Si quieres subirte a la próxima gran ola en IA, consigue un transformer.e
No son los robots de juguete de la televisión que cambian de forma ni las cajas del tamaño de un tacho de la basura en los postes telefónicos.
Entonces, ¿Qué Es un Modelo Transformer?
Un modelo transformer es una red neuronal que aprende contexto y, por lo tanto, significado mediante el seguimiento de relaciones en datos secuenciales como las palabras de esta oración.
Los modelos transformer aplican un conjunto en evolución de técnicas matemáticas, llamadas atención o atención propia, para detectar formas sutiles en que los elementos de datos en una serie se influencian y dependen entre sí.
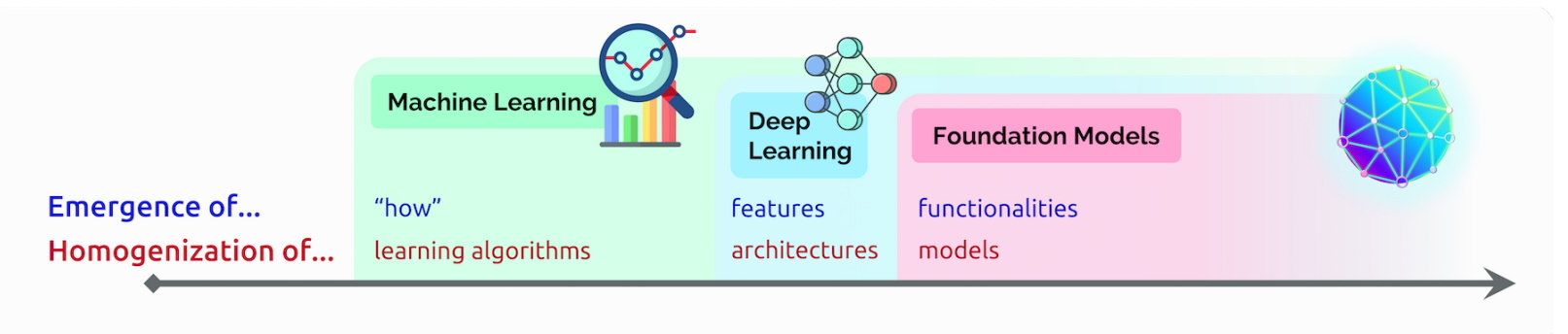
Los transformers se describieron por primera vez en un documento de 2017 de Google. Estos transformers son una de las clases más nuevas y potentes de modelos inventados hasta la fecha. Están impulsando una ola de avances en machine learning que algunos han apodado como la «IA de transformer».
En agosto de 2021, los investigadores de Stanford llamaron a los transformers los «modelos de base» porque ven que impulsan un cambio de paradigma en la IA. «La gran escala y el alcance de los modelos de base en los últimos años han extendido nuestra imaginación de lo que es posible», escribieron.
¿Qué Pueden Hacer los Modelos Transformer?
Los transformers está traduciendo texto y habla casi en tiempo real, lo que permite el acceso a reuniones y aulas para diversos asistentes con discapacidades auditivas.
