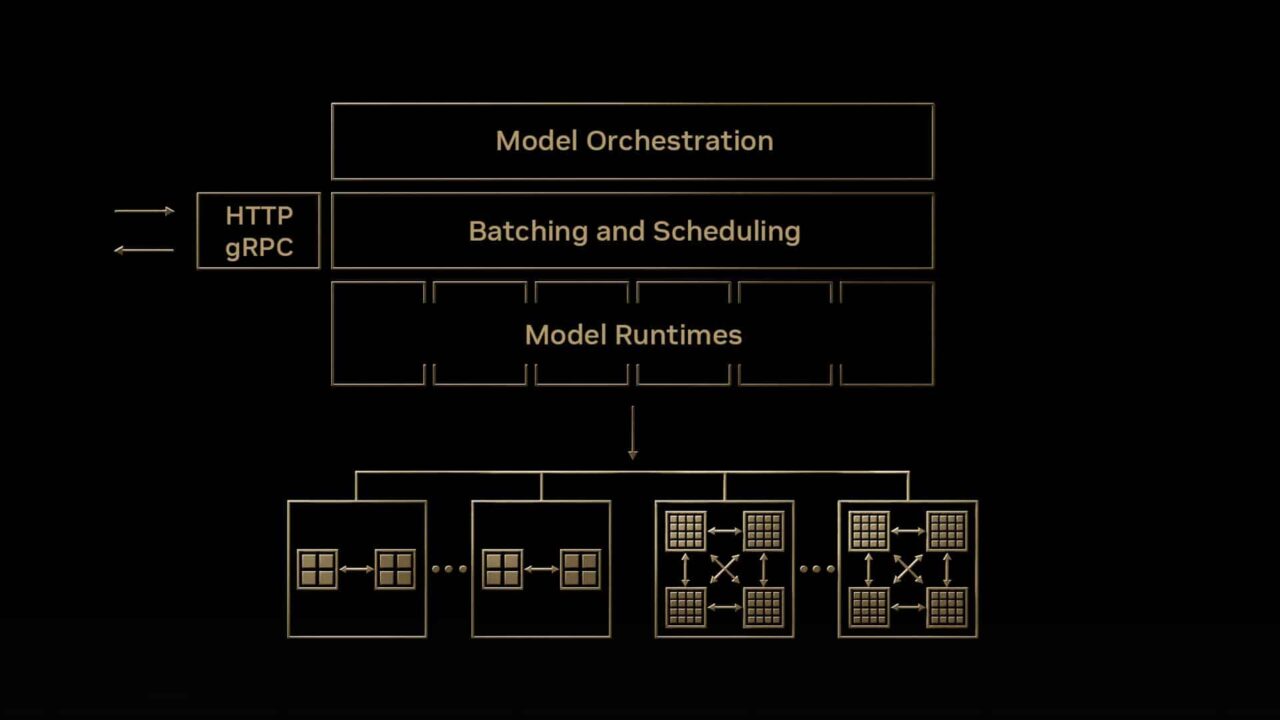
Implementar modelos de IA en producción para cumplir con los requisitos de rendimiento y escalabilidad de la aplicación impulsada por IA mientras se mantienen bajos los costos de infraestructura es una tarea abrumadora.
Esta publicación le brinda una descripción general de los desafíos de inferencia de IA que comúnmente ocurren al implementar modelos en producción, junto con cómo el Servidor de Inferencia NVIDIA Triton se usa hoy en día en todas las industrias para resolver estos casos.
También examinamos algunas de las funciones, herramientas y servicios agregados recientemente en Triton que simplifican la implementación de modelos de IA en producción, con un rendimiento máximo y rentabilidad.
Desafíos a Tener en Cuenta al Implementar la Inferencia de IA
La inferencia de IA es la fase de producción de la ejecución de modelos de IA para hacer predicciones. La inferencia es compleja, pero comprender los factores que afectan la velocidad y el rendimiento de su aplicación lo ayudará a ofrecer una IA rápida y escalable en producción.
