
Para entender los últimos avances en IA generativa, imaginemos un tribunal.
Los jueces escuchan y deciden casos en función de su comprensión general de la ley. A veces, un caso, como una demanda por negligencia o una disputa laboral, requiere experiencia especial, por lo que los jueces envían a los secretarios judiciales a una biblioteca de derecho, en busca de precedentes y casos específicos que puedan citar.
Al igual que un buen juez, los modelos de lenguaje grandes (LLM) pueden responder a una amplia variedad de consultas humanas. Pero para ofrecer respuestas autorizadas que citen fuentes, el modelo necesita un asistente que investigue un poco.
El secretario judicial de la IA es un proceso llamado generación aumentada de recuperación, o RAG para abreviar.
La Historia del Nombre
Patrick Lewis, autor principal del artículo de 2020 que acuñó el término, se disculpó por el acrónimo poco favorecedor que ahora describe una creciente familia de métodos en cientos de artículos y docenas de servicios comerciales que cree que representan el futuro de la IA generativa.
«Definitivamente habríamos pensado más en el nombre si hubiéramos sabido que nuestro trabajo se extendería tanto», dijo Lewis en una entrevista desde Singapur, donde compartió sus ideas con una conferencia regional de desarrolladores de bases de datos.
«Siempre planeamos tener un nombre que sonara mejor, pero cuando llegó el momento de escribir el artículo, nadie tuvo una idea mejor», dijo Lewis, quien ahora dirige un equipo de RAG en la startup de IA Cohere.
Entonces, ¿Qué Es la Generación Aumentada de Recuperación?
La generación aumentada de recuperación es una técnica para mejorar la precisión y la fiabilidad de los modelos de IA generativa con datos obtenidos de fuentes externas.
En otras palabras, llena un vacío en el funcionamiento de los LLM. Bajo el capó, los LLM son redes neuronales, que normalmente se miden por la cantidad de parámetros que contienen. Los parámetros de un LLM representan esencialmente los patrones generales de cómo los humanos usan las palabras para formar oraciones.
Esa comprensión profunda, a veces llamada conocimiento parametrizado, hace que los LLM sean útiles para responder a indicaciones generales a la velocidad de la luz. Sin embargo, no sirve a los usuarios que desean una inmersión más profunda en un tema actual o más específico.
Combinación de Recursos Internos y Externos
Lewis y sus colegas desarrollaron la generación aumentada de recuperación para vincular los servicios de IA generativa con recursos externos, especialmente aquellos ricos en los últimos detalles técnicos.
El artículo, con coautores de la antigua Facebook AI Research (ahora Meta AI), el University College de Londres y la Universidad de Nueva York, calificó a RAG como «una receta de ajuste fino de propósito general» porque puede ser utilizada por casi cualquier LLM para conectarse con prácticamente cualquier recurso externo.
Generar Confianza en los Usuarios
La generación aumentada de recuperación proporciona a los modelos fuentes que pueden citar, como notas a pie de página en un trabajo de investigación, para que los usuarios puedan comprobar cualquier afirmación. Eso genera confianza.
Además, la técnica puede ayudar a los modelos a aclarar la ambigüedad en una consulta de usuario. También reduce la posibilidad de que un modelo haga una suposición incorrecta, un fenómeno a veces llamado alucinación.
Otra gran ventaja de RAG es que es relativamente fácil. Un blog de Lewis y tres de los coautores del artículo dijo que los desarrolladores pueden implementar el proceso con tan solo cinco líneas de código.
Esto hace que el método sea más rápido y menos costoso que volver a entrenar un modelo con conjuntos de datos adicionales. Y permite a los usuarios intercambiar nuevas fuentes sobre la marcha.
Cómo Utilizan las Personas la Generación de Recuperación Aumentada
Con la generación aumentada de recuperación, los usuarios pueden tener conversaciones con los repositorios de datos, lo que abre nuevos tipos de experiencias. Esto significa que las aplicaciones para RAG podrían ser varias veces el número de conjuntos de datos disponibles.
Por ejemplo, un modelo de IA generativa complementado con un índice médico podría ser un gran asistente para un médico o una enfermera. Los analistas financieros se beneficiarían de un asistente vinculado a los datos del mercado.
De hecho, casi cualquier empresa puede convertir sus manuales técnicos o de políticas, videos o registros en recursos llamados bases de conocimiento que pueden mejorar los LLM. Estas fuentes pueden permitir casos de uso como el soporte al cliente o de campo, la capacitación de los empleados y la productividad de los desarrolladores.
El amplio potencial es la razón por la que empresas como AWS, IBM, Espigar, Google, Microsoft, NVIDIA, Oráculo y Piña están adoptando GAR.