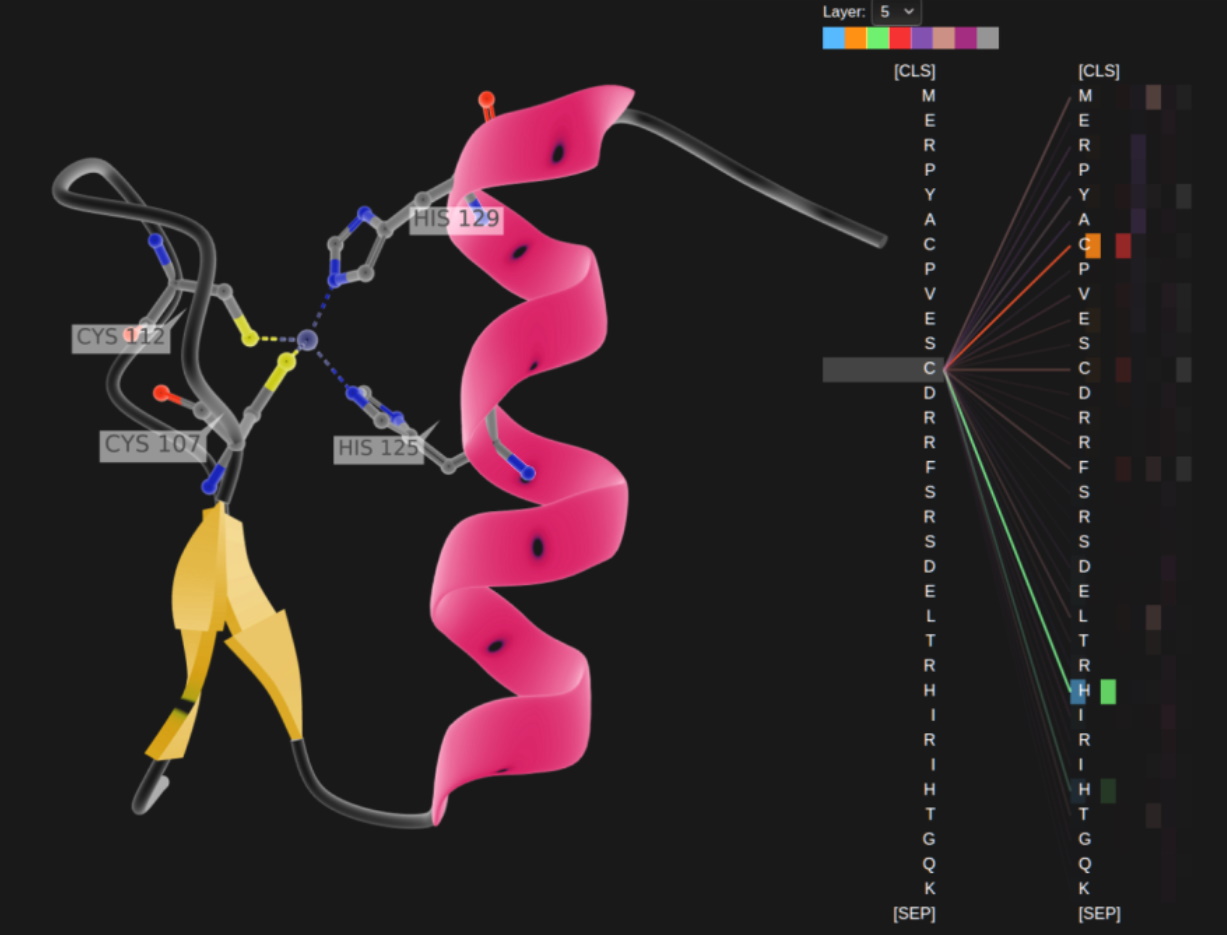
Están ayudando a los investigadores a comprender las cadenas de genes en el ADN y los aminoácidos en proteínas de formas que pueden acelerar el diseño de fármacos.
Los transformers pueden detectar tendencias y anomalías para prevenir fraudes, optimizar la manufactura, hacer recomendaciones en línea o mejorar el área de la salud.
Las personas usan transformers cada vez que realizan búsquedas en Google o Microsoft Bing.
El Ciclo Virtuoso de la IA de Transformers
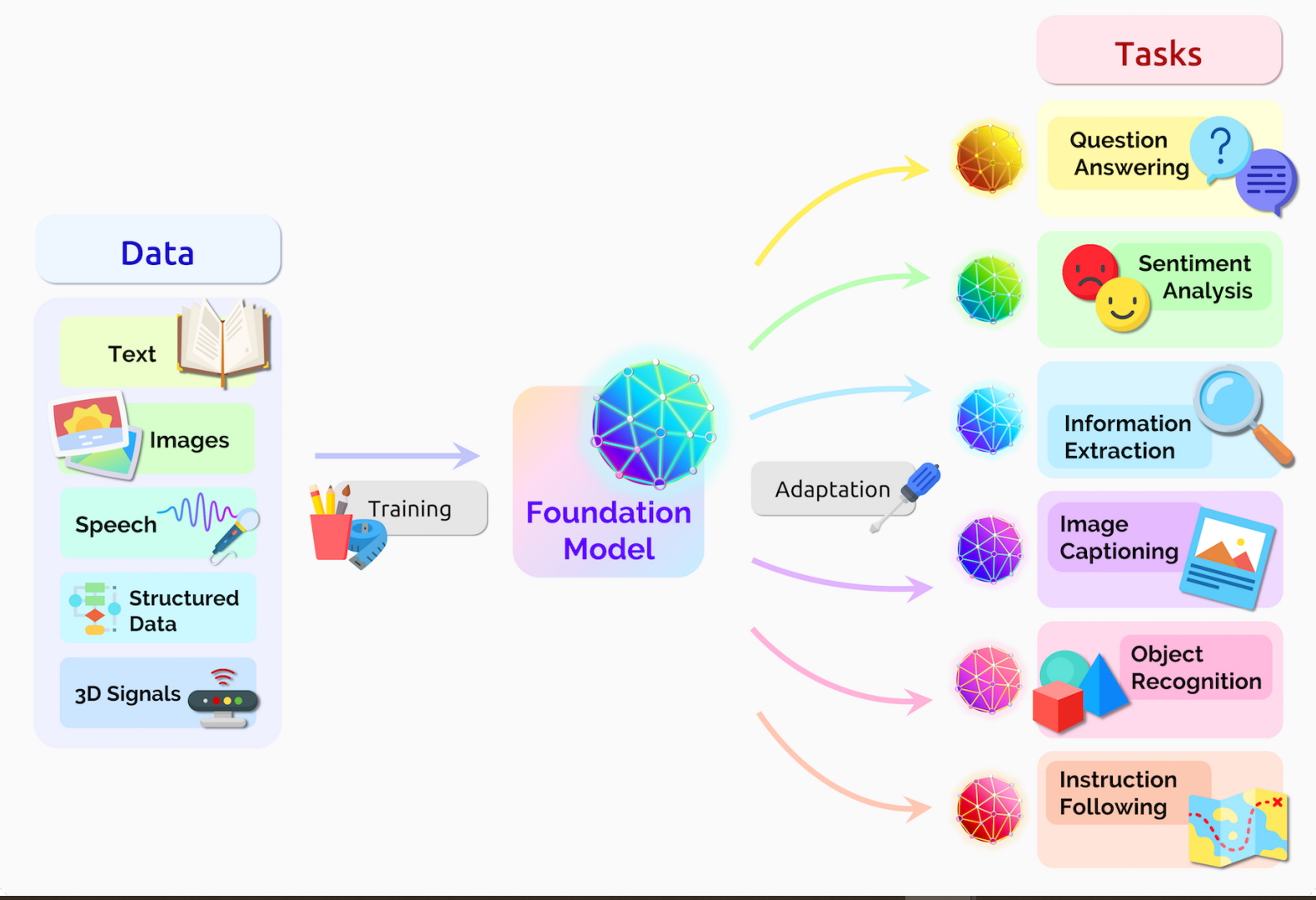
Cualquier aplicación que utilice datos de texto, imagen o video secuenciales es un candidato para los modelos de transformers.
Esto permite que estos modelos recorran un ciclo virtuoso en la IA de transformers. Los transformers se crearon con grandes conjuntos de datos y hacen predicciones precisas que impulsan su uso más amplio, lo que genera más datos que se pueden utilizar para crear modelos aun mejores.
«Los transformers hicieron posible el aprendizaje autosupervisado y la IA alcanzó una velocidad asombrosa», dijo Jensen Huang, fundador y CEO de NVIDIA, en su discurso destacado de esta semana en GTC.
Los Transformers Reemplazan las CNN y las RNN
Los transformers está reemplazando en muchos casos las redes neuronales convolucionales y recurrentes (CNN y RNN), los tipos de modelos de deep learning más populares de hace solo cinco años.