Desafíos para Desarrolladores e Ingenieros de ML
- Muchos tipos de modelos: modelos de inteligencia artificial, machine learning y deep learning (basado en redes neuronales) con diferentes arquitecturas y diferentes tamaños.
- Diferentes tipos de consultas de inferencia: en tiempo real, por lotes fuera de línea, streaming de video y audio, y pipelines de modelo hacen que cumplir con los acuerdos de nivel de servicio de la aplicación sea un desafío.
- Modelos en constante evolución: los modelos en producción deben actualizarse continuamente en función de nuevos datos y algoritmos, sin interrupciones comerciales.
Desafíos para los Profesionales de MLOps, TI y DevOps
- Múltiples frameworks de modelos: existen diferentes frameworks de entrenamiento e inferencia como TensorFlow, PyTorch, XGBoost, TensorRT, ONNX o simplemente Python. La implementación y el mantenimiento de cada uno de estos frameworks en producción para aplicaciones puede ser costoso.
- Diversos procesadores: Los modelos se pueden ejecutar en una CPU o GPU. Tener una pila de software separada para cada plataforma de procesador genera una complejidad operativa innecesaria.
- Diversas plataformas de implementación: los modelos se implementan en nubes públicas, data centers locales, en el edge y en dispositivos integrados en una plataforma de machine learning virtual, virtualizada o de terceros. Las soluciones dispares o las soluciones menos que óptimas para adaptarse a la plataforma dada conducen a un retorno de la inversión bajo. Esto puede incluir implementaciones más lentas, un rendimiento deficiente de la aplicación o el uso de más recursos.
Una combinación de estos factores dificulta la implementación de la inferencia de IA en la producción con el rendimiento y la rentabilidad deseados.
Nuevos Casos de Uso de Inferencia de IA con NVIDIA Triton
El Servidor de Inferencia NVIDIA Triton (Triton) es un software de servicio de inferencia de código abierto compatible con todos los frameworks de modelos principales (TensorFlow, PyTorch, TensorRT, XGBoost, ONNX, OpenVINO, Python y otros). Triton se puede utilizar para ejecutar modelos en CPU x86 y Arm, GPU NVIDIA y AWS Inferentia. Aborda las complejidades discutidas anteriormente a través de características estándar.
Triton es utilizado por miles de organizaciones en todas las industrias en todo el mundo. Así es como Triton ayuda a resolver los desafíos de inferencia de IA para algunos clientes.
NIO Autonomous Driving
NIO usa Triton para ejecutar sus modelos de servicios en línea en la nube y el data center. Estos modelos procesan datos de vehículos de conducción autónoma. NIO usó la función de conjunto de modelos de Triton para mover sus funciones de procesamiento previo y posterior de la aplicación cliente al Servidor de Inferencia Triton. El preprocesamiento se aceleró 5 veces, lo que aumentó su rendimiento de inferencia general y les permitió procesar de manera rentable más datos de los vehículos.
GE Healthcare
GE Healthcare usa Triton en su plataforma Edison para estandarizar el servicio de inferencia en diferentes frameworks (TensorFlow, PyTorch, ONNX y TensorRT) para modelos internos. Los modelos se implementan en una variedad de sistemas de hardware, desde integrados (por ejemplo, un sistema de rayos X) hasta servidores locales.
Wealthsimple
La empresa de gestión de inversiones en línea utiliza Triton en las CPU para ejecutar su detección de fraude y otros modelos fintech. Triton los ayudó a consolidar su software de servicio diferente en todas las aplicaciones en un solo estándar para múltiples frameworks.
Tencent
Tencent usa Triton en su plataforma ML centralizada para la inferencia unificada para varias aplicaciones comerciales. En total, Triton les ayuda a procesar 1,5 millones de consultas al día. Tencent logró un bajo costo de inferencia a través de las capacidades de ejecución de modelos simultáneos y procesamiento por lotes dinámico de Triton.
