
Los modelos abiertos están impulsando una nueva ola de IA en el dispositivo, extendiendo la innovación más allá de la nube a los dispositivos cotidianos. A medida que estos modelos avanzan, su valor depende cada vez más del acceso al contexto local en tiempo real que puede convertir los conocimientos significativos en acciones.
Diseñadas para este cambio, las últimas incorporaciones de Google a la familia Gemma 4 presentan una clase de modelos pequeños, rápidos y con capacidades omnidireccionales, creados para una ejecución local eficiente en una amplia gama de dispositivos.
Google y NVIDIA han colaborado para optimizar Gemma 4 para las GPUs de NVIDIA, lo que permite un rendimiento eficiente en una amplia gama de sistemas, desde implementaciones en centros de datos hasta PCs y estaciones de trabajo con tecnología NVIDIA RTX, el superordenador de IA personal NVIDIA DGX Spark y los módulos de IA en el borde NVIDIA Jetson Orin Nano.
Gemma 4: modelos compactos optimizados para las GPUs de NVIDIA
Las últimas incorporaciones a la familia de modelos abiertos Gemma 4 —que abarca las variantes E2B, E4B, 26B y 31B— están diseñadas para una implementación eficiente desde dispositivos de borde hasta GPUs de alto rendimiento.
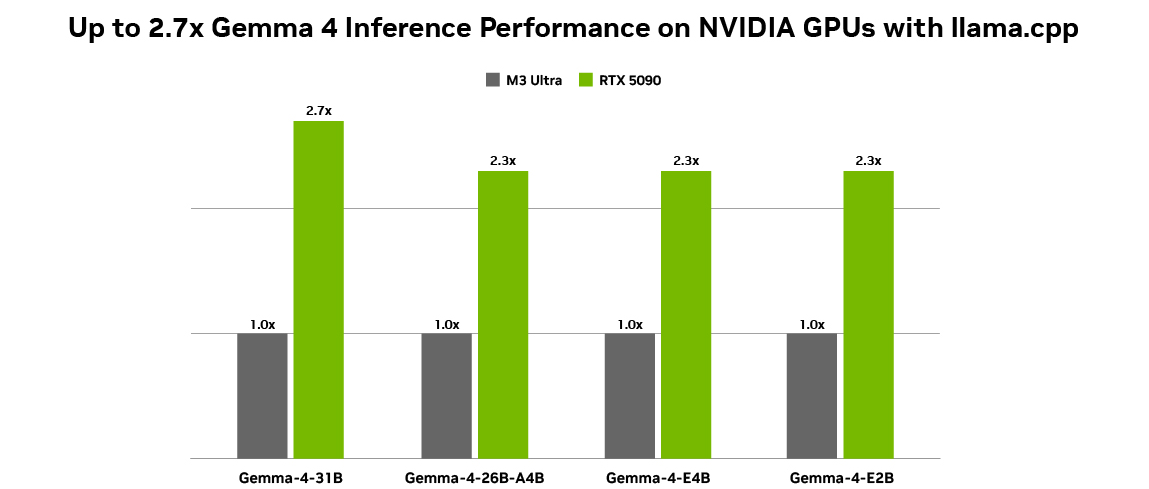
Todas las configuraciones se midieron utilizando cuantificaciones Q4_K_M BS = 1, ISL = 4096 y OSL = 128 en PCs NVIDIA GeForce RTX 5090 y Mac M3 Ultra. El rendimiento de generación de tokens se midió en llama.cpp b7789, utilizando la herramienta llama-bench.
Esta nueva generación de modelos compactos admite una amplia gama de tareas, entre las que se incluyen:
- Razonamiento: gran rendimiento en tareas de resolución de problemas complejos.
- Codificación: generación de código y depuración para flujos de trabajo de desarrolladores.
- Agentes: compatibilidad nativa con el uso de herramientas estructuradas (llamadas a funciones).
- Capacidades de visión, video y audio: Permite interacciones multimodales enriquecidas para el reconocimiento de objetos, el reconocimiento automático de voz y la inteligencia de documentos o videos.
- Entrada multimodal intercalada: Mezcla texto e imágenes en cualquier orden dentro de una sola solicitud.
- Multilingüe: Compatibilidad lista para usar con más de 35 idiomas, pre-entrenada en más de 140 idiomas.