De hecho, el 70 por ciento de los artículos de arXiv sobre IA publicados en los últimos dos años mencionan a los transformers. Eso es un cambio radical de un estudio de IEEE de 2017 que informó que las RNN y las CNN eran los modelos más populares para el reconocimiento de patrones.
Sin Etiquetas, Más Rendimiento
Antes de que llegaran los transformers, los usuarios tenían que entrenar redes neuronales con grandes conjuntos de datos etiquetados que eran costosos y lentos de producir. Al encontrar patrones entre elementos matemáticamente, los transformers eliminan esa necesidad, ya que están disponibles los billones de imágenes y petabytes de datos de texto en la Web y en las bases de datos corporativas.
Además, la matemática que usan los transformers aprovecha el procesamiento paralelo, para que estos modelos puedan ejecutarse rápidamente.
Ahora, los transformers dominan las tablas de posiciones de rendimiento populares, como SuperGLUE, una evaluación desarrollada en 2019 para los sistemas de procesamiento de idiomas.
Cómo Prestan Atención los Transformers
Al igual que la mayoría de las redes neuronales, los modelos de transformers son básicamente grandes bloques de codificación/decodificación que procesan datos.
Las adiciones pequeñas pero estratégicas a estos bloques (que se muestran en el diagrama siguiente) hacen que los transformers sean increíblemente potentes.