Alibaba Intelligent Connectivity
Alibaba Intelligent Connectivity está desarrollando sistemas de IA para sus aplicaciones de altavoces inteligentes. Usan Triton en el data center para ejecutar modelos que generan transmisión de texto a voz para el altavoz inteligente. Triton entregó la latencia de primer paquete más baja necesaria para una buena experiencia de audio.
Yahoo Japan
Yahoo Japan usa Triton en las CPU del data center para ejecutar modelos para encontrar ubicaciones similares para la funcionalidad de «búsqueda puntual» en la aplicación Yahoo Browser. Triton se utiliza para ejecutar el pipeline completo de búsqueda de imágenes y también está integrado en su plataforma ML centralizada para admitir múltiples frameworks en CPU y GPU.
Airtel
Airtel, el segundo proveedor inalámbrico más grande de la India utiliza Triton para modelos de reconocimiento automático de voz (ASR) para aplicaciones de centro de contacto para mejorar la experiencia del cliente. Triton los ayudó a actualizar a un modelo ASR más preciso y aun así obtener un aumento del rendimiento de 2 veces en las GPU en comparación con la solución de servicio anterior.
Cómo el Servidor de Inferencia Triton Aborda los Desafíos de Inferencia de IA
Desde fintech hasta conducción autónoma, todas las aplicaciones pueden beneficiarse de la funcionalidad lista para usar para implementar modelos en producción fácilmente.
En esta sección, se analizan algunas características, herramientas y servicios nuevos clave que Triton proporciona listos para usar y que se pueden aplicar para implementar, ejecutar y escalar modelos en producción.
Orquestación de Modelos con un Nuevo Servicio de Gestión
Triton trae un nuevo servicio de orquestación de modelos para una inferencia eficiente de múltiples modelos. Esta aplicación de software, actualmente en acceso anticipado, ayuda a simplificar la implementación de instancias de Triton en Kubernetes con muchos modelos de una manera eficiente en recursos. Algunas de las características clave de este servicio incluyen las siguientes:
- Cargando modelos a pedido y descargando modelos cuando no están en uso.
- Asignación eficiente de recursos de GPU mediante la colocación de varios modelos en un solo servidor de GPU siempre que sea posible
- Gestión de requisitos de recursos personalizados para modelos individuales y grupos de modelos
Para ver una breve demostración de este servicio, consulte Take Your AI Inference to the Next Level. La función de orquestación de modelos se encuentra en acceso anticipado privado (EA). Si estás interesado en probarlo, regístrate ahora.
Inferencia de Modelo de Lenguaje Grande
En el área del procesamiento del lenguaje natural (NLP), el tamaño de los modelos está creciendo exponencialmente. Los grandes modelos basados en transformadores con cientos de miles de millones de parámetros pueden resolver muchas tareas de NLP, como el resumen de texto, la generación de código, la traducción o la generación de titulares y anuncios de relaciones públicas.