Introducción a la Generación de Recuperación Aumentada
Para ayudar a los usuarios a comenzar, NVIDIA desarrolló una arquitectura de referencia para la generación aumentada de recuperación. Incluye un chatbot de muestra y los elementos que los usuarios necesitan para crear sus propias aplicaciones con este nuevo método.
El workflow utiliza NVIDIA NeMo, un framework para desarrollar y personalizar modelos de IA generativa, así como software como Servidor de inferencia NVIDIA Triton y NVIDIA TensorRT-LLM para ejecutar modelos de IA generativa en producción. Los usuarios pueden agregar NVIDIA Riva para crear aplicaciones que permitan una comunicación rápida y manos libres.
Todos los componentes de software forman parte de NVIDIA AI Enterprise, una plataforma de software que acelera el desarrollo y la implementación de IA lista para la producción con la seguridad, el soporte y la estabilidad que necesitan las empresas.
Obtener el mejor rendimiento para los workflows de RAG requiere cantidades masivas de memoria y computación para mover y procesar datos. El Superchip NVIDIA GH200 Grace Hopper, con sus 288 GB de memoria HBM3e rápida y 8 petaflops de cómputo, es ideal: puede ofrecer una aceleración de 150 veces más que con una CPU.
Una vez que las empresas se familiarizan con RAG, pueden combinar una variedad de LLM listos para usar o personalizados con bases de conocimiento internas o externas para crear una amplia gama de asistentes que ayuden a sus empleados y clientes.
RAG no requiere un data center. Los LLM están debutando en las PC con Windows, gracias al software NVIDIA que permite todo tipo de aplicaciones a las que los usuarios pueden acceder incluso en sus computadoras portátiles.
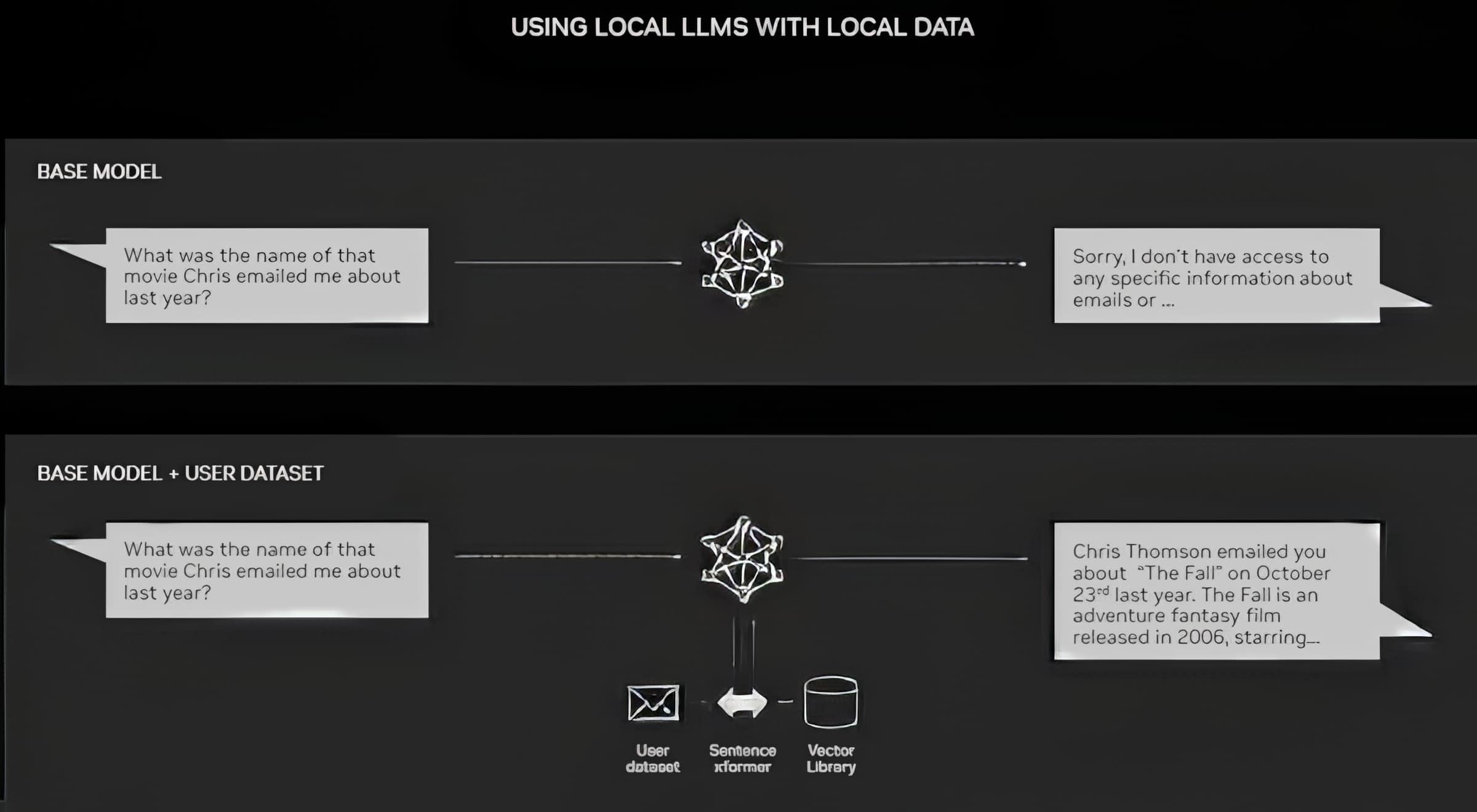
Las PC equipadas con GPU NVIDIA RTX ahora pueden ejecutar algunos modelos de IA localmente. Al usar RAG en una PC, los usuarios pueden vincularse a una fuente de conocimiento privada, ya sean correos electrónicos, notas o artículos, para mejorar las respuestas. De este modo, el usuario puede estar seguro de que su fuente de datos, sus indicaciones y su respuesta siguen siendo privados y seguros.