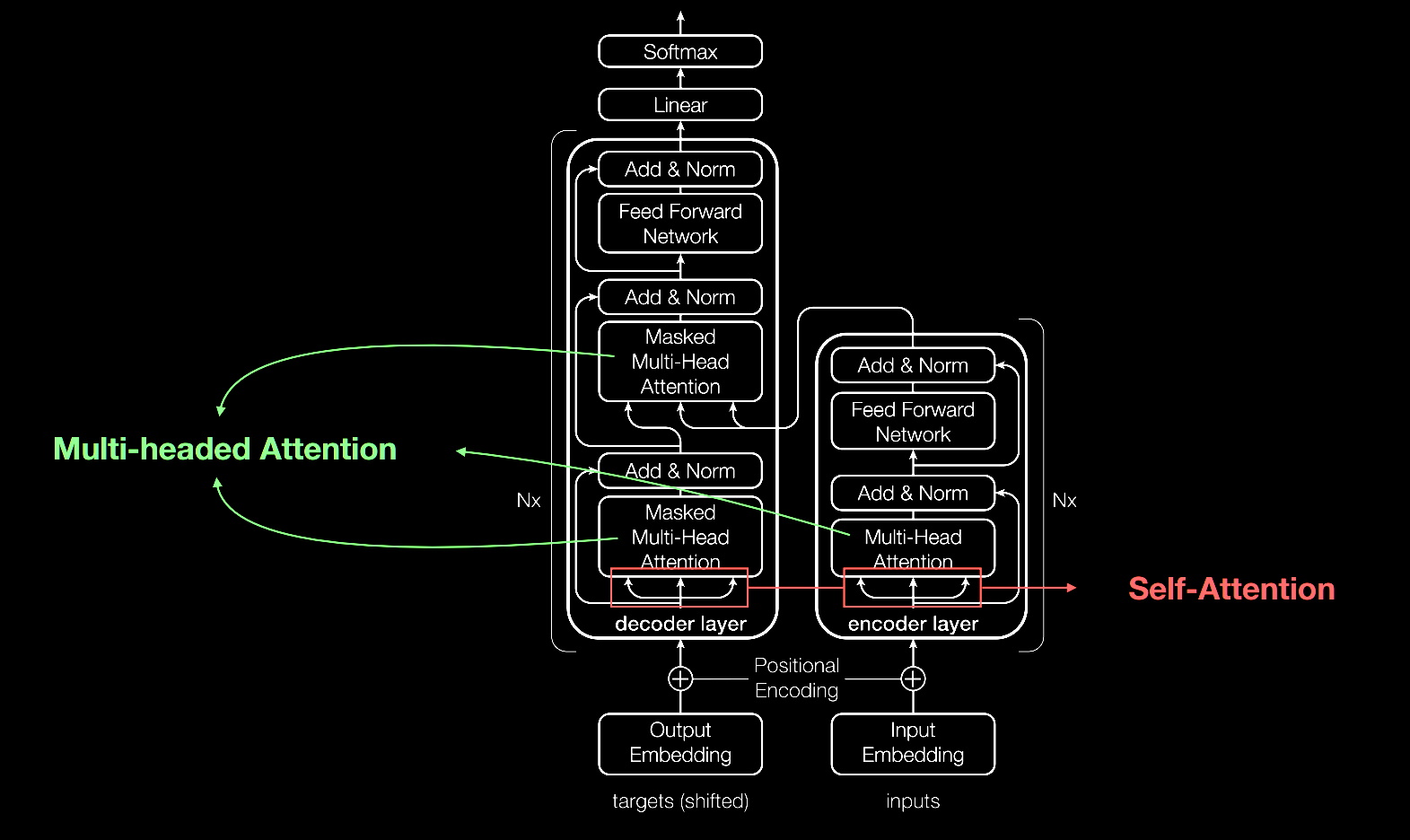
Los transformers utilizan codificadores posicionales para etiquetar elementos de datos que entran y salen de la red. Las unidades de atención siguen estas etiquetas, calculando una especie de mapa algebráico de la forma en que cada elemento se relaciona con los demás.
Las consultas de atención se suelen ejecutar en paralelo calculando una matriz de ecuaciones en lo que se llama atención de múltiples encabezados.
Con estas herramientas, las computadoras pueden ver los mismos patrones que ven los humanos.
La Atención Personal Encuentra un Significado
Por ejemplo, en la oración:
Ella sirvió agua de la jarra a la taza hasta que se llenó.
Sabemos que «se» se refiere a la taza, mientras que en la oración:
Ella sirvió agua de la jarra a la taza hasta que se vació.
Sabemos que «se» se refiere a la jarra.
«El significado es el resultado de las relaciones entre las cosas y la atención personal es una forma general de aprender las relaciones», dijo Ashish Vaswani, excientífico investigador sénior del personal de Google Brain, quien dirigió el trabajo en el documento seminal de 2017.
«La traducción automática fue un buen vehículo para validar la autoatención porque se necesitan relaciones de corta y larga distancia entre palabras», dijo Vaswani.
«Ahora vemos que la autoatención es una herramienta poderosa y flexible para el aprendizaje», agregó.
Cómo Apareció el Nombre de los Transformers
La atención es tan clave para los transformers que los investigadores de Google casi utilizan el término como el nombre de su modelo de 2017. Casi.
«La Red de Atención no parecía muy emocionante», dijo Vaswani, quien comenzó a trabajar con redes neuronales en 2011.
Jakob Uszkoreit, un ingeniero de software sénior del equipo, se le ocurrió el nombre de «transformer».
«Argumenté que estábamos transformando las representaciones, pero eso simplemente era jugar con la semántica», dijo Vaswani.