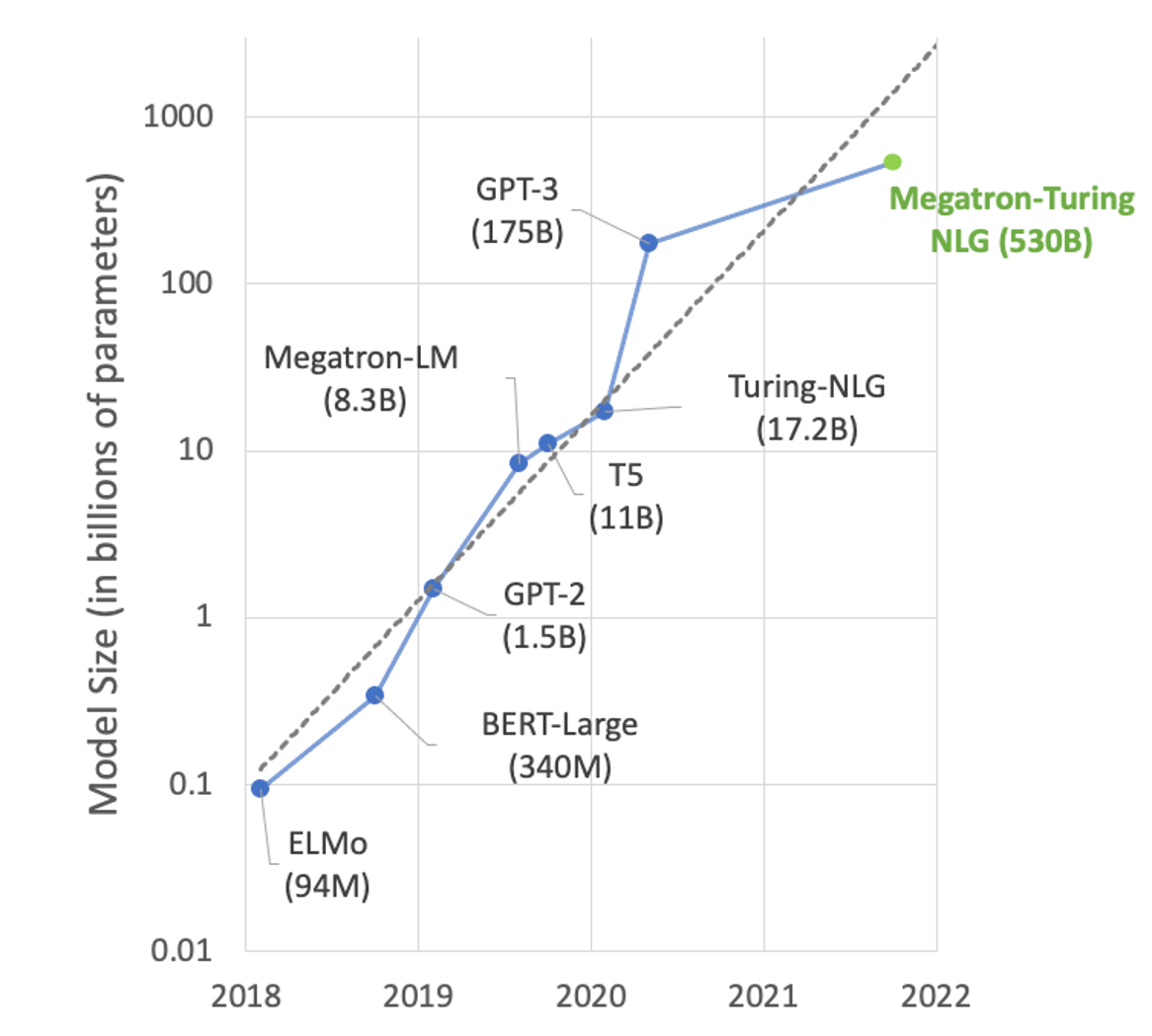
Pero estos modelos son tan grandes que no caben en una sola GPU. Por ejemplo, Turing-NLG con parámetros 17.2B necesita al menos 34 GB de memoria para almacenar pesos y sesgos en FP16 y GPT-3 con parámetros 175B necesita al menos 350 GB. Para usarlos para la inferencia, necesita una ejecución multi-GPU y cada vez más multi-nodo para servir el modelo.
El Servidor de Inferencia Triton tiene un backend llamado FasterTransformer que brinda inferencia de múltiples GPU y múltiples nodos para modelos de transformadores grandes como GPT, T5 y otros. El modelo de lenguaje grande se convierte al formato FasterTransformer con optimizaciones y capacidades de inferencia distribuida y luego se ejecuta utilizando el Servidor de Inferencia Triton en GPU y nodos.
La siguiente figura muestra la aceleración observada con Triton para ejecutar el modelo GPT-J (6B) en una CPU o con una y con dos GPU A100.
