8 PCIe Gen5 x16 | 2 veces |
| Ancho de Banda de Sección Doble | 2.4 TB/s | 3.6 TB/s | 1.5 veces |
Tabla 1. Comparación de la HGX A100 8 GPU con la nueva HGX H100 8-GPU
*Nota: El rendimiento FP incluye la baja densidad
HGX H100 8-GPU con compatibilidad para NVLink-Network
La clase emergente de los modelos de IA con billones de parámetros y de HPC a exaescala para tareas como la IA conversacional precisa requieren meses para entrenarse, incluso en supercomputadoras. Comprimir esto a la velocidad del negocio y completar el entrenamiento en horas requiere una comunicación fluida y de alta velocidad entre cada GPU de un clúster de servidor.
Para abordar estos grandes casos de uso, los nuevos NVLink y NVSwitch están diseñados para permitir que la HGX H100 8-GPU se escale y admita un dominio NVLink mucho más grande con la nueva NVLink-Network. Otra versión de HGX H100 8-GPU es compatible con NVLink-Network.
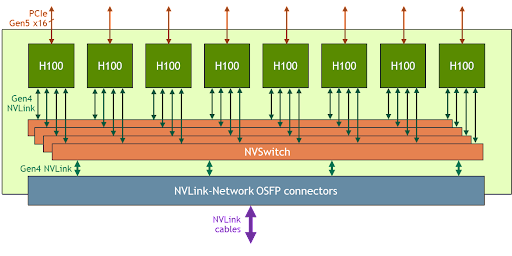
Los nodos del sistema desarrollados la HGX H100 8-GPU y compatibles con NVLink-Network pueden conectarse completamente a otros sistemas a través de los cables LinkX Enchufables y de Formato Pequeño Octal (OSFP) y el nuevo switch NVLink externo. Esta conexión permite hasta un máximo de 256 dominios de NVLink de GPU. La figura 3 muestra la topología de clúster.
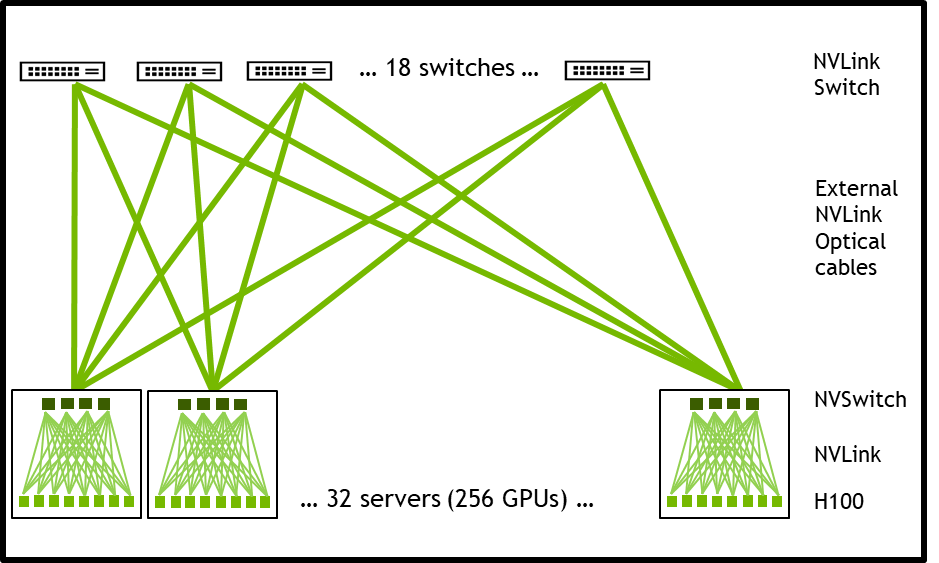
| Pod de 256 GPU A100 | Pod de 256 GPU H100 | Relación de Mejora | |
| Dominio DE NVLINK | 8 GPU | 256 GPU | 32 veces |
| FP8 | – | 1,024 PFLOPS | 6 veces (en comparación con A100 FP16) |
| FP16 | 160 PFLOPS | 512 PFLOPS | 3 veces |
| FP64 | 5 PFLOPS | 15 PFLOPS | 3 veces |
| Computación en la Red | 0 | 192 TFLOPS | Infinite |
| Ancho de Banda de Sección Doble | 6.4 TB/s | 70 TB/s | 11 veces |
Tabla 2. Comparación del pod de 256 GPU A100 con el pod de 256 GPU H100
*Nota: El rendimiento FP incluye la baja densidad
Casos de uso específicos y beneficio de rendimiento
Con el enorme aumento en las capacidades de redes y computación de HGX H100, los rendimientos de las aplicaciones de IA y HPC se mejoran enormemente.
El principal modelo actual de IA y HPC puede residir completamente en la memoria de la GPU agregada de un solo nodo. Por ejemplo, BERT-Large, Mask R-CNN y HGX H100 son las soluciones de entrenamiento más eficientes en cuanto al rendimiento.
Para los modelos de IA y HPC más avanzados y grandes, el modelo requiere varios nodos de memoria de GPU agregada. Por ejemplo, un modelo de recomendación de deep learning (DLRM) con terabytes de tablas incorporadas, un gran modelo de procesamiento de idiomas naturales (MoE) de expertos (MoE) y la l HGX H100 con NVLink-Network reducen el obstáculo clave de la comunicación y son la mejor solución para esta clase de cargas de trabajo.
La Figura 4 del documento técnico sobre la arquitectura de GPU NVIDIA H100 muestra el aumento de rendimiento adicional que permite NVLink-Network.