Un blog reciente proporciona un ejemplo de RAG acelerado por TensorRT-LLM para Windows para obtener mejores resultados rápidamente.
La Historia de la Generación Aumentada de Recuperación
Las raíces de la técnica se remontan al menos a principios de la década de 1970. Fue entonces cuando los investigadores en recuperación de información crearon un prototipo de lo que llamaron sistemas de preguntas y respuestas, aplicaciones que utilizan el procesamiento del lenguaje natural (NLP) para acceder al texto, inicialmente en temas específicos como el béisbol.
Los conceptos detrás de este tipo de minería de texto se han mantenido bastante constantes a lo largo de los años. Pero los motores de machine learning que los impulsan han crecido significativamente, aumentando su utilidad y popularidad.
A mediados de la década de 1990, el servicio Ask Jeeves, ahora Ask.com, popularizó la respuesta a preguntas con su mascota de un valet bien vestido. Watson, de IBM, se convirtió en una celebridad televisiva en 2011 cuando venció cómodamente a dos campeones humanos en el Jeopardy! programa de juegos.
Hoy en día, los LLM están llevando los sistemas de preguntas y respuestas a un nivel completamente nuevo.
Perspectivas de un Laboratorio de Londres
El artículo seminal de 2020 llegó cuando Lewis estaba cursando un doctorado en PNL en el University College de Londres y trabajando para Meta en un nuevo laboratorio de IA de Londres. El equipo buscaba formas de incluir más conocimiento en los parámetros de un LLM y utilizaba un punto de referencia que desarrolló para medir su progreso.
Basándose en métodos anteriores e inspirados por un artículo de los investigadores de Google, el grupo «tuvo esta visión convincente de un sistema entrenado que tenía un índice de recuperación en el medio, por lo que podía aprender y generar cualquier salida de texto que quisiera», recordó Lewis.

Cuando Lewis conectó al trabajo en curso un prometedor sistema de recuperación de otro equipo de Meta, los primeros resultados fueron inesperadamente impresionantes.
«Se lo mostré a mi supervisor y me dijo: ‘Vaya, llévate la victoria. Este tipo de cosas no suceden muy a menudo, porque estos workflows pueden ser difíciles de configurar correctamente la primera vez», dijo.
Lewis también atribuye las importantes contribuciones de los miembros del equipo Ethan Perez y Douwe Kiela, entonces de la Universidad de Nueva York y Facebook AI Research, respectivamente.
Una vez completado, el trabajo, que se ejecutó en un clúster de GPU NVIDIA, mostró cómo hacer que los modelos de IA generativa sean más autorizados y confiables. Desde entonces, ha sido citado por cientos de artículos que ampliaron y ampliaron los conceptos en lo que sigue siendo un área activa de investigación.
Cómo Funciona la Generación Aumentada de Recuperación
A grandes rasgos, así es como un resumen técnico de NVIDIA describe el proceso RAG.
Cuando los usuarios hacen una pregunta a un LLM, el modelo de IA envía la consulta a otro modelo que la convierte en un formato numérico para que las máquinas puedan leerla. La versión numérica de la consulta a veces se denomina incrustación o vector.
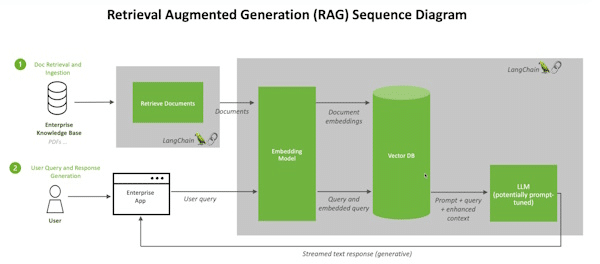
A continuación, el modelo de incrustación compara estos valores numéricos con vectores en un índice legible por máquina de una base de conocimiento disponible. Cuando encuentra una o varias coincidencias, recupera los datos relacionados, los convierte en palabras legibles por humanos y los devuelve al LLM.