El Nacimiento de los Transformers
En el documento para la conferencia NeurIPS de 2017, el equipo de Google describió su transformer y los registros de precisión que estableció para la traducción automática.
Gracias a una serie de técnicas, entrenaron su modelo en solo 3.5 días con ocho GPU de NVIDIA, una pequeña fracción del tiempo y del costo de entrenamiento de los modelos anteriores. Lo entrenaron con conjuntos de datos de hasta 1000 millones de pares de palabras.
«Fue un intenso trabajo de tres meses hasta la fecha de presentación del documento», recordó Aidan Gomez, un pasante de Google en 2017, que contribuyó a la obra.
«La noche que estábamos enviando el documento, Ashish y yo trabajamos hasta el amanecer en Google», dijo. «Logré dormir dos horas en una de las pequeñas salas de conferencias y me desperté justo a tiempo para la presentación cuando alguien que venía temprano a trabajar abrió la puerta y me golpeó en la cabeza».
Fue una llamada de atención de más de una manera.
«Ashish me dijo esa noche que estaba convencido de que esto iba a ser un gran avance, algo revolucionario. No estaba convencido, pensé que sería una ganancia modesta en una evaluación, pero resultó que él estaba muy en lo cierto», dijo Gomez, ahora CEO de la startup Cohere que proporciona un servicio de procesamiento de idiomas basado en transformer.
Un Momento para Machine Learning
Vaswani recuerda la emoción de ver que los resultados superaban un trabajo similar publicado por un equipo de Facebook utilizando CNN.
«Podía ver que este sería un momento importante para machine learning», dijo.
Un año más tarde, otro equipo de Google intentó procesar secuencias de texto tanto hacia adelante como hacia atrás con un transformer. Eso ayudó a capturar más relaciones entre palabras, lo que mejoró la capacidad del modelo para comprender el significado de una oración.
Su modelo Representaciones del Codificador Bidireccional de Transformers (BERT) estableció 11 nuevos récords y se convirtió en parte del algoritmo detrás de la búsqueda de Google.
En las próximas semanas, los investigadores de todo el mundo adaptaron BERT para casos de uso en muchos idiomas e industrias «porque el texto es uno de los tipos de datos más comunes que las empresas tienen», dijo Anders Arpteg, un veterano con 20 años de experiencia en la investigación de machine learning.
Poner en Funcionamiento los Transformers
Pronto, los modelos de transformers comenzaron a implementarse en la ciencia y el área de la salud.
DeepMind, en Londres, avanzó en la comprensión de proteínas, los componentes fundamentales de la vida, utilizando un transformer llamado AlphaFold2, que se describe en un reciente artículo de Nature. Procesó cadenas de aminoácidos como cadenas de texto para establecer una nueva marca de agua para describir cómo se retiran las proteínas, trabajo que podría acelerar el descubrimiento de fármacos.
AstraZeneca y NVIDIA desarrollaron MegaMolBART, un transformer adaptado para el descubrimiento de fármacos. Es una versión del transformador MolBART de la compañía farmacéutica, entrenado en una gran base de datos sin etiquetar de compuestos químicos utilizando el framework NVIDIA Megatron para construir modelos de transformers a gran escala.
Lectura de Moléculas, Registros Médicos
«Así como los modelos de idiomas de IA pueden aprender las relaciones entre las palabras en una oración, nuestro objetivo es que las redes neuronales entrenadas con datos de estructura molecular puedan aprender las relaciones entre los átomos en las moléculas del mundo real», dijo Ola Engkvist, directora de IA molecular, ciencias de descubrimiento e I+D en AstraZeneca, cuando se anunció el trabajo el año pasado.
Por separado, el centro académico de salud de la Universidad de Florida colaboró con investigadores de NVIDIA para crear GatorTron. El modelo de transformer tiene como objetivo extraer información de enormes volúmenes de datos clínicos para acelerar la investigación médica.
