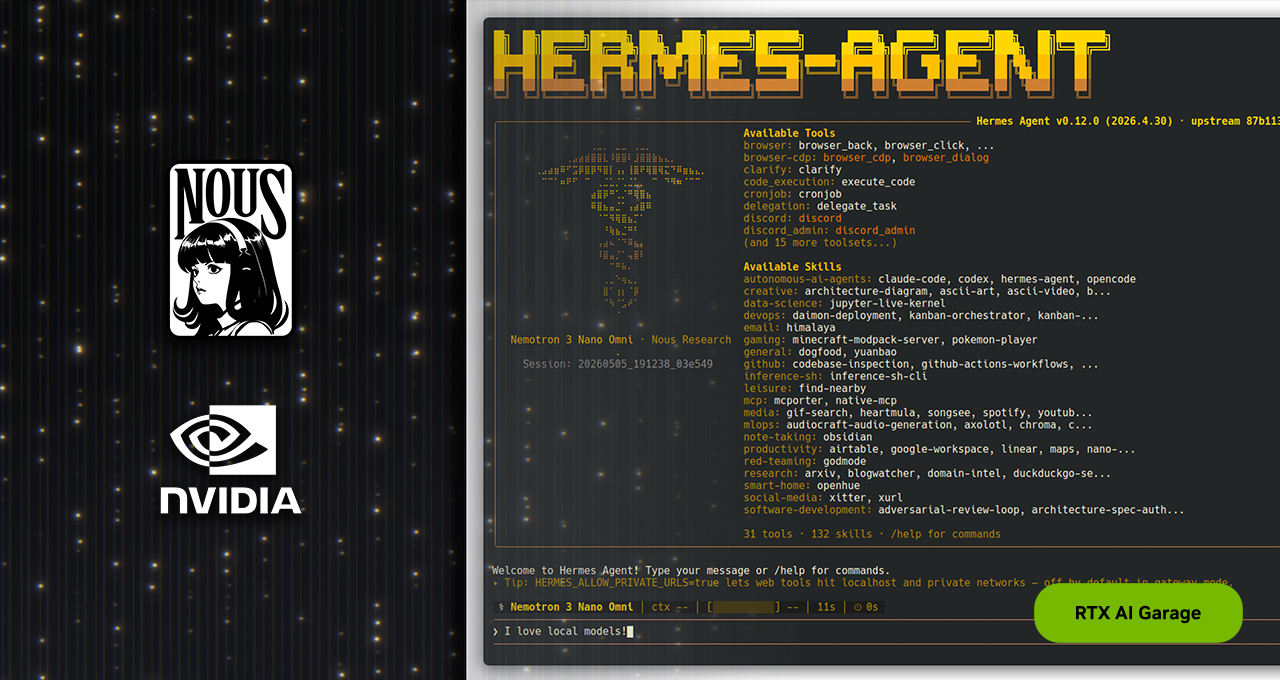
La IA agentica está cambiando la forma en que los usuarios realizan su trabajo. Tras el éxito de OpenClaw, la comunidad está adoptando nuevos marcos de trabajo agenticos de código abierto. El más reciente es Hermes Agent, que superó las 140,000 estrellas en GitHub en menos de tres meses y, según datos de la semana pasada, es el agente más utilizado del mundo según OpenRouter.
Desarrollado por Nous Research, Hermes está diseñado para ofrecer fiabilidad y capacidad de autoaprendizaje, dos cualidades que, históricamente, han sido difíciles de lograr con los agentes. Su diseño es independiente del proveedor y del modelo, y está optimizado para un uso local permanente, lo que convierte a los PC con NVIDIA RTX, las estaciones de trabajo NVIDIA RTX PRO y el NVIDIA DGX Spark en el hardware ideal para ejecutarlo a toda velocidad, las 24 horas del día.
Las Qwen 3.6, una nueva serie de modelos de lenguaje a gran escala (LLM) de alto rendimiento y peso abierto de Alibaba, son ideales para ejecutar agentes locales como Hermes. Los modelos Qwen 3.6 de 27,000 millones y 35 000 millones de parámetros superan en rendimiento a sus homólogos de la generación anterior, de 120,000 millones y 400,000 millones de parámetros, y se ejecutan en NVIDIA RTX y DGX Spark para acelerar la IA agentica.
Hermes: Aceleración de las capacidades de los agentes de IA locales
- Al igual que otros agentes populares, Hermes se integra con aplicaciones de mensajería, puede acceder a archivos y aplicaciones locales, y funciona las 24 horas del día, los 7 días de la semana. Sin embargo, hay cuatro características destacadas que lo diferencian:
- Habilidades que se desarrollan de forma autónoma: Hermes crea y perfecciona sus propias habilidades. Cada vez que el agente se enfrenta a una tarea compleja o recibe comentarios, guarda lo aprendido como una habilidad para poder adaptarse y mejorar con el tiempo.
- Subagentes incluidos: Hermes trata a los subagentes como trabajadores aislados y de corta duración dedicados a una subtarea, con un contexto específico y un conjunto de herramientas concreto. Esto mantiene la organización de las tareas ordenada, minimiza la confusión para el agente y permite que Hermes funcione con ventanas de contexto más pequeñas, lo cual es ideal para modelos locales.
- Fiabilidad desde el diseño: Nous Research selecciona y somete a pruebas de estrés cada habilidad, herramienta y complemento que se incluye en Hermes. El resultado: Hermes simplemente funciona incluso con modelos locales de hasta 30 mil millones de parámetros sin necesidad de la depuración constante que requieren la mayoría de los demás marcos de agentes.