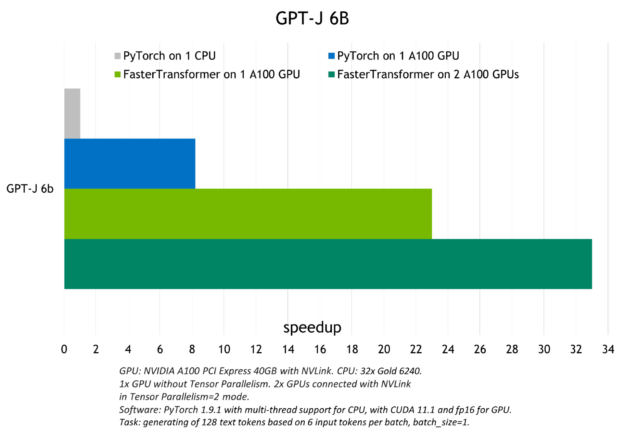
Para obtener más información sobre la inferencia de modelos de lenguaje grande con el backend de Triton FasterTransformer, consulte Accelerated Inference for Large Transformer Models Using NVIDIA Triton Inference Server e Deploying GPT-J and T5 with NVIDIA Triton Inference Server.
Inferencia de Modelos Basados en Árboles
Triton se puede usar para implementar y ejecutar modelos basados en árboles desde frameworks como XGBoost, LightGBM y scikit-learn RandomForest en CPU y GPU con capacidad de explicación mediante valores SHAP. Lo logra utilizando el backend de la Biblioteca de Inferencia Forestal (FIL) que se presentó el año pasado.
La ventaja de usar Triton para la inferencia de modelos basada en árboles es un mejor rendimiento y estandarización de la inferencia en los modelos de machine learning y deep learning. Es especialmente útil para aplicaciones en tiempo real, como la detección de fraudes, donde se pueden usar fácilmente modelos más grandes para una mayor precisión.
Para obtener más información sobre la implementación de un modelo basado en árboles con Triton, consulte Real-time Serving for XGBoost, Scikit-Learn RandomForest, LightGBM, and More. La publicación incluye un cuaderno de detección de fraude.
Pruebe este NVIDIA Launchpad lab to deploy an XGBoost fraud detection model with Triton.
Configuración Óptima del Modelo con Model Analyzer
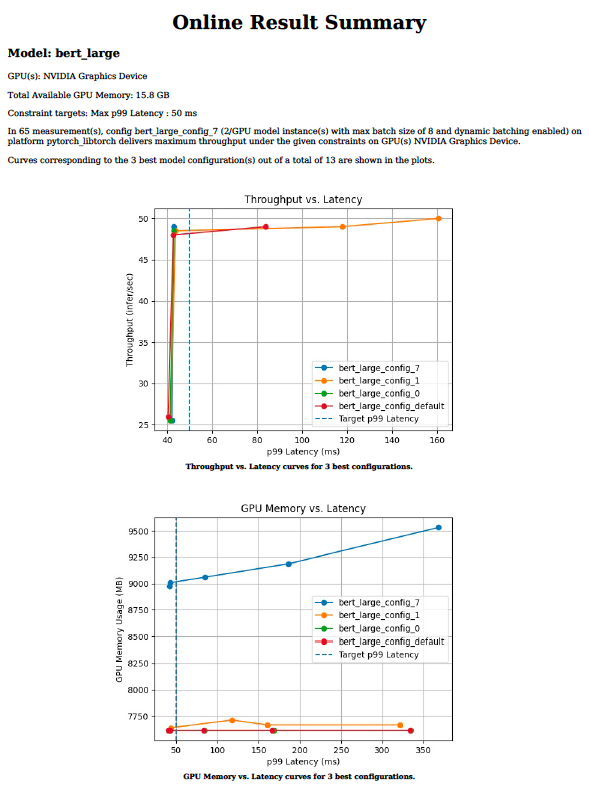
El servicio de inferencia eficiente requiere elegir valores óptimos para parámetros como el tamaño del lote, la concurrencia del modelo o la precisión para un procesador de destino determinado. Estos valores dictan los requisitos de rendimiento, latencia y memoria. Puede tomar semanas probar cientos de combinaciones manualmente en un rango de valores para cada parámetro.