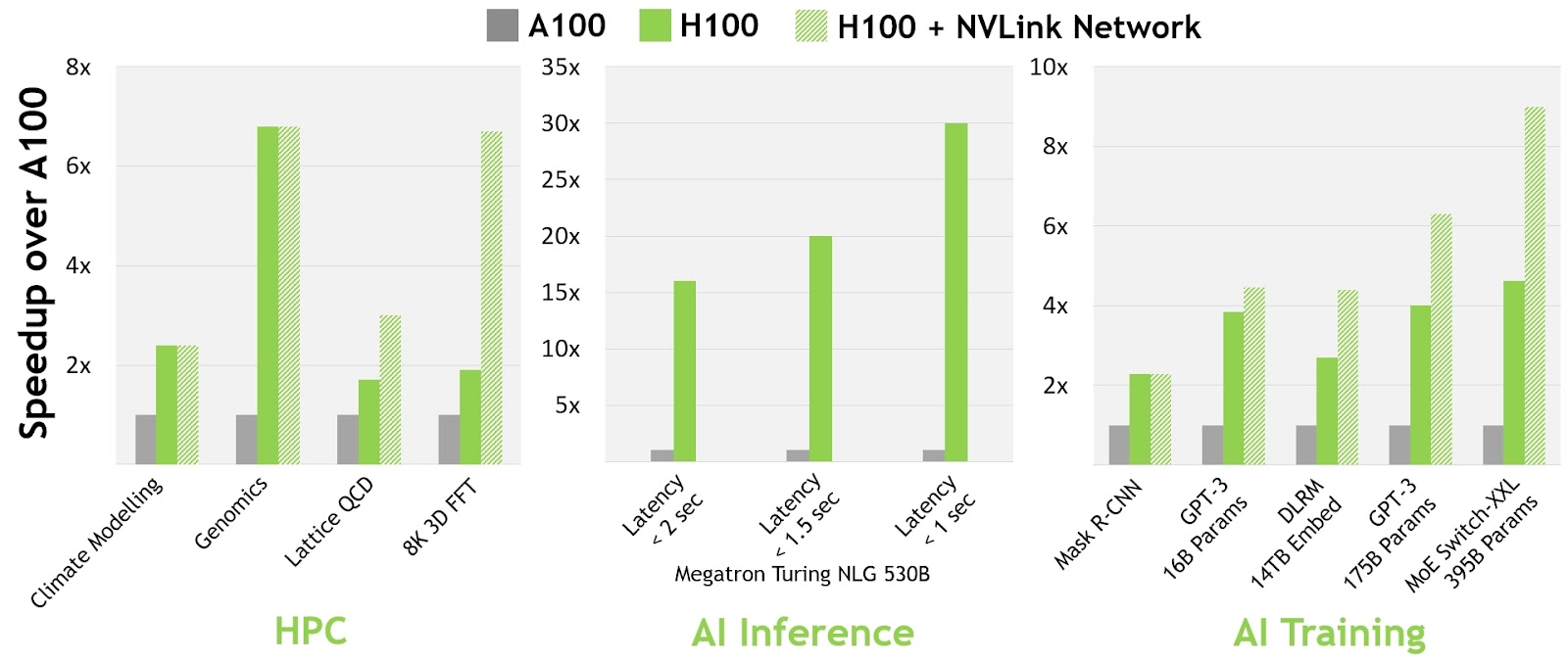
Todas las cifras de rendimiento se basan preliminarmente en las expectativas actuales y están sujetas a cambios al momento de enviar los productos. Clúster A100: Red HDR IB. Clúster H100: Red NDR IB con NVLink-Network donde sea indicado.
Cantidad de GPU: Modelado climático 1K, LQCD 1K, Genómica 8, 3D-FFT 256, MT-NLG 32 (tamaños de lote: 4 para A100, 60 para H100 a 1 s, 8 para A100 y 64 para H100 a 1.5 y 2 s), MRCNN 8 (lote 32), GPT-3 16B 512 (lote 256), DLRM 128 (lote 64K), GPT-3 16K (lote 512), MoE 8K (lote 512, un experto por GPU)
HGX H100 4-GPU
Además de la versión de 8 GPU, la familia HGX también cuenta con una versión con 4 GPU, que está directamente conectada con NVLink de cuarta generación.
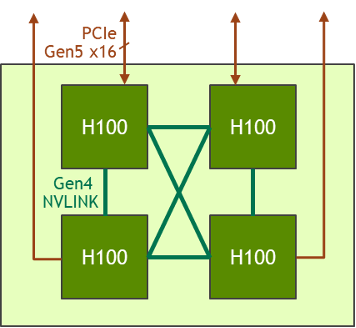
El ancho de banda NVLink punto a punto H100-a-H100 es de 300 GB/s bidireccional, que es aproximadamente 5 veces más rápido que el bus PCIe Gen4 x16 de la actualidad.
El formato de HGX H100 4 GPU está optimizado para la implementación densa de HPC:
- Se pueden usar varias HGX H100 4-GPU en un sistema de enfriamiento líquido de 1U alto para maximizar la densidad de GPU por rack.
- La arquitectura completamente sin switches PCIe con HGX H100 4 GPU se conecta directamente a la CPU, lo que reduce la lista de materiales del sistema y ahorra energía.
- Para las cargas de trabajo que requieren más CPU, la GPU HGX H100 4-GPU se puede conectar con dos sockets de CPU para aumentar la relación entre la CPU y la GPU, y así lograr una configuración del sistema más equilibrada.
Una plataforma para servidores acelerada para IA y HPC
NVIDIA trabaja estrechamente con nuestro ecosistema para lanzar la plataforma para servidores basada en HGX H100 al mercado a finales de este año. Esperamos poner esta potente herramienta de computación en tus manos, para que puedas innovar y realizar el trabajo de tu vida al ritmo más rápido de la historia humana.