- El mismo modelo, mejores resultados: Las comparaciones realizadas por desarrolladores utilizando modelos idénticos en distintos marcos de trabajo muestran sistemáticamente que Hermes ofrece mejores resultados. La diferencia radica en el marco de trabajo: Hermes es una capa de coordinación activa, no una simple envoltura, que permite el uso de agentes persistentes en el dispositivo en lugar de una ejecución tarea por tarea.
Tanto el agente Hermes como el LLM subyacente están diseñados para ejecutarse localmente, lo que significa que la calidad del hardware determina directamente la calidad de la experiencia del usuario. Las GPUs NVIDIA RTX están diseñadas específicamente para este tipo de carga de trabajo.
Qwen 3.6: Inteligencia a nivel de centro de datos, a escala local
Los últimos modelos de Qwen 3.6 se basan en la aclamada serie Qwen 3.5 para ofrecer un nuevo avance en el campo de los agentes de IA locales. El nuevo modelo Qwen 3.6 35B funciona con aproximadamente 20 GB de memoria, al tiempo que supera a los modelos de más de 120 000 millones de parámetros, que requieren más de 70 GB de memoria.
Además, Qwen 3.6 27B es un nuevo modelo denso con más parámetros activos, que iguala la precisión de modelos de 400 mil millones de parámetros como Qwen 3.5 397B, a pesar de tener un tamaño 16 veces menor. Su ejecución en GPUs RTX de gama alta proporciona al modelo la potencia de cálculo necesaria para ofrecer una experiencia ágil.
Estos modelos son ideales para agentes locales como Hermes, y las GPU de NVIDIA y DGX Spark son la forma más rápida de ejecutarlos. Los Núcleos Tensor de NVIDIA aceleran la inferencia de IA para ofrecer un mayor rendimiento y una menor latencia, lo que permite a Hermes completar una tarea de varios pasos o perfeccionar una de sus propias habilidades en segundos, en lugar de minutos.
DGX Spark: la computadora agentica siempre activa
Los agentes como Hermes están diseñados para funcionar de manera continua: responden a solicitudes, planifican tareas de varios pasos, se ejecutan de forma autónoma y se perfeccionan por sí mismos. NVIDIA DGX Spark es el complemento ideal: una máquina autónoma, compacta y eficiente, diseñada para flujos de trabajo de agentes continuos durante todo el día.
Con 128 GB de memoria unificada y 1 petaflop de rendimiento de IA, NVIDIA DGX Spark puede ejecutar modelos mixture-of-experts de 120 mil millones de parámetros durante todo el día. Además, el nuevo modelo Qwen 3.6 de 35 mil millones de parámetros ofrece una inteligencia equivalente en un espacio más reducido, con un funcionamiento más rápido y la capacidad de ejecutar cargas de trabajo simultáneas.
Para maximizar el rendimiento y la facilidad de uso, lee la guía de Hermes DGX Spark. Además, inscríbete en las próximas sesiones prácticas de la serie de IA agentica “Build It Yourself” de NVIDIA para aprender a crear agentes de IA autónomos con NemoClaw y OpenShell.
NVIDIA DGX Spark ya se puede pedir a los socios fabricantes de NVIDIA — visita el marketplace.
Introducción a Hermes en hardware NVIDIA
Ejecutar Hermes localmente en hardware NVIDIA es muy sencillo.
Visita el repositorio de GitHub de Hermes para empezar, y combínalo con tu modelo y entorno de ejecución locales preferidos. Ejecuta Hermes junto con Qwen 3.6 a través de llama.cpp, LM Studio u Ollama. Hermes Agent incluye compatibilidad integrada con LM Studio y Ollama, lo que ofrece la forma más sencilla de crear un agente local.
Ya sea para un entusiasta local de la IA que explora las fronteras de los agentes personales o para un desarrollador que crea herramientas locales para sus flujos de trabajo, Hermes en hardware de NVIDIA ofrece una base excepcionalmente capaz y confiable.
Está atento a las próximas novedades de RTX AI Garage sobre los últimos modelos y agentes de código abierto optimizados para el hardware NVIDIA RTX.
#ICYMI: Lo último de RTX AI Garage
Las GPUs NVIDIA RTX PRO ofrecen una generación de tokens hasta tres veces más rápida al ejecutar modelos de Qwen 3.6 con llama.cpp. Obtén la capacidad de respuesta en tiempo real necesaria para la IA local, donde los agentes pueden abordar tareas de varios pasos y perfeccionar sus habilidades para garantizar flujos de trabajo fluidos
Los modelos Gemma 4 26B y 31B de Google ya están disponibles como puntos de control NVFP4 para un rendimiento aún más rápido en las GPUs NVIDIA Blackwell. Combina los puntos de control NVFP4 con los nuevos generadores de predicciones multitoken de Google para obtener una inferencia hasta tres veces más rápida con la misma calidad de salida, lo que permite ejecutar razonamientos de vanguardia de forma local en las GPUs NVIDIA.
Mistral Medium versión 3.5, también lanzada en abril, incluye actualizaciones de compatibilidad con llama.cpp y Ollama, lo que permite a los usuarios ejecutarla en sistemas NVIDIA RTX PRO y DGX Spark.
NVIDIA ha presentado recientemente NVIDIA NemoClaw, una tecnología de código abierto que optimiza la experiencia de OpenClaw en dispositivos NVIDIA al mejorar la seguridad y admitir modelos locales. NemoClaw ahora es compatible con el Subsistema de Windows para Linux (WSL2), lo que ofrece soporte a los entusiastas y desarrolladores que utilizan la plataforma de Microsoft. Descubre cómo empezar a usar NemoClaw en DGX Spark con esta guía paso a paso.
Síguenos en NVIDIA AI PC en Facebook, Instagram, TikTok y X, y mantente al día suscribiéndote al boletín de RTX AI PC.