Por último, el LLM combina las palabras recuperadas y su propia respuesta a la consulta en una respuesta final que presenta al usuario, citando potencialmente las fuentes que encontró el modelo de incrustación.
Mantener las Fuentes Actualizadas
En segundo plano, el modelo de incrustación crea y actualiza continuamente índices legibles por máquina, a veces denominados bases de datos vectoriales, para bases de conocimiento nuevas y actualizadas a medida que están disponibles.
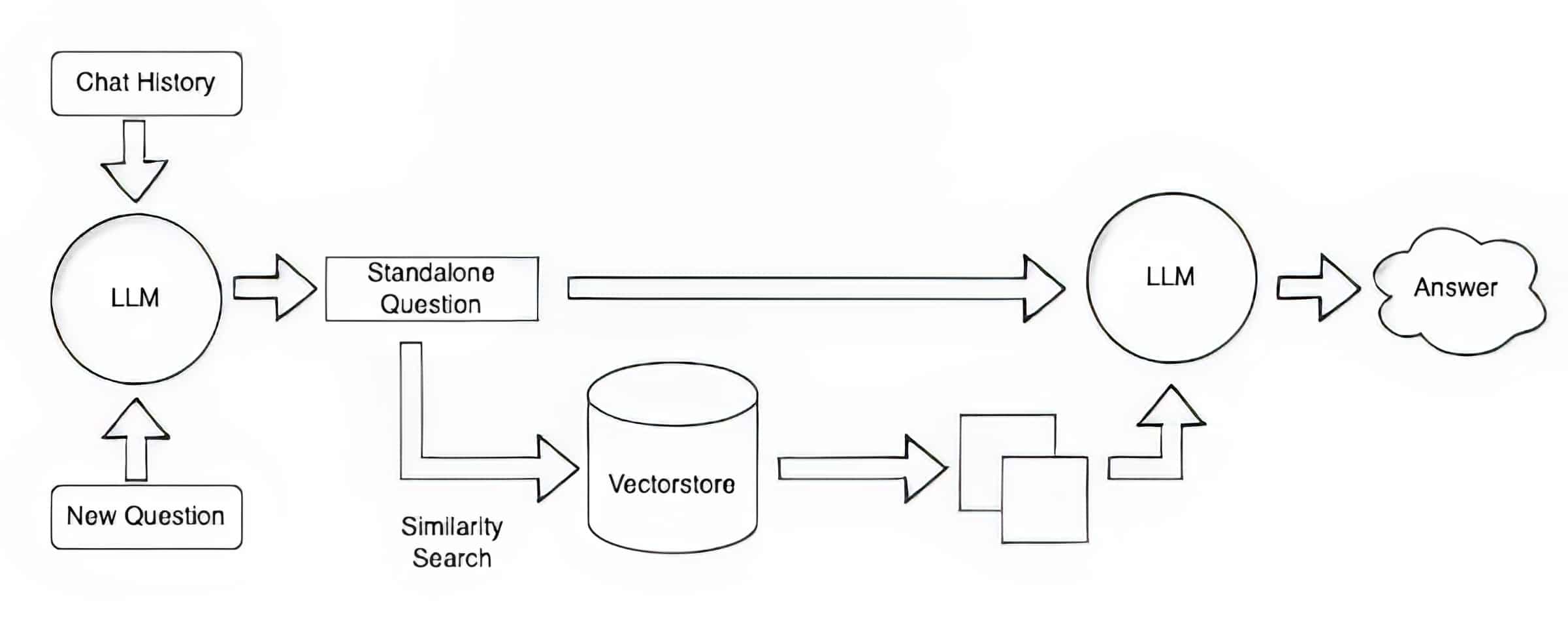
Muchos desarrolladores encuentran que LangChain, una biblioteca de código abierto, puede ser particularmente útil para encadenar LLM, incrustar modelos y bases de conocimiento. NVIDIA utiliza LangChain en su arquitectura de referencia para la generación de recuperación aumentada.
La comunidad de LangChain proporciona su propia descripción de un proceso RAG.
De cara al futuro, el futuro de la IA generativa radica en encadenar creativamente todo tipo de LLM y bases de conocimientos para crear nuevos tipos de asistentes que ofrezcan resultados autorizados que los usuarios puedan verificar.
Ponte manos a la obra con el uso de la generación aumentada de recuperación con un chatbot de IA en este laboratorio de NVIDIA LaunchPad.