La herramienta de análisis de modelos Triton reduce el tiempo que lleva encontrar los parámetros de configuración óptimos, de semanas a días o incluso horas. Lo hace ejecutando cientos de simulaciones de inferencia con diferentes valores de tamaño de lote y simultaneidad de modelos para un procesador de destino determinado fuera de línea. Al final, proporciona gráficos como el de la Figura 3 que facilitan la elección de la configuración de implementación óptima. Para obtener más información sobre la herramienta de análisis de modelos y cómo usarla para su implementación de inferencia, consulte Identifying the Best AI Model Serving Configurations at Scale con NVIDIA Triton Model Analyzer.
Pipelines de Modelos con Secuencias de Comandos de Lógica Empresarial
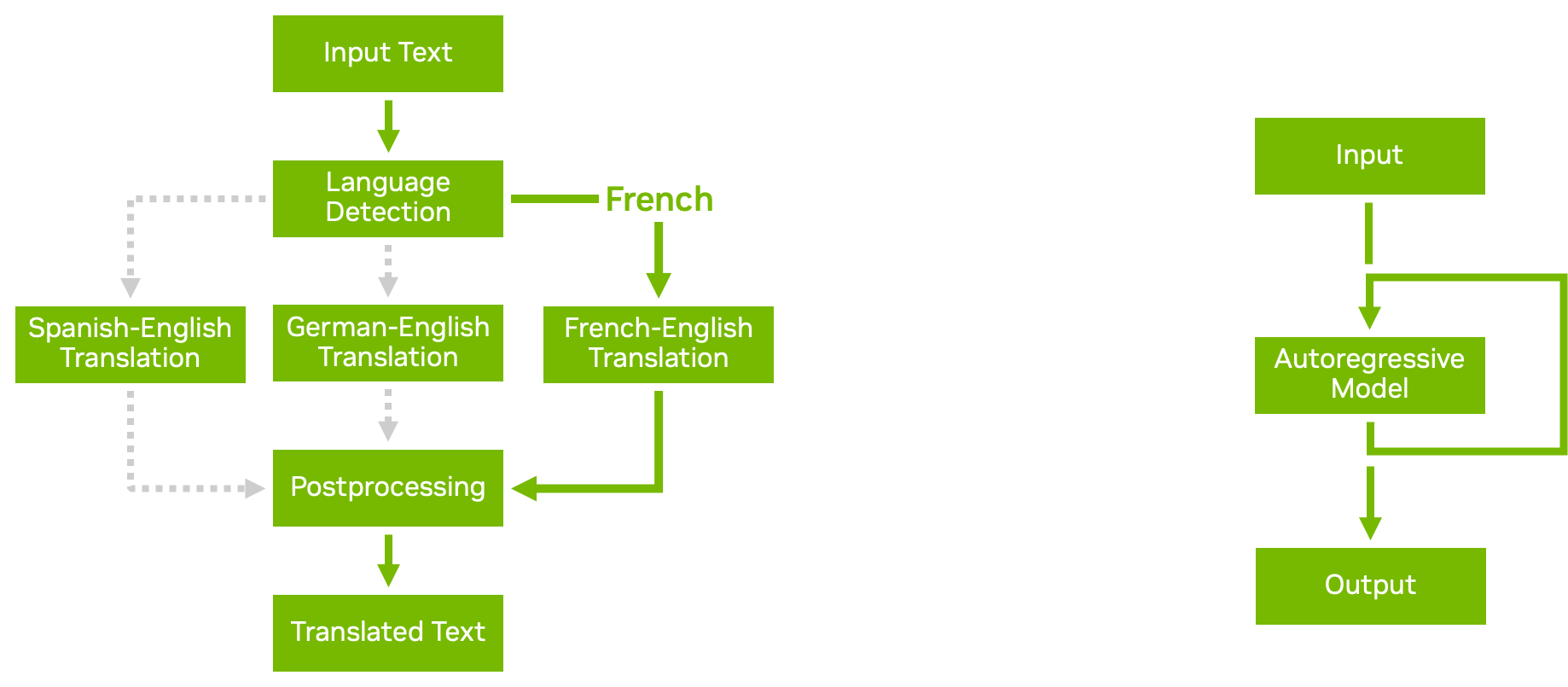
Con la función de conjunto de modelos en Triton, puede crear pipelines y conjuntos de modelos complejos con varios modelos y pasos de procesamiento previo y posterior. Las secuencias de comandos de lógica empresarial le permiten agregar condicionales, bucles y reordenar los pasos en el pipeline.