Los Transformers Crecen
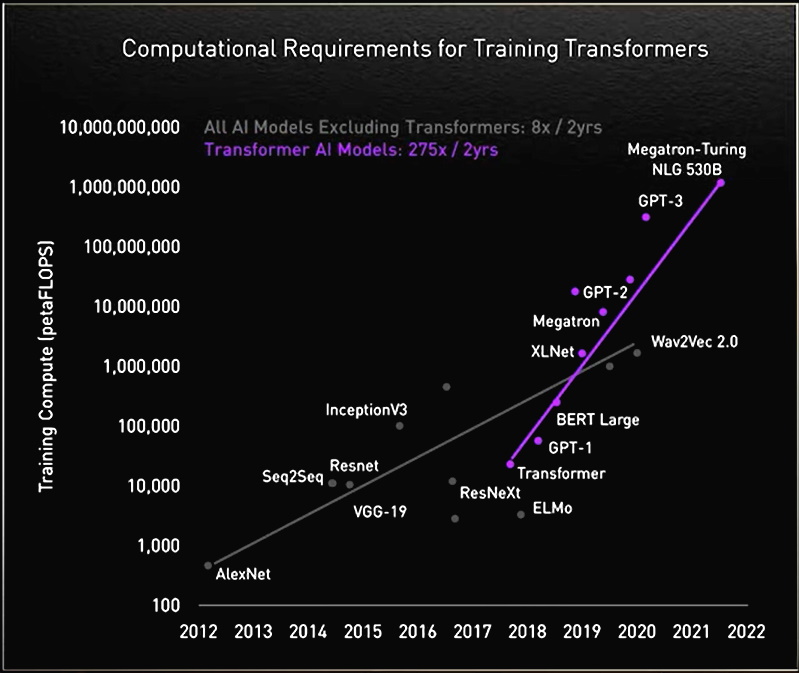
En el camino, los investigadores descubrieron que los transformers más grandes funcionaban mejor.
Por ejemplo, investigadores de Rostlab de la Universidad Técnica de Múnich, que ayudó a trabajar de forma pionera en la intersección de la IA y la biología, utilizaron el procesamiento de idiomas naturales para comprender las proteínas. En 18 meses, pasaron de usar RNN con 90 millones de parámetros a modelos de transformers con 567 millones de parámetros.
El laboratorio de OpenAI mostró que más grande es mejor gracias a su Transformer Generativo Previamente Entrenado (GPT). La última versión, GPT-3, tiene 175,000 millones de parámetros, en lugar de los 1500 millones para GPT-2.
Con el peso adicional, GPT-3 puede responder a la consulta de un usuario incluso en tareas que no está específicamente entrenado para manejar. Ya está siendo utilizado por empresas como Cisco, IBM y Salesforce.
Historia de un Megatransformer
En noviembre, NVIDIA y Microsoft establecieron una nueva marca, al anunciar el modelo de generación de idiomas naturales Megatron-Turing (MT-NLG) con 530,000 millones de parámetros. Debutó junto con un nuevo framework, NVIDIA NeMo Megatron, que tiene como objetivo permitir que cualquier negocio cree sus propios transformers de miles de millones o billones de parámetros para impulsar chatbots personalizados, asistentes personales y otras aplicaciones de IA que entienden el idioma.
MT-NLG debutó en público como el cerebro de TJ, el avatar de Toy Jensen, que dio parte del discurso destacado en la GTC de noviembre de 2021 de NVIDIA.
«Cuando vimos a TJ responder preguntas, es decir, el poder de nuestro trabajo demostrado por nuestro CEO, fue emocionante», dijo Mostofa Patwary, quien dirigió el equipo de NVIDIA que entrenó el modelo.

Crear tales modelos no es para cualquiera. MT-NLG se entrenó utilizando cientos de miles de millones de elementos de datos, un proceso que requería miles de GPU funcionando durante semanas.
«Entrenar modelos de transformers grandes es costoso y requiere mucho tiempo, por lo que si no tienes éxito la primera o segunda vez, es posible que los proyectos se cancelen», dijo Patwary.
Transformers con Billones de Parámetros
Hoy en día, muchos ingenieros de IA están trabajando en transformers con billones de parámetros y en aplicaciones para ellos.
«Estamos explorando constantemente cómo estos grandes modelos pueden ofrecer mejores aplicaciones. También investigamos en qué aspectos fallan, para poder construir modelos mejores y más grandes», dijo Patwary.