Los modelos E2B y E4B están diseñados para una inferencia ultra eficiente y de baja latencia en el borde, y funcionan completamente sin conexión con una latencia casi nula en muchos dispositivos, incluidos los módulos Jetson Nano.
Los modelos 26B y 31B están diseñados para el razonamiento de alto rendimiento y los flujos de trabajo centrados en el desarrollador, lo que los hace muy adecuados para la IA agentiva. Optimizados para ofrecer un razonamiento accesible y de vanguardia, estos modelos se ejecutan de manera eficiente en las GPUs NVIDIA RTX y DGX Spark, impulsando entornos de desarrollo, asistentes de codificación y flujos de trabajo impulsados por agentes.
A medida que la IA agencial local sigue ganando impulso, aplicaciones como OpenClaw están permitiendo el uso de asistentes de IA siempre activos en PCs RTX, estaciones de trabajo y DGX Spark. Los últimos modelos de Gemma 4 son compatibles con OpenClaw, lo que permite a los usuarios crear agentes locales capaces de extraer contexto de archivos personales, aplicaciones y flujos de trabajo para automatizar tareas. Descubre cómo ejecutar OpenClaw deen o utilizando la guía de OpenClaw para DGX Spark.
Echa un vistazo al blog de anuncios de Google DeepMind para obtener más información sobre las últimas incorporaciones a la familia Gemma 4.
Introducción: Gemma 4 en GPUs RTX y DGX Spark
NVIDIA ha colaborado con Ollama y llama.cpp para ofrecer la mejor experiencia de implementación local para cada uno de los modelos de Gemma 4.
Para utilizar Gemma 4 localmente, los usuarios pueden descargar Ollama para ejecutar los modelos de Gemma 4 o instalar llama.cpp y combinarlo con el punto de control GGUF de Gemma 4 en Hugging Face. Además, Unsloth ofrece soporte desde el primer día con modelos optimizados y cuantificados para un ajuste fino y una implementación locales eficientes a través de Unsloth Studio. Empieza a ejecutar y ajustar Gemma 4 en Unsloth Studio hoy mismo.
La ejecución de modelos abiertos como la familia Gemma 4 en GPUs de NVIDIA logra un rendimiento óptimo, ya que los Tensor Cores de NVIDIA aceleran las cargas de trabajo de inferencia de IA para ofrecer un mayor rendimiento y una menor latencia en la ejecución local. Además, la lista de software CUDA garantiza una amplia compatibilidad con los principales marcos y herramientas, lo que permite que los nuevos modelos se ejecuten de manera eficiente desde el primer día.
Esta combinación permite que modelos abiertos como Gemma 4 se adapten a una amplia gama de sistemas —desde Jetson Orin Nano en el borde hasta PC RTX, estaciones de trabajo y DGX Spark— sin requerir una optimización exhaustiva.
Echa un vistazo al blog técnico de NVIDIA para obtener más detalles sobre cómo empezar a utilizar Gemma 4 en las GPUs de NVIDIA y conocer más sobre el trabajo de NVIDIA en modelos abiertos.
#ICYMI: Las últimas actualizaciones para PCs RTX con IA
Ponte al día con los blogs de RTX AI Garage para conocer una serie de anuncios sobre IA agentica de NVIDIA GTC, como los nuevos modelos abiertos para agentes locales. Estos modelos incluyen NVIDIA Nemotron 3 Nano 4B y Nemotron 3 Super 120B, así como optimizaciones para Qwen 3.5 y Mistral Small 4.
NVIDIA presentó recientemente NVIDIA NemoClaw, una lista de código abierto que optimiza las experiencias de OpenClaw en dispositivos NVIDIA al aumentar la seguridad y admitir modelos locales.
Accomplish.ai ha anunciado Accomplish FREE, una versión gratuita de su agente de IA de código abierto para escritorio con modelos integrados. Aprovecha las GPUs de NVIDIA para ejecutar modelos de peso abierto de forma local, mientras que un enrutador híbrido equilibra dinámicamente las cargas de trabajo entre el hardware RTX local y la nube, lo que permite una ejecución rápida, privada y sin necesidad de configuración, sin requerir una clave de interfaz de programación de aplicaciones.
Conéctate a NVIDIA AI PC en Facebook, Instagram, TikTok y X, y mantente informado suscribiéndote al boletín de RTX AI PC.