Con los backends de Python o C++, puede definir un script personalizado que puede llamar a cualquier otro modelo que Triton sirva según las condiciones que elija. Triton pasa datos de manera eficiente al modelo recién llamado, evitando la copia de memoria innecesaria siempre que sea posible. Luego, el resultado se devuelve a su secuencia de comandos personalizada, desde la cual puede continuar con el procesamiento o devolver el resultado.
La figura 4 muestra dos ejemplos de secuencias de comandos de lógica empresarial:
- La ejecución condicional lo ayuda a usar los recursos de manera más eficiente al evitar la ejecución de modelos innecesarios.
- Los modelos autorregresivos, como la decodificación de transformadores, requieren que la salida de un modelo se retroalimente repetidamente hasta que se alcance una determinada condición. Los bucles en las secuencias de comandos de lógica empresarial le permiten lograrlo.
Para obtener más información, consulte Business Logic Scripting.
Autogeneración de la Configuración del Modelo
Triton puede generar automáticamente archivos de configuración para sus modelos para una implementación más rápida. Para los modelos TensorRT, TensorFlow y ONNX, Triton genera los ajustes de configuración mínimos necesarios para ejecutar su modelo de forma predeterminada cuando no detecta un archivo de configuración en el repositorio.
Triton también puede detectar si su modelo admite la inferencia por lotes. Establece max_batch_size en un valor predeterminado configurable.
También puede incluir comandos en sus propios backends personalizados de Python y C++ para generar archivos de configuración del modelo automáticamente en función del contenido del script. Estas características son especialmente útiles cuando tiene muchos modelos para servir, ya que evita el paso de crear manualmente los archivos de configuración. Para obtener más información, consulte Auto-Generated Model Configuration.
Procesamiento de Entrada Desacoplado
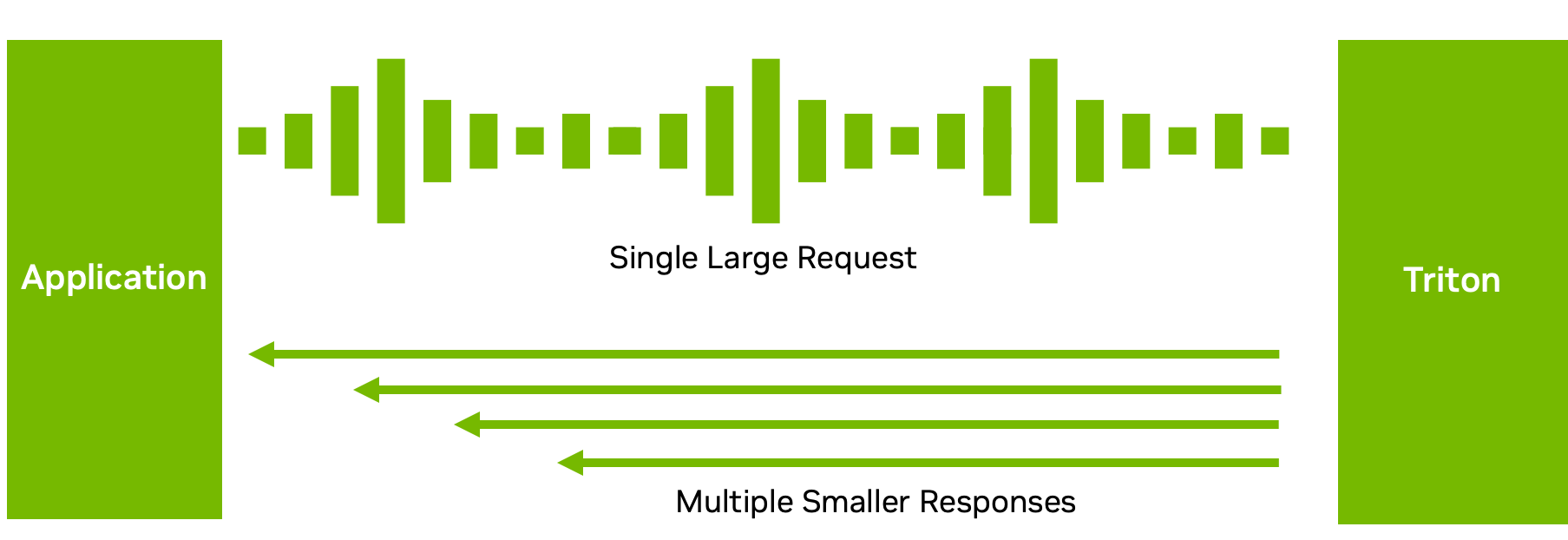
Si bien muchas configuraciones de inferencia requieren una correspondencia uno a uno entre las solicitudes de inferencia y las respuestas, este no siempre es el flujo de datos óptimo.