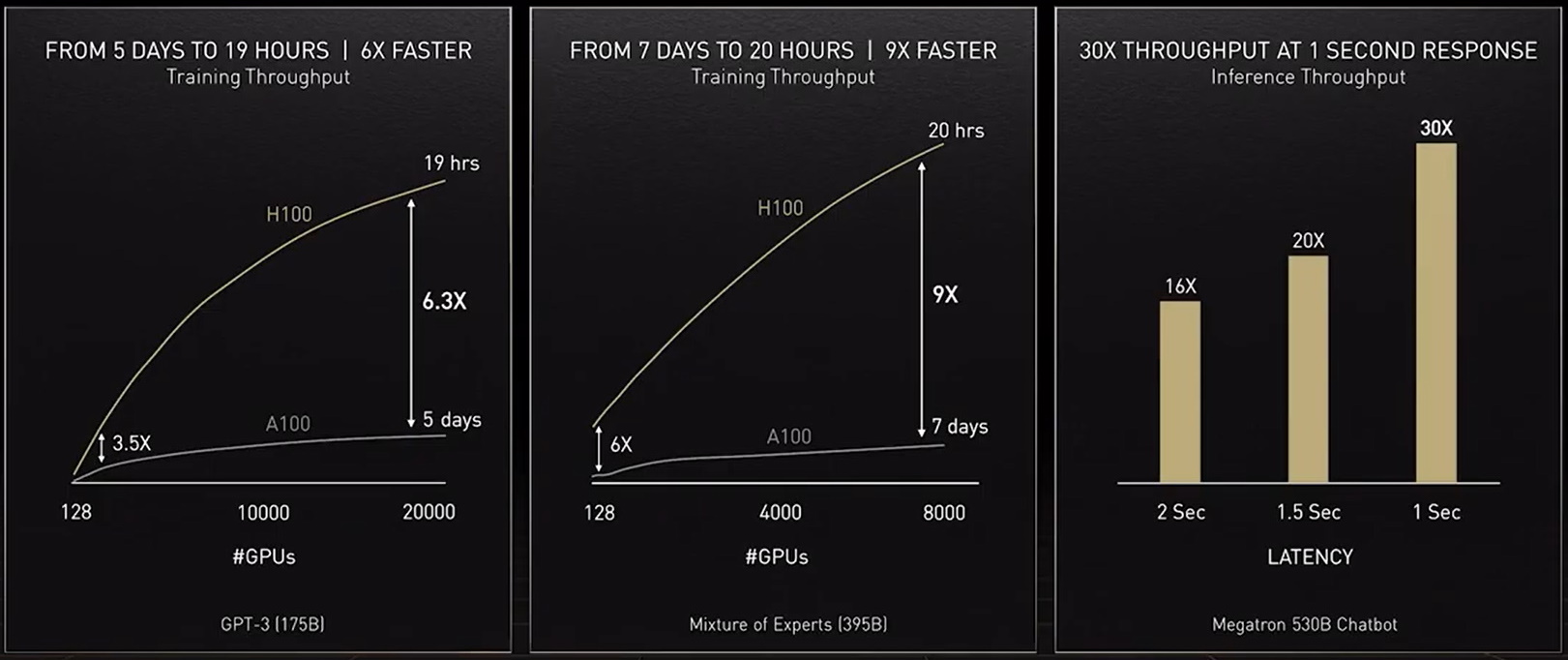
Para proporcionar la potencia de computación que esos modelos necesitan, nuestro acelerador más reciente, la GPU NVIDIA H100 Tensor Core, incluye un engine de Transformer y es compatible con un nuevo formato FP8. Esto acelera el entrenamiento al tiempo que preserva la precisión.
Con esos y otros avances, «el entrenamiento de modelos de transformers se puede reducir de semanas a días», dijo Huang en GTC.
MoE Equivale a Más para los Transformers
El año pasado, los investigadores de Google describieron el Switch Transformer, uno de los primeros modelos de billones de parámetros. Utiliza la baja densidad de IA, una compleja combinación de arquitectura de expertos (MoE) y otros avances para impulsar las ganancias de rendimiento en el procesamiento de idiomas y aumentos de hasta 7 veces en la velocidad de entrenamiento previo.
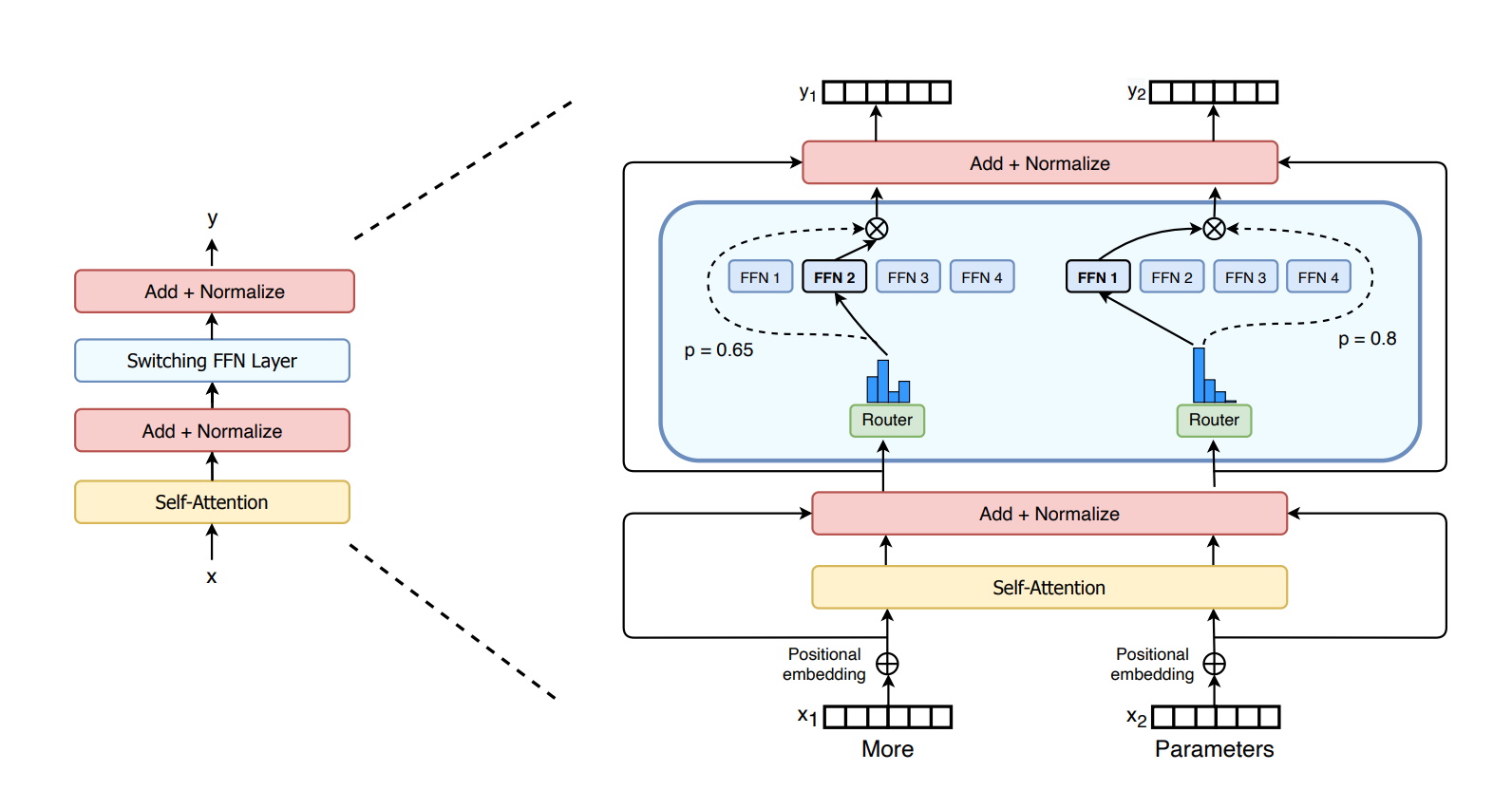
Por su parte, Microsoft Azure trabajó con NVIDIA para implementar un transformer MoE para su servicio de Traducción.
Abordar los Desafíos de Transformers
Ahora, algunos investigadores apuntan a desarrollar transformers más simples con menos parámetros que ofrezcan un rendimiento similar al de los modelos más grandes.
«Veo una promesa en los modelos basados en la recuperación que estoy muy entusiasmado porque podrían aplanar la curva», dijo Gomez, de Cohere, señalando el modelo Retro de DeepMind como ejemplo.
Los modelos basados en recuperación aprenden enviando consultas a una base de datos. «Es genial porque puedes elegir lo que puedes poner en esa base de conocimientos», dijo.
El objetivo final es «hacer que estos modelos aprendan como lo hacen los humanos en contexto en el mundo real con muy pocos datos», dijo Vaswani, ahora cofundador de una startup de IA silenciosa.
Él imagina modelos futuros que hacen más procesamiento por adelantado para que necesiten menos datos y ofrezcan mejores maneras en que los usuarios puedan darles sus comentarios.
«Nuestro objetivo es construir modelos que ayuden a las personas en su vida diaria», dijo de su nueva empresa.
Modelos Seguros y Responsables
Otros investigadores están estudiando formas de eliminar el sesgo o la toxicidad si los modelos amplifican el lenguaje incorrecto o dañino. Por ejemplo, Stanford creó el Centro para la Investigación en Modelos de Base para explorar estos problemas.
«Estos son problemas importantes que deben resolverse para implementar los modelos de forma segura», dijo Shrimai Prabhumoye, un científico investigador de NVIDIA que se encuentra entre muchos de los sectores que trabajan en el área.
«Hoy en día, la mayoría de los modelos buscan ciertas palabras o frases, pero en la vida real estos problemas pueden surgir sutilmente, por lo que tenemos que considerar todo el contexto», agregó Prabhumoye.
«Esa es una preocupación principal para Cohere también», dijo Gomez. «Nadie va a usar estos modelos si lastiman a las personas, por lo que debemos crear los modelos más seguros y responsables».
Más Allá del Horizonte
Vaswani imagina un futuro donde los transformers con aprendizaje propio e impulsados por atención se acercan al Santo Grial de la IA.
«Tenemos la oportunidad de alcanzar algunos de los objetivos que la gente mencionó cuando acuñaron el término «inteligencia artificial general» y me parece que ese futuro es muy inspirador», dijo.
«Estamos en una época en que los métodos simples, como las redes neuronales, nos están brindando una explosión de nuevas capacidades».