Por ejemplo, con los modelos ASR, enviar el audio completo y esperar a que el modelo termine de ejecutarse puede no resultar en una buena experiencia para el usuario. La espera puede ser larga. En su lugar, Triton puede devolver el texto transcrito en varios fragmentos cortos, lo que reduce la latencia y el tiempo hasta la primera respuesta.
Con el procesamiento de modelos desacoplados en el backend de C++ o Python, puede enviar múltiples respuestas para una sola solicitud. Por supuesto, también puede hacer lo contrario: enviar múltiples solicitudes pequeñas en fragmentos y obtener una gran respuesta. Esta función brinda flexibilidad en la forma en que procesa y envía sus respuestas de inferencia. Para obtener más información, consulte Decoupled Models.
Para obtener más información sobre las funciones agregadas recientemente, consulte las notas de la versión de NVIDIA Triton.
Comience con la Implementación del Modelo de IA Escalable
Puede implementar, ejecutar y escalar modelos de IA con Triton para mitigar de manera efectiva los desafíos de inferencia de IA que pueda tener con múltiples frameworks, una infraestructura diversa, modelos de lenguaje grandes, configuraciones de modelo óptimas y más.
El Servidor de Inferencia Triton es de código abierto y es compatible con todos los frameworks de modelos principales, como TensorFlow, PyTorch, TensorRT, XGBoost, ONNX, OpenVINO, Python e incluso frameworks personalizados en sistemas GPU y CPU. Explore más formas de integrar Triton con cualquier aplicación, herramienta de implementación y plataforma, en la nube, en las instalaciones y en el edge.
Para obtener más información, consulte los siguientes recursos:
- Comience con NVIDIA Triton y acceda a una variedad de recursos para principiantes y avanzados.
- Descubra las funciones que necesita en una plataforma de inferencia al crear una aplicación de streaming de datos continua o en tiempo real, Fast and Scalable AI Model Deployment with NVIDIA Triton Inference Server.
- Descubra por qué la infraestructura de computación tradicional ya no es suficiente para soportar la IA a gran escala. The secret to rapid and insightful AI–GPU-accelerated computing.
- ¿Busca un laboratorio de habilidades prácticas? Implemente un chatbot de soporte de IA o entrene su propio modelo de IA para la clasificación de imágenes de productos en línea en NVIDIA LaunchPad.